Вступ
Ви чули, що блокнотам(notebook) не місце на виробництві(production)? Існує думка, що виробничі(production) ноутбуки(notebook) ніколи не повинні побачити світ. Цей блог має на меті дослідити іншу сторону дискусії, представивши причини, чому використання ноутбуків(notebook) у виробництві(production) є не тільки розумним вибором, але й кращим вибором для багатьох розробників даних(data developers).
У популярних статтях згадуються недоліки використання виробничих ноутбуків(production notebook) і стверджується, що вони підходять лише для спеціальної роботи та демонстрацій. Однак я хотів би зосередитися на цитаті, з якою я повністю згоден, а саме на наступній:
Data scientists не дуже розуміють проблеми професійних розробників програмного забезпечення, такі як автоматизовані, відтворювані та контрольовані збірки, необхідність та процес ретельного тестування, а також важливість гарного дизайну для забезпечення підтримки та гнучкості кодових баз. У свою чергу, багато розробників програмного забезпечення не дуже розуміють, чим займаються Data scientists.
За останнє десятиліття взаємодія між цими двома окремими персонами значно посилилася, насамперед завдяки зростаючому впровадженню рішень машинного навчання(ML). Хоча для інженера-програміста може виникнути спокуса переробити код Data Science, щоб зробити його “готовим до виробництва(production)”, такий підхід не є ефективним для подолання розриву. Замість того, щоб позначати код data scientists як неякісний, більш конструктивним рішенням буде допомогти їм у розробці коду виробничого рівня в блокнотах(notebook), використовуючи їхні улюблені IDE.
Я рекомендую вам ознайомитися з цією статтею на офіційній сторінці блогу Databricks.
Що таке блокнот(notebook) Databricks?
Блокноти(notebook) Databricks – це просто файли на Python з контролем версій. Давайте розглянемо приклад вихідного коду базового блокнота(notebook) Databricks, що зберігається в git-репозиторії, який контролюється версіями у вигляді python-файлу з ім’ям sample_notebook.py:
# Databricks notebook source
# MAGIC %md
# MAGIC # Heading 1 in Markdown
a = 1
b = 2
# COMMAND - - - - -
c = a + b
# COMMAND - - - - -
print(c)Дивлячись на приклад вище, чи можете ви побачити різницю між блокнотом(notebook) і файлом Python, збереженим у сховищі? Очевидно, ви бачите, що вгорі є коментар до джерела # Databricks notebook з # COMMAND-----, що розділяє командні комірки. Тоді ви, можливо, знаєте, що блокноти(notebook) Databricks дозволяють використовувати чарівні команди (magic commands), які дозволяють використовувати різні мови і знижку для додавання документації. У цьому випадку кожен рядок починається з префікса # MAGIC. Зверніть увагу, що оператор # замінюється на відповідні позначення коментарів для обраної мови блокнота за замовчуванням. Нарешті, щоб спростити користувацький досвід, ми інстанціюємо та налаштовуємо загальні вимоги до розробників, такі як SparkSession.
Щоб уточнити моє твердження про те, що блокноти(notebook) мають місце у виробництві(production), важливо зазначити, що я не пропоную ексклюзивне використання блокнотів(notebook) і не стверджую, що вони є найкращим методом розгортання. Ноутбуки(notebook) – це лише один з інструментів в арсеналі виробничих(production) робочих процесів, і вони сприяють швидкій розробці, сприяють відтворюваним високоякісним конвеєрам даних і заохочують код, який легко підтримувати і читати.
Команди даних
Платформа Databricks надає персоналізований інтерфейс користувача з уніфікованим управлінням та обчислювальним механізмом, що дозволяє покращити співпрацю для оптимізації виробничих розгортань(production deployments) . Стабільний успіх ноутбуків(notebooks) протягом останнього десятиліття вивів аналітиків даних на передові позиції в корпоративному програмному забезпеченні. Але питання залишається відкритим: Як щодо ноутбуків(notebooks) для інших розробників даних?
Зазвичай організації мають спеціальну команду інженерів та архітекторів платформи даних, які створюють і підтримують дані, а також забезпечують їхню доступність для різних споживачів. Інженери платформи можуть дотримуватися традиційних практик розробки програмного забезпечення. Команди платформи даних повинні модулювати свій код і дотримуватися найкращих практик розробки програмного забезпечення. Це допомагає зменшити кількість монолітних додатків і роз’єднати основні об’єкти платформи.
З іншого боку, є споживачі даних – особи, які зосереджуються на створенні рішень та вилученні аналітичних інсайтів. Ця група інженерів, науковців та аналітиків зосереджується на створенні відчутної бізнес-цінності за межами доступності даних і зацікавлена в реалізації рішень, а не в тому, щоб забезпечити повну оптимізацію конвеєра. Хоча багато доменних команд дотримуються тих самих практик, що й команда розробників основної платформи, вони часто більше покладаються на SQL, ніж на інші мови. Блокноти(notebooks) мають явну перевагу для робочих процесів на основі SQL над традиційними редакторами SQL.
- Блокноти(notebooks) як точка входу для вашого коду: використання імпорту з Python дозволяє вам модулювати за допомогою інтерактивного інтерфейсу.
- Використовуйте заголовки комірок розмітки та команд: комірки розмітки з заголовками відображатимуться у змісті, що полегшить навігацію до різних частин вашого коду і дасть зрозуміти, що робить кожна секція процесу.
- Розділіть код на багато комірок: Особливо при використанні застарілого SQL, код конвеєра даних може бути нескінченним функціональним скриптом з безліччю загальних табличних виразів. За допомогою комірок Блокнота(notebook) користувачі можуть легко відокремлювати частини коду і використовувати тимчасові подання, щоб зробити його більш керованим, читабельним і зручним для обслуговування.
Користувачі SQL
Кількість SQL-коду, що виконується у виробництві(production), є абсурдною (не в поганому сенсі). Кожна організація, яка обробляє дані, використовує SQL у своїх конвеєрах даних. Як фахівці, що працюють з даними, ми всі або написали, або успадкували збережену процедуру на 5 000 рядків, збережену як єдиний скрипт. Чи є це чудовим способом розгортання виробничого коду? Ні, не дуже. Монолітний SQL-код важко читати, підтримувати та розуміти. Тому, стверджуючи, що блокнотам(production) не місце у виробництві(production), і водночас визнаючи той факт, що ці збережені процедури використовуються у виробництві(production), ми ігноруємо реальність, що не всі інженери здатні слідувати практикам розробки програмного забезпечення. Блокноти(notebooks) надають користувачам інтерактивне і просте середовище розробки, яке сприяє створенню модульного коду, легкому обслуговуванню і співпраці.
Як конкретний приклад, нижче показано, як виглядають деякі збережені процедури. Монолітні збережені процедури SQL можуть дуже швидко перевантажити, а єдиною документацією є вбудовані коментарі до коду, які часто змішуються з випадковою застарілою логікою, яка більше не потрібна, але інженери вирішують коментувати, а не видаляти.
-- This stored procedure contains a series of CTEs that work together, creating a seemingly compact but intricate logic.
CREATE PROCEDURE GetEmployeeData
AS
BEGIN
-- CTE 1: Fetch initial employee details
WITH InitialEmployeeCTE AS (
SELECT EmployeeID, FirstName, LastName, Department
FROM Employees
WHERE IsActive = 1
),
-- CTE 2: Calculate average salary based on initial employee details
AverageSalaryCTE AS (
SELECT AVG(Salary) AS AverageSalary
FROM InitialEmployeeCTE
),
-- CTE 3: Generate a report using average salary
ReportCTE AS (
SELECT 'Employee Report' AS ReportType,
EmployeeID,
FirstName,
LastName,
Department,
AverageSalary
FROM InitialEmployeeCTE
INNER JOIN AverageSalaryCTE
)
-- This CTE is no longer needed as it references an old table
-- instead of just removing, we will just comment it out
-- making it way harder to maintain this sproc
-- CTE 3: Generate a report using average salary
-- ReportCTE AS (
-- SELECT 'Employee Report' AS ReportType,
-- employee_id,
-- first_name,
-- last_name,
-- department,
-- average_salary
-- FROM OLD_TABLE
-- INNER JOIN AverageSalaryCTE
-- )
-- ... Additional CTEs and logic going on for thousands of lines
-- ... An Endless Sea of SQL
-- ... Going on FOREVER....
-- ... Just when you think its about to end, another CTE appears
-- FINALLY! Produce a resultset
SELECT *
FROM FinalDataset;
END;На відміну від того ж скрипту в блокноті(notebook), набагато легше розділяти частини коду і надавати дуже докладні коментарі.
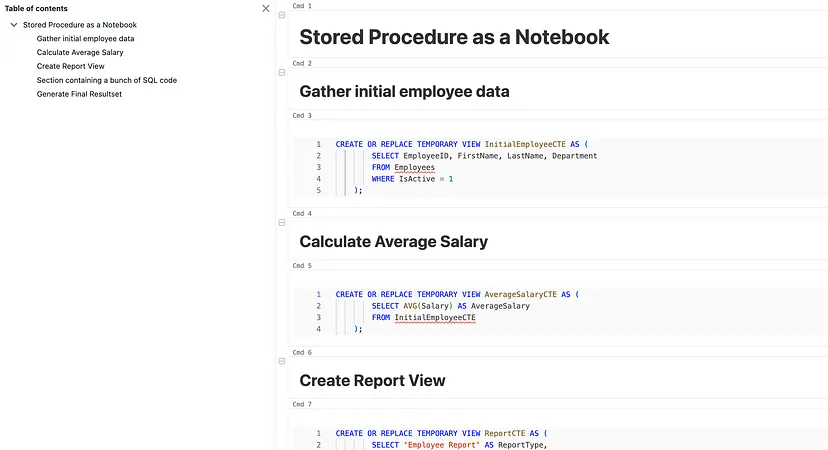
Зверніть увагу, що я перетворив CTE у тимчасові представлення в блокноті(notebook), щоб показати, наскільки організованими і зручними для читання можуть бути блокноти(notebooks) для користувачів SQL. Databricks повністю підтримує використання звичайних табличних виразів. Для отримання додаткової інформації про перетворення збережених процедур в Databricks, перегляньте мій попередній блог.
Нарешті, існуючий SQL-код можна навіть модулювати, використовуючи метод scala/python spark.sql("<insert sql code here>") для обгортання SQL-коду і виконання його з різних класів.
Контраргументи проти поглядів на програмну інженерію щодо ноутбуків(notebooks)
У статті, на яку ми посилалися у вступі, описано конкретні недоліки використання серійних блокнотів(notebooks), щоб підтримати ідею, що вони підходять лише для спеціальної роботи та демо-версій. Зверніть увагу, що в статті не обговорюються конкретно Databricks Notebooks, і вона була написана чотири роки тому, тому, хоча вона могла бути дуже точною в минулому, вона може бути вже не такою зараз. Я також вибираю один пост, але простий пошук в Google покаже вам, що є багато блогів з подібною думкою. Я не стверджую, що блог неправильний, а просто наводжу контраргументи, які збігаються з моїм поглядом на блокноти.
У статті конкретно перераховані наступні проблеми з виробничими ноутбуками (production notebooks):
- Експериментальний код неминуче потрапить у продакшн
- Ноутбуки є ризиком для безпеки, оскільки вони є “повною оболонкою”
- Модуляризація та тестування коду ускладнені
- Керування версіями
- Прихований стан через позачергове виконання
- Параметри
Експериментальний код неминуче потрапляє у виробництво
Це завжди небезпечно, незалежно від того, яку IDE чи мову програмування ви обираєте. Налагодження таких процесів, як перегляд коду, тестування та стандарти кодування, запобігають цьому. Часто організації доручають розробку коду аналітикам даних, а інженери з машинного навчання відповідають за його виробниче розгортання. Тож, хоча якість коду часто залишається за аналітиком даних, інженер машинного навчання відповідає за його готовність до використання у виробництві. Тому, якщо у виробництві з’являється поганий код, не звинувачуйте блокнот чи аналітика даних, а людину, яка схвалила розгортання у виробництві.
Ноутбуки становлять загрозу безпеці, оскільки вони є “повноцінною оболонкою”
Це просто не стосується блокнотів Databricks. Дозволи, з якими виконується код, встановлюються на рівні кластера та користувача. Databricks дозволяє окремим користувачам писати і розгортати код з певними режимами доступу, щоб обмежити типи операцій, які можна виконувати.
Крім того, Databricks виконує контроль доступу через Unity Catalog, щоб гарантувати, що операції з даними відповідають встановленій моделі дозволів, що ще більше посилює безпеку ноутбуків. Це стосується всього коду, який виконується у цьому фреймворку, а не лише блокнотів.
Модуляризація та тестування коду є складним завданням
Я рекомендую розглядати блокноти Databricks як точку входу в додаток. У Databricks користувачі можуть імпортувати бібліотеки з файлів Python для модуляризації та покращення автоматизованого тестування. Наприклад, розглянемо наступний клас Python у файл як приклад.
class import_me():
def __init__(self, a):
self.a = a
def import_print_func(self, str):
print(str)Потім, в блокноті Databricks або в іншому файлі Python, я маю можливість зробити наступне для модуляризації.
# Databricks notebook source
from PythonImports.import_me import import_me
im = import_me('a')
im.import_print_func("Hello! This is how you do python imports using repos!")
# COMMAND ----------Крім того, якщо я захочу виконати тести, я можу діяти за аналогічним шаблоном. Візьмемо клас з назвою simple_math.py, вміст якого показано нижче.
class SimpleMath:
def multiply(self, a, b):
return a * b
def is_even(self, num):
return num % 2 == 0Потім я можу створити ще один файл test_simple_math.py, який міститиме мої тести для попереднього класу. Будь ласка, дивіться нижче.
from simple_math import SimpleMath
def test_multiply():
math = SimpleMath()
result = math.multiply(3, 4)
assert result == 12
def test_is_even():
math = SimpleMath()
assert math.is_even(6) == True
assert math.is_even(7) == FalseПотім у блокноті Databricks я можу запустити наступний код, щоб фактично виконати pytest.
# Databricks notebook source
# MAGIC %pip install pytest
# COMMAND ----------
import pytest
import sys
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["test_simple_math.py", "-v", "-p", "no:cacheprovider"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
# COMMAND ----------Керування версіями
Блокноти Databricks легко інтегруються з git-контролем версій. Вони з’являються як Python-файли в git-репозиторіях, що дозволяє легко відстежувати зміни. Наприклад, ось посилання на блокнот Databricks в одному з моїх особистих репозиторіїв. Крім того, Databricks пропонує рішення з Databricks Repos, що дозволяє контролювати версії для цілих проектів. Ця можливість гарантує, що зміни в блокнотах можна відстежувати, відкочувати за необхідності та ефективно співпрацювати над ними.
Крім того, якщо ви бажаєте розгорнути ваші python-файли та класи у вигляді пакунків та/або коліс, це також повністю підтримується. Просто додайте конвеєр випусків, який створить пакунок на основі гілки випусків, після чого ви зможете встановити бібліотеку на кластер так само, як і будь-яку іншу бібліотеку python. Потім використовуйте блокнот, щоб організувати завдання в рамках вашої роботи.
Прихований стан через позачергове виконання
Поширеною проблемою, пов’язаною з блокнотами, є прихований стан через виконання дій у довільному порядку. Хоча це правда, що окремі користувачі можуть інтерактивно виконувати комірки блокнота в будь-якому порядку, що призводить до несподіваних станів змінних і даних під час розробки, ця проблема не стосується виробничого середовища. Виробничий код автоматизовано, і блокноти слідують моделі послідовного виконання, як звичайний фрагмент коду. Це усуває ризик виникнення прихованих проблем зі станом.
Параметри
Databricks Блокноти можна легко параметризувати та змінювати під час виконання за допомогою віджетів. Крім того, ноутбуки можуть використовувати змінні середовища, які можна встановити під час розгортання. Ця універсальність допомагає зробити Databricks Notebooks придатними для різних виробничих сценаріїв.
Висновок
Зрозуміло, що просування погано написаного і неорганізованого коду до виробництва ніколи не є гарною ідеєю. IDE, в якій було розроблено код, не визначає його якість. Погана якість коду, процеси та комунікація є причиною того, що поганий код потрапляє у виробництво. Як обговорювалося в цій статті, блокноти мають багато переваг, і при правильній практиці використання блокнотів у виробництві може бути життєздатним і ефективним вибором.
Ноутбуки Databricks чудово підходять для точки входу в код і модернізації застарілих конвеєрів SQL. Ноутбуки забезпечують чудове середовище для інтерактивної розробки, налагодження та дозволяють легше керувати виробничими рішеннями.
Редагування – 8 березня 2024: Варто доповнити цей блог приміткою про те, що я писав, що “я не пропоную виключно використання ноутбуків і не стверджую, що вони є найкращим методом розгортання”. Цей блог націлений на аудиторію, яка “ніколи не користується ноутбуками”, щоб показати, що ноутбуки можна і потрібно використовувати. Однак, якщо блокноти не є вашою улюбленою IDE, Databricks пропонує можливість використовувати інші IDE. Наприклад, існує Visual Studio Code Extension та Databricks Asset Bundles, які є чудовими альтернативами. З огляду на це, ноутбуки мають місце у виробництві. Інженери повинні припинити звинувачувати ноутбуки у поганому коді, який вони запускають у виробництво, і самі нести відповідальність за якість коду, впроваджуючи багато з найкращих практик, про які ми говорили тут.
Відмова від відповідальності: це мої власні думки та погляди, а не відображення мого роботодавця
ОРИГІНАЛ СТАТТІ:Using Databricks Notebooks for Production Data Pipelines
АВТОР СТАТІ:Ryan Chynoweth
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


