
- 📝Вступ та огляд
- ⏱️Повітряний потік
- 🦆DuckDB
- 🚀Streamlit
- 🎮Конвеєр даних StarCraft II з Airflow, DuckDB та Streamlit
- 💡 Висновок
Вступ та огляд
Цей проект і стаття – не лише джерело для обміну знаннями, а й свято моєї любові до ігор і безмежних можливостей, які несуть у собі дані. Це сплав двох великих пристрастей: ігор та інженерії даних. Я виріс, граючи в StarCraft: Brood War, а також StarCraft II, стратегічну відеогру в реальному часі, де гравці керують однією з трьох унікальних фракцій у міжгалактичній війні, що включає управління ресурсами, будівництво баз і тактичні бої. Я так і не дійшов до гросмейстерських сходинок, де змагаються найсильніші гравці, але я насолоджувався кожним матчем, відчуваючи прилив адреналіну, командуючи арміями, перехитряючи супротивників і здобуваючи перемогу (принаймні, час від часу).
Так само, як у StarCraft я налаштовував замовлення на збірку та пристосовувався до тактики противника, зараз я оптимізую конвеєри даних, аналізую тенденції та візуалізую інсайти як інженер з обробки даних. Я хотів би поділитися знаннями про три корисні технології сучасних стеків даних, а саме:
- ⏱️ Apache Airflow: Платформа для організації та планування складних робочих процесів.
- 🦆 DuckDB: Легка та універсальна аналітична база даних.
- 🚀 Streamlit: Зручний фреймворк для створення інтерактивних веб-додатків.
У цій статті я поясню основи кожної з трьох технологій, а також наведу приклади того, як ви можете використовувати їх у своєму повсякденному бізнесі.
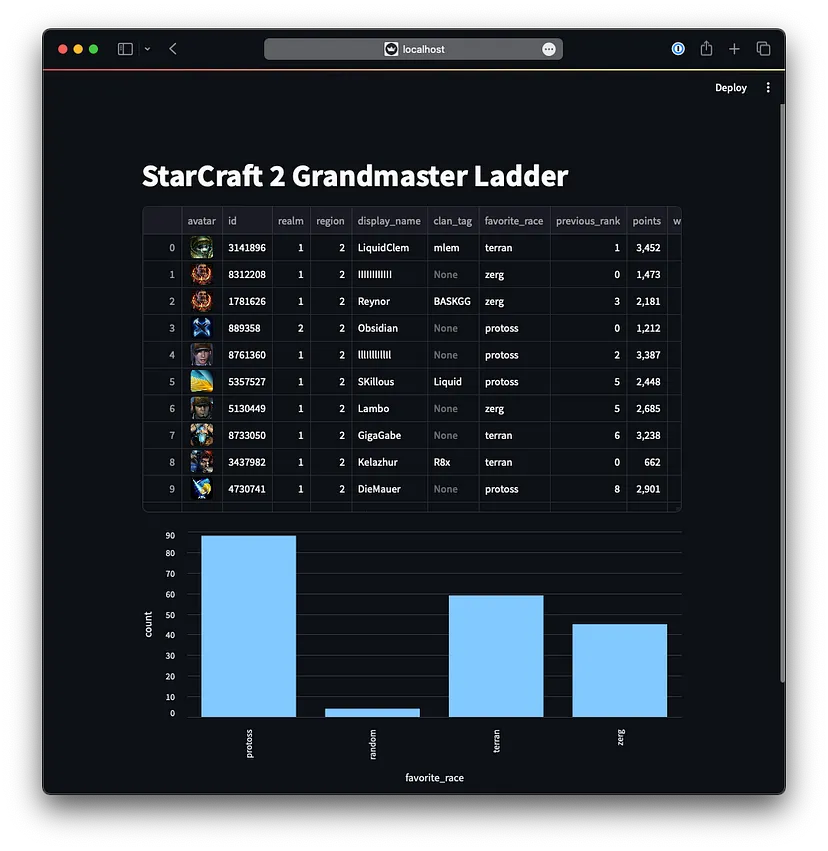
Нарешті, ми створимо приклад проекту, конвеєр даних StarCraft II, де ми отримаємо дані з API StarCraft II і збережемо результати в DuckDB, організованому за допомогою Airflow. Ми також створимо додаток Streamlit для візуалізації даних і подивимося, як виглядає поточна кар’єра гросмейстера в StarCraft II (спойлер: ви не знайдете мене в ній). Це наш кінцевий результат:
Готовий проект можна знайти на Github ♪: https://github.com/vojay-dev/sc2-data-pipeline
Тож хапайте мишку та клавіатуру, викликайте свого внутрішнього командира протосів, зергів чи терранів і приєднуйтесь до мене у цій епічній подорожі через царину даних та ігор.

Airflow (Повітряний потік)
Apache Airflow – це платформа з відкритим вихідним кодом для програмного створення, планування та моніторингу робочих процесів за допомогою Python. Робочі процеси представляються у вигляді орієнтованих ациклічних графів (DAG), кожна вершина яких є одиницею роботи (завданням).
Часто робочі процеси є так званими процесами Extract, Transform, Load (ETL) (або ELT, залежно від того, коли відбувається трансформація), але насправді Airflow настільки гнучкий, що може бути реалізований будь-який тип робочого процесу.

Airflow постачається з веб-інтерфейсом, який дозволяє керувати та контролювати групи DAG. Airflow складається з чотирьох основних компонентів:
- 🌎 Веб-сервер: Обслуговує веб-інтерфейс Airflow.
- ⏱️ Планувальник: Планує запуск груп DAG у визначений час.
- 🗄️ База даних: Зберігає всі метадані груп DAG і завдань.
- 🚀 Виконавець: Виконує окремі завдання.
Коли справа доходить до бази даних і виконавця(executor), Airflow дуже гнучкий. Наприклад, SequentialExecutor можна використовувати для локальної розробки і запускати по одному завданню за раз, в той час як CeleryExecutor або KubernetesExecutor дозволяє паралельне виконання на кластері робочих вузлів.
У цьому проекті ми будемо використовувати Airflow для організації робочого процесу отримання даних з API StarCraft II і збереження їх у DuckDB.
DuckDB

Ласкаво просимо у світ DuckDB! Уявіть, що DuckDB – це ваш надійний помічник у сфері аналізу даних. Легкий, але потужний інструмент, який здатен на багато чого. Уявіть його як спритного розвідника у вашій армії StarCraft, який швидко маневрує через ворожі лінії для збору розвідданих.
У цьому прикладі проекту ми використаємо DuckDB для збереження даних з API StarCraft, а саме даних про сходинки гросмейстерів, у вбудований спосіб, зберігаючи дані в одному файлі за допомогою DuckDB через Python.
Але перш ніж ми зануримося в проект, в наступних розділах ми більш детально познайомимо вас з DuckDB і пояснимо, яку користь ви можете отримати від її використання у вашій повсякденній роботі з інженерії даних / аналітиці.
DuckDB: Ваша портативна аналітична база даних
Уявіть собі DuckDB як швейцарський армійський ніж серед баз даних. Він швидкий, ефективний і універсальний, як протосс-зілот на полі бою, здатний з легкістю адаптуватися до будь-якої ситуації.
DuckDB проста в установці, портативна і з відкритим вихідним кодом. Вона багатофункціональна щодо діалекту SQL, і ви можете імпортувати та експортувати дані на основі різних форматів, таких як CSV, Parquest та JSON. Крім того, він легко інтегрується з фреймами даних Pandas, що робить його потужним інструментом для маніпулювання даними у ваших скриптах обробки даних, які ми розглянемо у наступному розділі.
Ви можете встановити його у свій Python-проект просто за допомогою:
pip install duckdbПісля цього ви можете використовувати DuckDB як базу даних в пам’яті на льоту:
import duckdb
duckdb.execute("CREATE TABLE tbl AS SELECT 42 a")
df = duckdb.execute("SELECT * FROM tbl").df()
print(df) a
0 42Або як вбудована база даних, що зберігає дані у простому файлі:
import duckdb
# create persisted database and write data
with duckdb.connect(database="my_duckdb.db") as write_conn:
write_conn.execute("CREATE TABLE tbl AS SELECT 42 a")
# somewhere else: read and process data
with duckdb.connect(database="my_duckdb.db", read_only=True) as read_conn:
df = read_conn.execute("SELECT * FROM tbl").df()
print(df)Який буде зберігати всі дані у файлі з назвою my_duckdb.db. Ви можете не тільки обмінюватися даними між фреймами даних DuckDB і Pandas, але також читати і записувати CSV, JSON і багато іншого.
Якщо ви знайомі з SQLite, подумайте про DuckDB як про його крутішого, більш орієнтованого на продуктивність брата. Хоча SQLite чудово підходить для невеликих проектів, DuckDB виводить їх на новий рівень. Це все одно, що перейти з базового Terran Hellion на потужний Thor, готовий обробляти більші набори даних і складні запити без зайвих зусиль.
DuckDB також пропонує інтерфейс командного рядка (CLI). DuckDB CLI – це простий виконуваний файл, попередньо скомпільований для Windows, Mac і Linux. У моєму середовищі Mac я міг просто встановити його за допомогою Homebrew:
brew install duckdbВи можете використовувати його для підключення до джерела DuckDB або виконання операцій у пам’яті.

Щоб продемонструвати деякі можливості, я використав його для підключення до файлу бази даних DuckDB, яку ми створимо як частину проекту пізніше, щоб виконати деякий аналіз:
SELECT favorite_race, SUM(wins) AS total_wins, MAX(mmr) AS max_mmr, AVG(mmr) AS avg_mmr
FROM ladder
WHERE favorite_race IN ('protoss', 'terran', 'zerg')
GROUP BY favorite_race
ORDER BY total_wins DESC;┌───────────────┬────────────┬─────────┬───────────────────┐
│ favorite_race │ total_wins │ max_mmr │ avg_mmr │
│ varchar │ int128 │ double │ double │
├───────────────┼────────────┼─────────┼───────────────────┤
│ protoss │ 11816 │ 6840.0 │ 5541.3 │
│ terran │ 7207 │ 7140.0 │ 5501.839285714285 │
│ zerg │ 5380 │ 7080.0 │ 5591.622222222222 │
└───────────────┴────────────┴─────────┴───────────────────┘:- 🥇 Протос має найбільшу загальну кількість перемог, але найнижчий максимальний MMR (Matchmaking Rating) у гросмейстерській кар’єрі.
- 🥈 Терран має найвищий максимальний MMR на гросмейстерській драбині.
- 🥉 Зерги мають найменшу кількість перемог, але найвищий середній MMR на гросмейстерській драбині.
DuckDB: Ваш універсальний інструмент для маніпулювання даними
Працюючи над першими проектами з DuckDB, я швидко зрозумів, що це більше, ніж портативна, легка аналітична база даних. Насправді, вона може стати дійсно потужним інструментом, якщо ви додасте DuckDB до свого набору інструментів для роботи з даними.
За своєю суттю, DuckDB пропонує безшовну інтеграцію між операціями на основі SQL та іншими інструментами обробки даних, такими як Pandas. Ця унікальна функція дозволяє вам легко перемикатися між різними технологіями у ваших скриптах обробки даних.
Замість того, щоб повністю реалізовувати обробку даних на SQL або у вашому скрипті на Python з використанням типових бібліотек, таких як Pandas або NumPy, ви можете перемикатися між цими середовищами без необхідності налаштовувати складну інтеграцію з базами даних.
Ви можете почати отримувати дані з API, завантажити їх у фреймворк даних Pandas, вставити в DuckDB в пам’яті, виконати агрегацію за допомогою SQL, записати результат назад в інший фреймворк даних і продовжити з нього, без особливих накладних витрат. Особливо для інженера даних, який багато працює з SQL, це дало мені потужний інструмент для створення більш інтуїтивно зрозумілих потоків даних.
Як і в StarCraft, ви повинні вибрати правильні юніти для конкретної ситуації. Ви можете створити армію фанатиків, але як тільки ваш опонент атакує з великою кількістю тарганів, ви повинні скоригувати склад своєї армії і додати до неї безсмертних і промені порожнечі. Те ж саме стосується ваших скриптів для обробки даних: додавши такі інструменти, як DuckDB, до загальної композиції, ви зможете впоратися з більшою кількістю викликів при обробці даних.
У наступному прикладі зчитуються дані сходів StarCraft II, які ми заповнимо за допомогою Airflow DAG, використовується SQL для агрегації, результат записується до фрейму даних Pandas, додається деякий стовпець за допомогою Pandas, результат повертається до таблиці в пам’яті DuckDB і виконується подальше перетворення, щоб нарешті повернутися назад до фрейму даних Pandas.
import duckdb
if __name__ == '__main__':
# use persisted duckdb
with duckdb.connect(database="sc2data.db") as conn:
df = conn.sql(f"""
SELECT
favorite_race,
SUM(wins) AS total_wins,
SUM(losses) AS total_losses,
MAX(mmr) AS max_mmr,
AVG(mmr) AS avg_mmr
FROM ladder
WHERE favorite_race IN ('protoss', 'terran', 'zerg')
GROUP BY favorite_race
ORDER BY total_wins DESC;
""").df()
print(df)
# data wrangling in pandas
df["win_pct"] = (df["total_wins"] / (df["total_wins"] + df["total_losses"]) * 100)
# use in-memory duckdb for further processing
duckdb.sql("""
CREATE TABLE aggregation AS
SELECT CASE
WHEN favorite_race = 'protoss' THEN 'p'
WHEN favorite_race = 'terran' THEN 't'
WHEN favorite_race = 'zerg' THEN 'z'
END AS fav_rc,
total_wins + total_losses AS total_games,
win_pct
FROM df;
""")
# back to pandas
df_agg = duckdb.sql("SELECT * FROM aggregation;").df()
print(df_agg)За допомогою вищенаведеного коду та даних про сходинки гросмейстерської драбини API StarCraft II буде згенеровано наступний вивід:
favorite_race total_wins total_losses max_mmr avg_mmr
0 protoss 11816.0 8927.0 6840.0 5541.300000
1 terran 7207.0 5655.0 7140.0 5501.839286
2 zerg 5380.0 3985.0 7080.0 5591.622222
fav_rc total_games win_pct
0 p 20743.0 56.963795
1 t 12862.0 56.033276
2 z 9365.0 57.447944Ми можемо не тільки дізнатися, що Protoss є найвідомішим вибором на гросмейстерських сходах, але й те, що сумісність DuckDB з Pandas відкриває світ можливостей для дослідників даних та аналітиків. Завдяки плавному переходу між можливостями SQL DuckDB і функціями маніпулювання даними Pandas, користувачі можуть використовувати сильні сторони обох платформ, максимізуючи ефективність і гнучкість своїх робочих процесів.

По суті, DuckDB виходить за межі традиційної бази даних, перетворюючись на багатогранний інструмент, який легко інтегрується з іншими технологіями для оптимізації обробки даних.
Незалежно від того, чи ви обробляєте цифри, перетворюєте набори даних або проводите складний аналіз, DuckDB є надійним помічником, пропонуючи зручність SQL разом з універсальністю Pandas та інших бібліотек для ефективної маніпуляції з даними.
Streamlit
Фреймворк додатків Streamlit з відкритим вихідним кодом дозволяє створювати спільні веб-додатки для візуалізації та взаємодії з даними. Ви можете запускати ці додатки локально або безкоштовно розгорнути їх у хмарі Streamlit Community Cloud. Сам Streamlit вже постачається з гарним набором елементів для візуалізації будь-яких даних, проте існує також багато сторонніх модулів (так званих компонентів), які розширюють можливості Streamlit.
Ви можете встановити їх у свій Python-проект просто через:
pip install streamlitПотім ви створюєте свій додаток у спеціальному файлі сценарію і запускаєте його за допомогою команди streamlit run:
streamlit run your_script.py [-- script args]Уявіть свій Python-скрипт як кодове представлення вашого додатку зверху донизу. With:
import streamlit as st
st.title("My Streamlit App")Ви отримуєте веб-додаток з простим заголовком.

Поки що з наступним кодом:
import streamlit as st
st.dataframe(df)Ви можете відобразити фрейм даних як інтерактивну таблицю. Існує набагато більше можливостей для візуалізації даних. Ви побачите один конкретний приклад використання пізніше, коли ми реалізуємо додаток для візуалізації даних StarCraft II, тож залишайтеся з нами і насолоджуйтеся читанням.
Конвеєр даних StarCraft II з Airflow, DuckDB та Streamlit
Основна ідея проекту полягає в тому, що ми отримуємо дані з API StarCraft II. Якщо бути точним, ми отримаємо інформацію про так звану драбину гросмейстерів, щоб побачити, хто є найкращим з найкращих у цій грі на даний момент.
Потім ми збережемо ці дані у файлі DuckDB і організуємо цей процес за допомогою Airflow DAG з використанням API TaskFlow. Нарешті, ми використаємо Streamlit для створення простого додатку.
Остаточний проект також доступний на Github ⏰: https://github.com/vojay-dev/sc2-data-pipeline, але в наступних розділах ми пояснимо, як крок за кроком реалізувати цей конвеєр даних для StarCraft II.
Середовище, в якому я запускаю цю програму, виглядає наступним чином:
- OS: macOS Sonoma
- Python: 3.11.8
Налаштування проекту
Ми починаємо зі створення нового проекту Python. Для цього створюємо нову папку. У цій папці створюємо віртуальне середовище за допомогою вбудованого модуля venv:
mkdir sc2-data-pipeline
cd sc2-data-pipeline
python -m venv .venv
source .venv/bin/activate
Останньою командою ми також активували віртуальне середовище, а це означає, що все, що ви виконуватимете у цьому термінальному сеансі, використовуватиме віртуальний Python, а не загальносистемний Python. Це дуже важливо, оскільки ми хочемо, щоб залежності, які ми встановимо далі, були ізольовані в межах проекту.
Проект використовує Airflow, DuckDB, Streamlit, Pandas і PyArrow, тому наступним кроком буде встановлення всіх необхідних компонентів:
# Install Airflow
AIRFLOW_VERSION=2.8.2
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
# Install DuckDB
pip install duckdb
# Install Pandas and PyArrow
pip install pandas
pip install pyarrow
# Install Streamlit
pip install streamlitЦе займе небагато часу, а це означає, що це гарний момент, щоб випити кави ☕️.

Як бачите, ми використовуємо Airflow 2.8.2. Крім того, ви, можливо, вже задалися питанням, чому ми встановлюємо ці залежності вручну, а не за допомогою Poetry або хоча б файлу requirements.txt. Встановлення Airflow локально працює найстабільніше, а офіційної підтримки Poetry поки що немає, тому для спрощення ми скористаємося ручним підходом.
Підготовка повітряного потоку
Airflow використовує папку airflow на локальному диску для керування деякими своїми даними, наприклад, файлами конфігурації. Зазвичай, вона знаходиться у домашньому каталозі поточного користувача. Однак, щоб уникнути конфлікту з іншими проектами, ми використаємо папку проекту як основу для теки airflow, встановивши змінну оточення AIRFLOW_HOME відповідним чином.
Коли ми вперше запустимо Airflow в автономному режимі, він створить папку у вказаному місці з конфігурацією за замовчуванням. Він буде використовувати SequentialExecutor і SQLite в якості бази даних, зберігаючи файл бази даних в розташуванні AIRFLOW_HOME.
Наступна команда встановить змінну середовища AIRFLOW_HOME на папку з назвою airflow у поточному каталозі (який є каталогом проекту) і запустить Airflow в автономному режимі. Ми також додамо до команди ще одну змінну оточення з назвою NO_PROXY. Це пов’язано з відомою проблемою в macOS, яка викликає SIGSEGV при запуску груп DAG через веб-інтерфейс Airflow.
NO_PROXY="*" AIRFLOW_HOME="$(pwd)/airflow" airflow standaloneЦе не лише запустить Airflow, але й створить теку airflow у каталозі проекту. Також буде автоматично створено користувача адміністратора для веб-інтерфейсу. Ви побачите ім’я користувача і пароль у виведенні журналу.
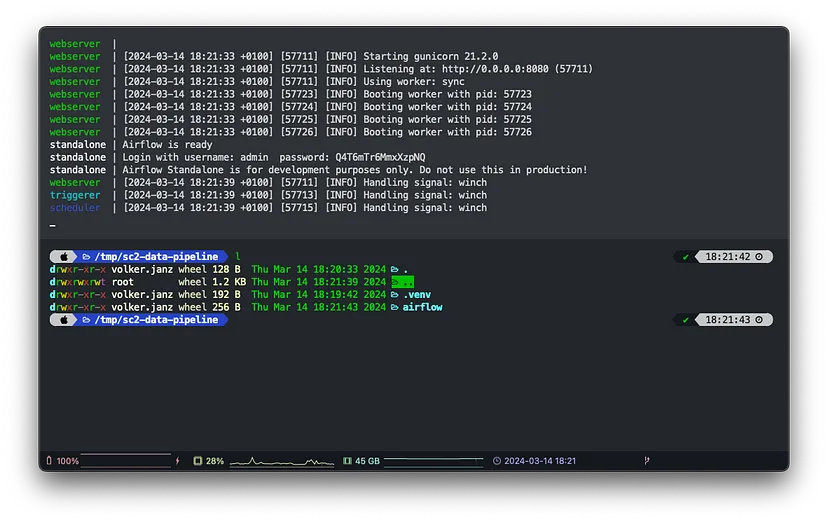
standalone | Airflow is ready
standalone | Login with username: admin password: FZCvvSd8WVYDb2Vm
standalone | Airflow Standalone is for development purposes only. Do not use this in production!Тепер ви можете відкрити http://localhost:8080/ у вашому браузері і увійти, використовуючи облікові дані з виводу журналу.
Вітаємо 🎉, у вас є прагматичне, локальне середовище Airflow. Попередження у веб-інтерфейсі з’являються тому, що ви автоматично використовуєте SequentialExecutor і базу даних SQLite в автономному режимі, тому, звичайно, це не призначено для виробничого використання.
Ви можете зупинити автономний процес за допомогою control+c.
Перш ніж ми почнемо працювати з нашою групою DAG, давайте трохи підготуємо середовище.
Ви могли помітити одну річ: існує безліч прикладів DAG. Особисто мені подобається мати чисте середовище для початку. Ці приклади створюються під час запуску, коли встановлюється певна конфігураційна змінна. Отже, спочатку давайте змінимо цю частину конфігурації.
Оскільки ми встановили змінну AIRFLOW_HOME в папку airflow в папці проекту, розташування конфігураційного файлу буде airflow/airflow.cfg.

Відкрийте конфігурацію у вашому улюбленому редакторі та змініть наступну конфігурацію:
load_examples = FalseНавіть якщо ви перезапустите автономний процес, приклади DAG все одно можуть з’явитися, оскільки вони збереглися у базі даних. Тому нам також потрібно скинути базу даних відповідним чином за допомогою наступної команди (переконайтеся, що ви активували віртуальне середовище і перебуваєте у папці проекту).
NO_PROXY="*" AIRFLOW_HOME="$(pwd)/airflow" airflow db resetПідтвердіть за допомогою y і запустіть середовище знову, тепер у вас буде чистий стан. Це призведе до створення нового користувача адміністратора, але цього разу без прикладів груп DAG.
NO_PROXY="*" AIRFLOW_HOME="$(pwd)/airflow" автономний потік повітря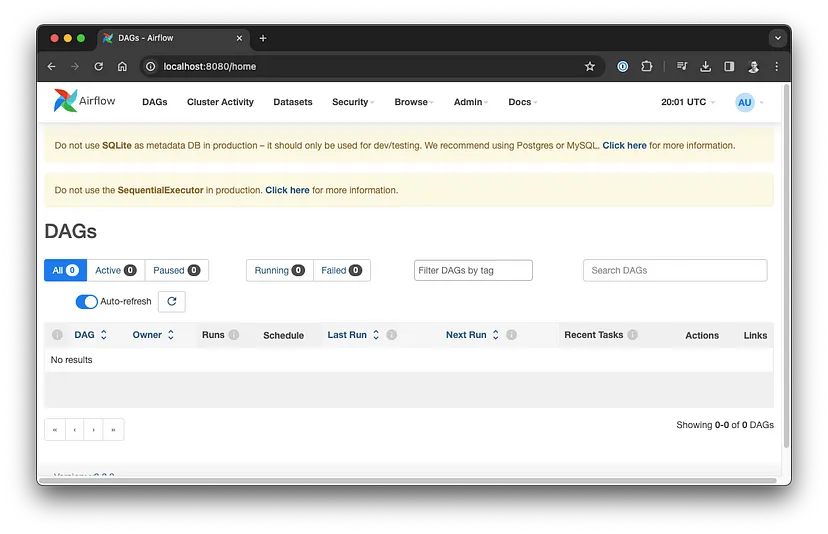
Перш ніж ми створимо нашу DAG, є ще одна річ, яку ми повинні налаштувати. Зазвичай, коли ми фіксуємо наш проект у репозиторії Git, ми не хочемо додавати папку airflow. Перш за все тому, що вона не знаходиться в теці проекту у виробничому середовищі, а також тому, що це наше локальне середовище, і ми хочемо переконатися, що інші розробники можуть налаштувати своє середовище відповідним чином.
Отже, ми додамо airflow/ до файлу .gitignore. Але з таким підходом є проблема: за замовчуванням Airflow шукає групи DAG у папці з назвою dags у папці airflow, тобто: airflow/dags. Якщо ми додамо нашу реалізацію DAG до цієї папки, але проігноруємо папку airflow/ у нашому файлі .gitignore, ми не зможемо зафіксувати наш код у сховищі без обхідних шляхів.
На щастя, рішення полягає у зміні шляху DAGs у конфігурації Airflow. Для цього ми встановимо цю змінну на папку з назвою dags у папці проекту.
Для цього знову відкрийте файл airflow/airflow.cfg і знайдіть змінну dags_folder. Встановіть її так, щоб вона вказувала, наприклад, на папку з назвою dags у папці вашого проекту:
dags_folder = /tmp/sc2-data-pipeline/dagsНарешті, ми створюємо порожню папку dags у нашому проекті, і ми готові до роботи.
mkdir dags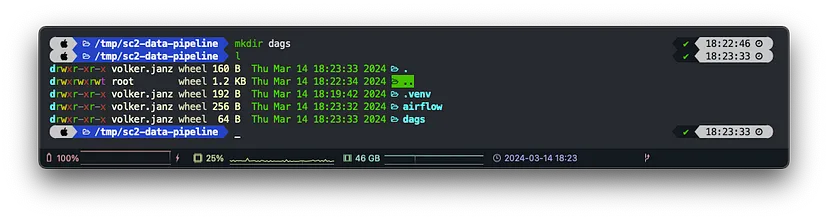
Отримайте доступ до API StarCraft II
API, який ми використовуємо, є частиною API спільноти StarCraft II.

Ліміти досить щедрі: 36000 запитів на годину і 100 запитів на секунду, тому в цьому сценарії ми можемо запускати нашу DAG так часто, як захочемо.
Щоб отримати доступ, вам потрібно створити OAuth-клієнт, що ви можете зробити безкоштовно за допомогою свого облікового запису battle.net. Просто перейдіть на https://develop.battle.net/access/clients, увійдіть під своїм обліковим записом battle.net і створіть клієнт.

Таким чином ви отримаєте:
- ідентифікатор клієнта (client ID)
- клієнтська таємниця (client secret)
Обидва вони потрібні для доступу до API, тому збережіть їх.
Основний процес полягає в тому, що ми спочатку отримуємо токен доступу, використовуючи наш ідентифікатор клієнта і секрет, а потім використовуємо цей токен для отримання даних з API спільноти. Наступний приклад показує, як це зробити за допомогою curl і jq в терміналі. jq можна встановити за допомогою brew install jq.
Приклад отримання токена
curl -s -u your_client_id:your_client_secret -d grant_type=client_credentials https://oauth.battle.net/token | jq .{
"access_token": "super_secret_token",
"token_type": "bearer",
"expires_in": 86399,
"sub": "xxx"
}Приклад отримання даних
curl -s --header "Authorization: Bearer super_secret_token" "https://eu.api.blizzard.com/sc2/ladder/season/2" | jq .{
"seasonId": 58,
"number": 1,
"year": 2024,
"startDate": "1704412800",
"endDate": "1711929600"
}Отримавши ідентифікатор клієнта та секрет, ми можемо реалізувати групу DAG для отримання та збереження даних про сходинки гросмейстерів.
Впроваджуйте DAG
Створіть Python-файл sc2.py в папці dags, це буде реалізація нашої DAG. Додайте наступний код, який, по суті, є реалізацією DAG за допомогою API TaskFlow. Пізніше ми розглянемо деякі деталі:
import logging
import pendulum
import requests
from airflow.decorators import dag, task, task_group
from airflow.models import Variable
from requests.adapters import HTTPAdapter
from urllib3 import Retry
import duckdb
import pandas as pd
logger = logging.getLogger(__name__)
DUCK_DB = "sc2data.db"
CLIENT_ID = "your_client_id"
CLIENT_SECRET = "your_client_secret"
BASE_URI = "https://eu.api.blizzard.com"
REGION_ID = 2 # Europe
# retry strategy for contacting the StarCraft 2 API
MAX_RETRIES = 4
BACKOFF_FACTOR = 2
@dag(start_date=pendulum.now())
def sc2():
retry_strategy = Retry(total=MAX_RETRIES, backoff_factor=BACKOFF_FACTOR)
adapter = HTTPAdapter(max_retries=retry_strategy)
session = requests.Session()
session.mount('https://', adapter)
@task
def get_access_token() -> str:
data = {"grant_type": "client_credentials"}
response = session.post("https://oauth.battle.net/token", data=data, auth=(CLIENT_ID, CLIENT_SECRET))
return response.json()["access_token"]
@task
def get_grandmaster_ladder_data(token: str):
headers = {"Authorization": f"Bearer {token}"}
response = session.get(f"{BASE_URI}/sc2/ladder/grandmaster/{REGION_ID}", headers=headers)
ladder_teams = response.json().get("ladderTeams", [])
return [{
"id": lt["teamMembers"][0]["id"],
"realm": lt["teamMembers"][0]["realm"],
"region": lt["teamMembers"][0]["region"],
"display_name": lt["teamMembers"][0]["displayName"],
"clan_tag": lt["teamMembers"][0]["clanTag"] if "clanTag" in lt["teamMembers"][0] else None,
"favorite_race": lt["teamMembers"][0]["favoriteRace"] if "favoriteRace" in lt["teamMembers"][0] else None,
"previous_rank": lt["previousRank"],
"points": lt["points"],
"wins": lt["wins"],
"losses": lt["losses"],
"mmr": lt["mmr"] if "mmr" in lt else None,
"join_timestamp": lt["joinTimestamp"]
} for lt in ladder_teams if lt["teamMembers"] and len(lt["teamMembers"]) == 1]
def get_profile_metadata(token: str, region: str, realm: int, player_id: int) -> dict:
headers = {"Authorization": f"Bearer {token}"}
response = session.get(f"{BASE_URI}/sc2/metadata/profile/{region}/{realm}/{player_id}", headers=headers)
return response.json() if response.status_code == 200 else None
@task
def enrich_data(token: str, data: list) -> list:
logger.info("Fetching metadata for %d players", len(data))
for i, player in enumerate(data, start=1):
logger.info("Fetching metadata for player %d/%d", i, len(data))
metadata = get_profile_metadata(token, player["region"], player["realm"], player["id"])
player["profile_url"] = metadata.get("profileUrl") if metadata else None
player["avatar_url"] = metadata.get("avatarUrl") if metadata else None
player["name"] = metadata.get("name") if metadata else None
return data
@task
def create_pandas_df(data: list) -> pd.DataFrame:
return pd.DataFrame(data)
@task
def store_data_in_duckdb(ladder_df: pd.DataFrame) -> None:
with duckdb.connect(DUCK_DB) as conn:
conn.sql(f"""
DROP TABLE IF EXISTS ladder;
CREATE TABLE ladder AS
SELECT * FROM ladder_df;
""")
@task_group
def get_data() -> list:
access_token = get_access_token()
ladder_data = get_grandmaster_ladder_data(access_token)
return enrich_data(access_token, ladder_data)
@task_group
def store_data(enriched_data: list) -> None:
df = create_pandas_df(enriched_data)
store_data_in_duckdb(df)
store_data(get_data())
sc2()Основний потік DAG досить простий, він має 2 основні групи завдань, які пов’язані між собою: get_data та store_data.

Зараз ми розглянемо деякі з ключових елементів цих робочих груп.
Отримати дані
Отримання даних відбувається в наступні 3 кроки, кожен з яких виконується як завдання в Airflow:
- 🔐 get_access_token: Отримайте новий токен доступу, використовуючи ваш ідентифікатор клієнта та секрет.
- 📝 get_grandmaster_ladder_data: Отримати останні дані про гросмейстерську драбину з усіма гравцями, які використовують цей токен.
- 👥 enrich_data: Використовуючи іншу кінцеву точку API, ми доповнюємо кожен запис у списку URL-адресою профілю гравця, аватаром та ім’ям.
Замість того, щоб безпосередньо використовувати функції requests.get або requests.post, ми створюємо сесію, яку використовуємо для всіх запитів. Таким чином, ми також можемо визначити стратегію повторної спроби разом зі стратегією відступу. Це рекомендується, якщо ви отримуєте дані із зовнішніх джерел API, оскільки ви не хочете, щоб ваша група DAG вийшла з ладу тільки тому, що API тимчасово недоступний.
MAX_RETRIES = 4
BACKOFF_FACTOR = 2
retry_strategy = Retry(total=MAX_RETRIES, backoff_factor=BACKOFF_FACTOR)
adapter = HTTPAdapter(max_retries=retry_strategy)
session = requests.Session()
session.mount('https://', adapter)Завдяки цьому ми можемо використовувати session в наших завданнях, щоб робити запити, наприклад, для отримання токену доступу:
@task
def get_access_token() -> str:
data = {"grant_type": "client_credentials"}
response = session.post("https://oauth.battle.net/token", data=data, auth=(CLIENT_ID, CLIENT_SECRET))
return response.json()["access_token"]У завданні get_grandmaster_ladder_data ми отримуємо останню версію гросмейстерської таблиці з кінцевої точки https://eu.api.blizzard.com/sc2/ladder/grandmaster/{REGION_ID}, при цьому REGION_ID у нашому випадку дорівнює 2, щоб отримати дані для Європи.
Нарешті, в завданні enrich_data ми викликаємо кінцеву точку https://eu.api.blizzard.com/sc2/metadata/profile/{region}/{realm}/{player_id} для кожного гравця, який є частиною таблиці, і доповнюємо наявний запис про гравця. Виклик самої кінцевої точки інкапсульовано у допоміжній функції get_profile_metadata.
Зберігати дані
Зберігання даних відбувається в наступні 2 етапи, кожен з яких виконується як завдання в Airflow:
- 🐼 create_pandas_df: Створити фреймворк даних Pandas на основі списку гравців.
- 🦆 store_data_in_duckdb: Зберігати фрейм даних у DuckDB, що зберігається у файлі.
Як згадувалося раніше, DuckDB може читати і записувати різні формати, включаючи фрейми даних Pandas. Отже, першим кроком є створення фрейму даних з нашого списку словників, тоді як кожен словник є гравцем на сходах.
@task
def create_pandas_df(data: list) -> pd.DataFrame:
return pd.DataFrame(data)Зберігати цей фреймворк даних в DuckDB напрочуд просто. Ви можете здивуватися, читаючи код вперше, але так: ви можете посилатися на змінну фрейму даних у вашому SQL:
@task
def store_data_in_duckdb(ladder_df: pd.DataFrame) -> None:
with duckdb.connect(DUCK_DB) as conn:
conn.sql(f"""
DROP TABLE IF EXISTS ladder;
CREATE TABLE ladder AS
SELECT * FROM ladder_df;
""")Оскільки ми зберігаємо дані у файлі, ми видаляємо існуючі дані під час кожного запуску, щоб зберігати лише найновішу інформацію. Ми могли б використовувати INSERT або REPLACE, але тоді нам потрібно було б визначити обмеження первинного ключа, що неможливо при безпосередньому створенні таблиці на основі фрейму даних. Але для нашого випадку використання цей підхід є достатнім. У таких випадках я люблю нагадувати людям про принцип KISS:
Не ускладнюй, дурню!
Після збереження даних DAG завершено, і ми можемо перейти до їхньої візуалізації.
Візуалізація даних за допомогою Streamlit
Для нашого додатку Streamlit ми створюємо новий файл у кореневому каталозі проекту: app.py. Ви можете просто додати наступний вміст:
import streamlit as st
st.title("StarCraft 2 Grandmaster Ladder")І запустіть свій додаток через нього:
streamlit run app.pyВи отримаєте просту веб-сторінку із заголовком. Вона буде автоматично оновлюватися, коли ви розширюватимете свій додаток. Тепер давайте замінимо вміст на наш власне додаток, який читає дані з DuckDB і рендерить їх для нас:
import streamlit as st
import duckdb
con = duckdb.connect(database="sc2data.db", read_only=True)
st.title("StarCraft 2 Grandmaster Ladder")
@st.cache_data
def load_ladder_data():
df = con.execute("SELECT * FROM LADDER").df()
# sort by mmr and move avatar to first column
df.sort_values("mmr")
avatar_url = df.pop("avatar_url")
df.insert(0, "avatar", avatar_url)
return df
@st.cache_data
def load_favorite_race_distribution_data():
df = con.execute("""
SELECT favorite_race, COUNT(*) AS count
FROM LADDER
WHERE favorite_race IS NOT NULL
GROUP BY 1
ORDER BY 2 DESC
""").df()
return df
ladder = load_ladder_data()
st.dataframe(ladder, column_config={
"avatar": st.column_config.ImageColumn("avatar")
})
distribution_data = load_favorite_race_distribution_data()
st.bar_chart(distribution_data, x="favorite_race", y="count")Це нарешті візуалізує дані про сходинки гросмейстерів StarCraft II, замовлені MMR, і навіть покаже аватарки гравців:

Реалізація додатку ще раз демонструє гарний приклад того, як можна поєднати фрейми даних Pandas з DuckDB як потужним інструментарієм для роботи з даними:
df = con.execute("SELECT * FROM LADDER").df()
# sort by mmr and move avatar to first column
df.sort_values("mmr")
avatar_url = df.pop("avatar_url")
df.insert(0, "avatar", avatar_url)
return dfВи можете не тільки легко рендерити фрейми даних за допомогою Streamlit, але навіть замінювати певні стовпці, щоб змінити спосіб їх відображення в додатку. У цьому прикладі ми візьмемо URL зі стовпця avatar і відрендеримо його як зображення:
st.dataframe(ladder, column_config={
"avatar": st.column_config.ImageColumn("avatar")
})Нарешті, ми бачимо, що протоси, схоже, є найпомітнішою фракцією на гросмейстерській драбині, що приємно, оскільки я сам колишній гравець за протосів 😉.
Висновок
На завершення, наша подорож по створенню конвеєра даних за допомогою Apache Airflow, Streamlit та DuckDB дала нам неоціненну технічну інформацію про організацію конвеєрів даних та створення інтерактивних додатків для роботи з даними.
DuckDB стала надійним помічником у вирішенні проблем, пов’язаних з обробкою даних, пропонуючи безперешкодну інтеграцію з фреймами даних Pandas та розширені аналітичні можливості SQL. Його легка вага та ефективна продуктивність підкреслили його придатність для аналітичних робочих навантажень в середовищах з обмеженими ресурсами.
Streamlit з його інтуїтивно зрозумілим інтерфейсом і потужними можливостями візуалізації продемонстрував потенціал для швидкої розробки інтерактивних додатків для роботи з даними.
Розмірковуючи над нашим дослідженням цих технологій, ми усвідомлюємо важливість їхньої ролі в сучасних робочих процесах інженерії даних та аналітики. Як гросмейстер у StarCraft II, ретельно плануйте склад своїх юнітів, завжди розширюйте та оптимізуйте свій інструментарій з інженерії даних. До наступного квесту в царстві даних, нехай ваші трубопроводи працюють безперебійно, а перемоги будуть такими ж солодкими, як ідеально влучний постріл Ravager.

ОРИГІНАЛ СТАТТІ:Exploring StarCraft 2 data with Airflow, DuckDB and Streamlit
АВТОР СТАТІ:Volker Janz
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


