
Spodbtify - Моделювання даних в dbt за допомогою набору даних Spotify Million Playlist
Протягом наступних тижнів я проведу вас через використання dbt (Database Build Tool) для перетворення набору даних з мільйона плейлистів Spotify в наскрізний аналітичний проект. Ви дізнаєтесь, як перетворити реальні середні, малі та великі необроблені дані (натхненні романом Джорджа Орвелла “Нижній-верхній-середній клас” 😄) в інтерактивну модель даних, за допомогою якої ви зможете досліджувати та знаходити інсайти.
Чого ви навчитеся
- Перетворення 30 ГБ необроблених даних JSON у файл Parquet розміром 5 ГБ для ефективності та масштабованості.
- Перетворення файлу Parquet в декілька dbt-моделей для поглибленого вивчення та аналізу.
- Розуміння того, чому використання dbt є найкращою практикою для процесів трансформації даних.
- Навчіться перевіряти кожну зміну в dbt-моделі, щоб забезпечити цілісність і точність даних (Спойлер: просто використовуйте Recce – інструмент перегляду коду dbt-моделі з відкритим вихідним кодом).
Відповідайте на важливі питання на основі даних
Щотижня я публікуватиму два запитання про набір даних Spotify на сторінці Recce в LinkedIn, наприклад
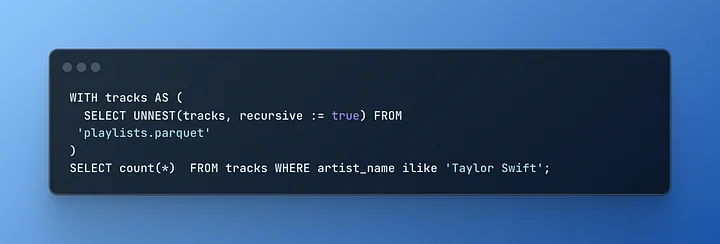
- Скільки плейлистів містять принаймні 3 пісні Тейлор Свіфт?
- Які 10 найпопулярніших пісень Джея Чоу?
- Скільки списків відтворення містять одночасно BLACKPINK 💗 та Post Malone?
Потім я реалізую питання, яке отримає найбільшу кількість голосів у репозиторії з відкритим вихідним кодом.
Для кого це?
Всі, хто зацікавлений у тому, щоб навчитися використовувати dbt для трансформації даних, чи то для бізнес BI, чи то для ML, можуть приєднатися до нас. Крім того, я поділюся деякими найкращими практиками dbt, які будуть корисними для вашої подальшої роботи в якості інженера з даних або аналітики.
Підготовка набору даних про мільйон плейлистів
Готові почати? Добре. Тоді почнемо. Для цього проекту ми будемо використовувати набір даних Spotify Million Playlist Dataset.

” У 2018 році Spotify допоміг організувати RecSys Challenge 2018, дослідницький конкурс з науки про дані, присвячений музичним рекомендаціям… В рамках цього конкурсу Spotify представив The Million Playlist Dataset: набір даних з 1 мільйона плейлистів, що складається з понад 2 мільйонів унікальних треків від майже 300 000 виконавців. ” – Джерело
Завантажити набір даних
Згідно з політикою Spotify, вам потрібно зареєструватися і завантажити вихідні дані звідси. Ми використаємо файл spotify_million_playlist_dataset.zip (це 5,4 ГБ 👀).
Цей архів розширюється до 31 ГБ, тому переконайтеся, що у вас достатньо місця для нього! (Не хвилюйтеся, перетворення на Parquet пізніше зменшить його розмір)

Завантаживши та розпакувавши набір даних, ви побачите, що він організований у тисячу розбитих на розділи JSON-файлів у папці з даними. Ці файли іменуються за наступним шаблоном:
- mpd.slice.0–999.json
- mpd.slice.1000–1999.json
- …
- mpd.slice.999000–999999.json
Типовий приклад запису плейлиста з одного з json-файлів виглядає так:
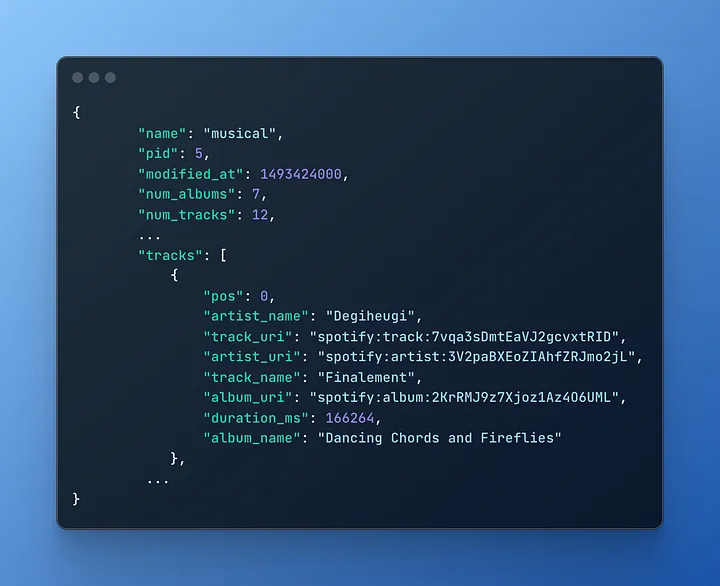
Кожен JSON-файл у наборі даних представляє 1 000 плейлистів, що разом становить 1 мільйон плейлистів. Префікс файлу “mpd” означає “Million Playlist Dataset”.
Команда Spotify надала скрипти в папці ./src, щоб допомогти перевірити цілісність цих JSON-файлів за допомогою контрольних сум MD5, а також обчислити деяку базову статистику за допомогою команди:
$ python src/stats.py dataЯк зазначено в документації README Spotify, результат роботи цієї програми повинен відповідати вмісту файлу stats.txt. Час виконання stats.py може змінюватися, потенційно перевищуючи 30 хвилин, залежно від продуктивності вашого ноутбука.
Попередні висновки
Спочатку ми почнемо з дослідження, щоб отримати попередні уявлення та краще зрозуміти набір даних. Це буде зроблено з сирим json, однак, для більш просунутої взаємодії з даними, необхідно перетворити дані в більш ефективний формат. Для цього ми використаємо Parquet (детальніше нижче), який ідеально підходить для роботи з dbt і перетворення сирих даних.
Перетворення набору даних у Parquet вважається найкращою практикою для оптимізації робочих процесів обробки та аналізу даних.
Давайте відмотаємо назад до початку з 1000 необроблених файлів даних Spotify, і я покажу вам піт і сльози, з якими доводиться стикатися в усіх робочих процесах аналізу даних.
DuckDB з jq
DuckDB та jq – чудові інструменти для взаємодії з даними JSON. Використовуйте ваш улюблений менеджер пакетів для встановлення цих чудових інструментів. Наприклад:
$ brew install duckdb
$ brew install jqРозуміння структури json
Ми можемо використовувати jq для швидкого перегляду JSON-даних, а потім використовувати DuckDB для більш глибокого аналізу. Давайте подивимося на один з 1000 файлів:
$ cd spotify_million_playlist_dataset/data
$ jq 'keys' mpd.slice.0-999.json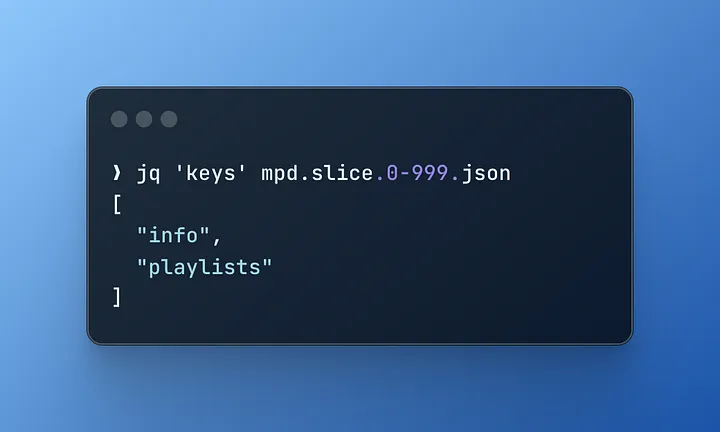
Усі фрагменти JSON містять лише два ключі.
- info – це просто метадані JSON-файлу
- playlists – дані, які нас дійсно хвилюють
Як ви вже здогадалися, “плейлисти” – це масив, тож давайте подивимося на перший елемент плейлиста.
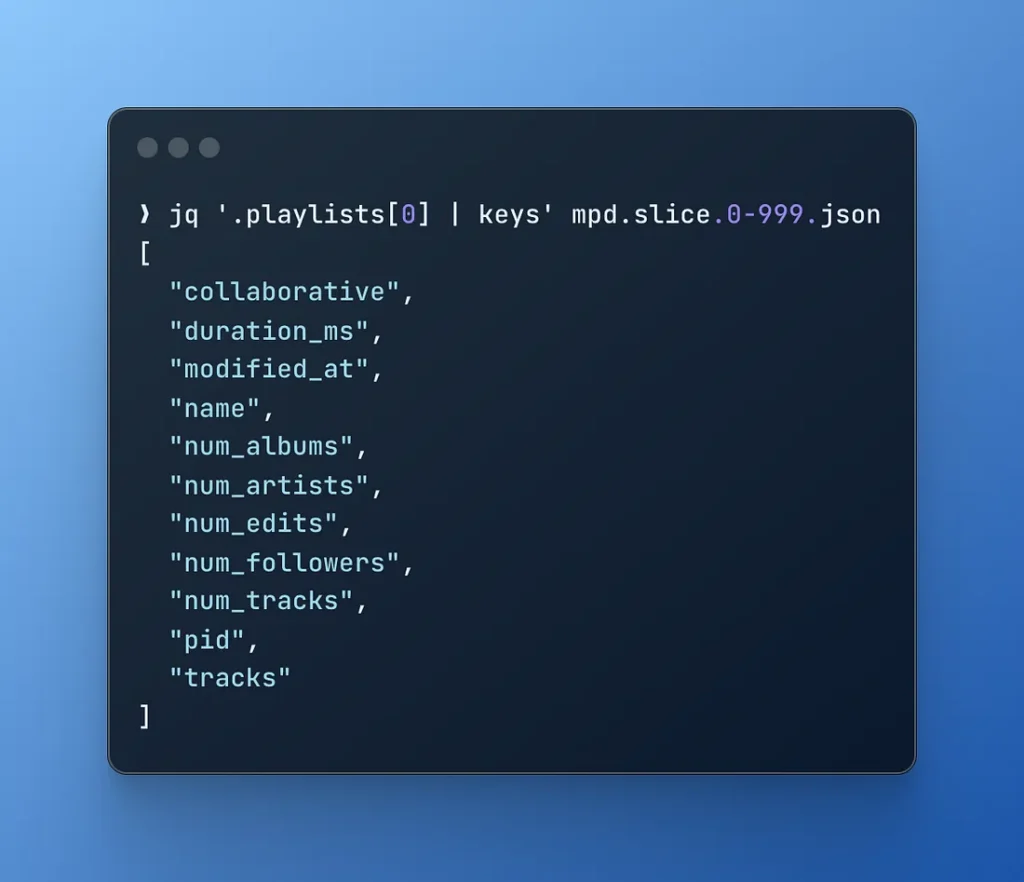
Часткові дані плейлиста (показуючи лише перший трек) виглядатимуть так:
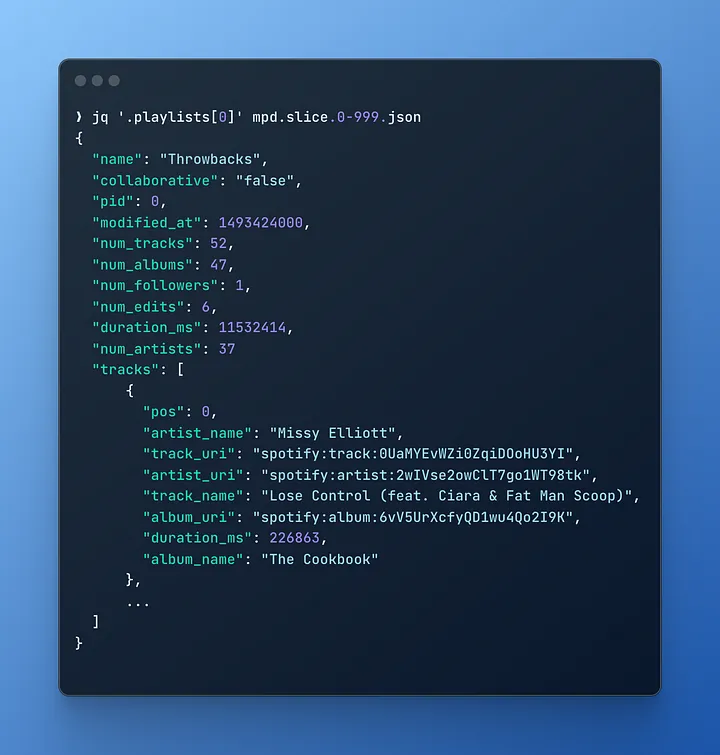
Аналіз за допомогою DuckDB
Після того, як ми отримали загальне уявлення про структуру даних JSON, ми можемо почати аналізувати дані за допомогою DuckDB. DuckDB надає потужні функції, включаючи автоматичне визначення типів даних SQL у вашому JSON-файлі. Це дозволяє вам без зусиль застосовувати синтаксис SQL для аналізу.
Відкрийте інтерактивну оболонку DuckDB
Набравши duckdb у вашому терміналі, ви потрапите до інтерактивної оболонки, подібної до тих, що надаються psql для PostgreSQL та оболонки SQLite.
$ duckdbНалаштуйте максимальний розмір об’єкта DuckDB
Запустіть наступну команду, і ви побачите наведену нижче помилку:
SELECT * FROM read_json_auto('./mpd.slice.0-999.json');
-- Invalid Input Error: "maximum_object_size" of 16777216 bytes exceeded
-- while reading file "./mpd.slice.0-999.json" (>33554428 bytes).
-- Try increasing "maximum_object_size".Ця помилка спричинена тим, що нарізаний JSON набору даних Million Playlist більший за стандартний maximum_object_size DuckDB, тому нам потрібно виправити це, скоригувавши його до 40 МБ 🫰:
SELECT *
FROM read_json_auto('./mpd.slice.0-999.json', maximum_object_size = 40000000);
┌──────────────────────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ info │ playlists │
│ struct(generated_o… │ struct("name" varchar, collaborative varchar, pid bigint, modified_at bjigint, num_tracks bigint, num_albums bigint, num_followers bigint, tracks struct(pos bi… │
├──────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ {'generated_on': 2… │ [{'name': Throwbacks, 'collaborative': false, 'pid': 0, 'modified_at': 1493424000, 'num_tracks': 52, 'num_albums': 47, 'num_followers': 1, 'tracks': [{'pos': … │
└──────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘Розпакуйте json
Ми знаємо, що нас цікавить лише список відтворення, який є вкладеною структурою у стовпцях. Тому ми можемо використати UNNEST для нормалізації стовпчика плейлистів:
SELECT UNNEST(playlists)
FROM read_json_auto('./mpd.slice.0-999.json', maximum_object_size = 40000000)
LIMIT 5;
┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ unnest(playlists) │
│ struct("name" varchar, collaborative varchar, pid bigint, modified_at bigint, num_tracks bigint, num_albums bigint, num_followers bigint, tracks struct(pos bigint, artist_name varch… │
├─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ {'name': Throwbacks, 'collaborative': false, 'pid': 0, 'modified_at': 1493424000, 'num_tracks': 52, 'num_albums': 47, 'num_followers': 1, 'tracks': [{'pos': 0, 'artist_name': Missy … │
│ {'name': Awesome Playlist, 'collaborative': false, 'pid': 1, 'modified_at': 1506556800, 'num_tracks': 39, 'num_albums': 23, 'num_followers': 1, 'tracks': [{'pos': 0, 'artist_name': … │
│ {'name': korean , 'collaborative': false, 'pid': 2, 'modified_at': 1505692800, 'num_tracks': 64, 'num_albums': 51, 'num_followers': 1, 'tracks': [{'pos': 0, 'artist_name': Hoody, 't… │
│ {'name': mat, 'collaborative': false, 'pid': 3, 'modified_at': 1501027200, 'num_tracks': 126, 'num_albums': 107, 'num_followers': 1, 'tracks': [{'pos': 0, 'artist_name': Camille Sai… │
│ {'name': 90s, 'collaborative': false, 'pid': 4, 'modified_at': 1401667200, 'num_tracks': 17, 'num_albums': 16, 'num_followers': 2, 'tracks': [{'pos': 0, 'artist_name': The Smashing … │
└─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘DuckDB надає кілька дуже зручних опцій у функції UNNEST, зокрема ‘recursive := true‘, яка рекурсивно розбиває стовпець на частини:
SELECT UNNEST(playlists , recursive := true )
FROM read_json_auto('./mpd.slice.0-999.json', maximum_object_size = 40000000)
LIMIT 5;
┌──────────────────┬───────────────┬───────┬─────────────┬────────────┬────────────┬───────────────┬────────────────────────────────┬───────────┬─────────────┬─────────────┬─────────────┐
│ name │ collaborative │ pid │ modified_at │ num_tracks │ num_albums │ num_followers │ tracks │ num_edits │ duration_ms │ num_artists │ description │
│ varchar │ varchar │ int64 │ int64 │ int64 │ int64 │ int64 │ struct(pos bigint, artist_na… │ int64 │ int64 │ int64 │ varchar │
├──────────────────┼───────────────┼───────┼─────────────┼────────────┼────────────┼───────────────┼────────────────────────────────┼───────────┼─────────────┼─────────────┼─────────────┤
│ Throwbacks │ false │ 0 │ 1493424000 │ 52 │ 47 │ 1 │ [{'pos': 0, 'artist_name': M… │ 6 │ 11532414 │ 37 │ │
│ Awesome Playlist │ false │ 1 │ 1506556800 │ 39 │ 23 │ 1 │ [{'pos': 0, 'artist_name': S… │ 5 │ 11656470 │ 21 │ │
│ korean │ false │ 2 │ 1505692800 │ 64 │ 51 │ 1 │ [{'pos': 0, 'artist_name': H… │ 18 │ 14039958 │ 31 │ │
│ mat │ false │ 3 │ 1501027200 │ 126 │ 107 │ 1 │ [{'pos': 0, 'artist_name': C… │ 4 │ 28926058 │ 86 │ │
│ 90s │ false │ 4 │ 1401667200 │ 17 │ 16 │ 2 │ [{'pos': 0, 'artist_name': T… │ 7 │ 4335282 │ 16 │ │
└──────────────────┴───────────────┴───────┴─────────────┴────────────┴────────────┴───────────────┴────────────────────────────────┴───────────┴─────────────┴─────────────┴─────────────┘Це дуже зручно для глибоко вкладених даних JSON.
Об’єднайте json в одну таблицю
Наразі ми маємо справу лише з одним файлом JSON. Що, якщо ми хочемо об’єднати всі 1,000 розрізаних JSON-файлів в одну таблицю?
DuckDB надає синтаксис glob, який дозволяє вам читати декілька JSON файлів за один прохід. Просто змініть './mpd.slice.0-999.json' на ‘./mpd.slice*.json’.
CREATE TABLE playlists AS
SELECT UNNEST(playlists , recursive:= true)
FROM read_json_auto('./mpd.slice*.json', maximum_object_size = 40000000);Створення таблиці плейлистів DuckDB на моєму ноутбуці (M3 MacBook) займає 30 секунд. Тепер ми готові конвертувати дані в Parquet.
Перетворити на паркет
Процес перетворення може потребувати деяких тимчасових файлів, щоб уникнути помилки нестачі пам’яті, тому, все ще перебуваючи в оболонці DuckDB, виконайте перший запуск:
SET temp_directory='./tmp';Тепер ви готові експортувати таблицю плейлистів DuckDB у файл Parquet, що також дуже просто. Коли ви використовуєте команду копіювання, вказавши файл з розширенням .parquet, DuckDB автоматично зрозуміє, що ви хочете експортувати його як файл Parquet.
COPY playlist TO 'playlists.parquet' ;Легко, так?
Паркет проти JSON
Отже, чому паркет?

Parquet – це чудовий формат файлів для аналітики, що пропонує значні переваги над JSON завдяки своєму стовпчиковому підходу до зберігання даних. Цей дизайн покращує стиснення і кодування даних, зменшуючи простір для зберігання і прискорюючи доступ до даних для робочих процесів аналізу даних.
Він також підтримує складні вкладені структури даних, пропонуючи гнучку еволюцію схеми, що дозволяє додавати нові стовпці без зміни існуючих даних. Це робить його ідеальним форматом для сценаріїв, в яких часто змінюються схеми з плином часу.
Крім того, сумісність з основними сховищами даних робить Parquet особливо цінним для користувачів баз даних, спрощуючи інтеграцію та аналіз даних. Ви можете легко імпортувати та експортувати файли Parquet з вашого улюбленого сховища даних.
З DuckDB та jq аналіз гігабайтів JSON-даних стає простим на вашому ноутбуці.
Повторюємо “ON – YOUR – LAPTOP” 💻
Підсумок
Початковий набір даних складався з 1,000 JSON-файлів загальним обсягом 31 ГБ.
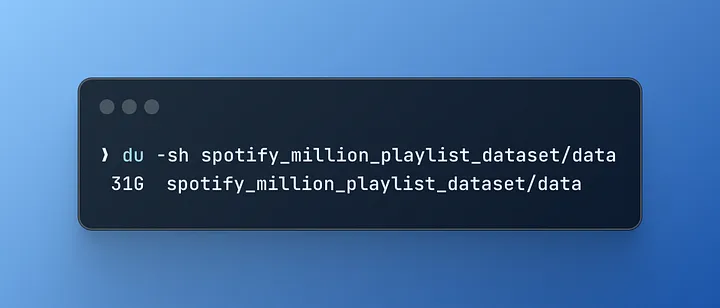
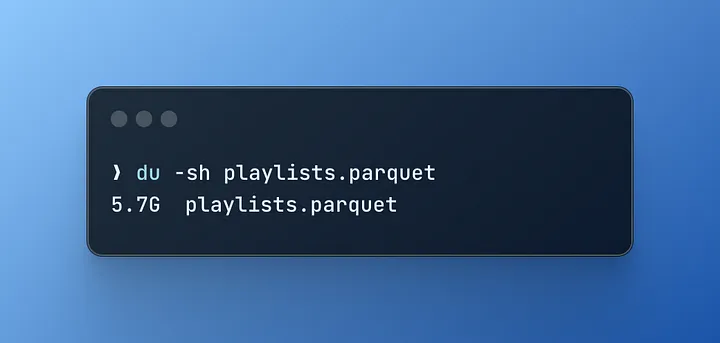
Оригінальний розмір набору даних: Виконавши три простих запити до DuckDB і витративши 1 хвилину на обробку, ви отримаєте один файл Parquet розміром 5,7 ГБ, що означає покращення на 500%.
Тепер ви можете швидко відповісти на питання на кшталт “Скільки пісень Тейлор Свіфт у плейлистах?” за лічені секунди і на своєму ноутбуці, що вражає уяву.
На цьому перша частина цієї статті про аналіз даних закінчена, незабаром читайте другу частину.
Наступного разу …

Після успішного перенесення нашого набору даних у файл Parquet, наступним кроком буде використання можливостей dbt для отримання більш глибоких і переконливих аналітичних висновків з набору даних “Один мільйон плейлистів”.
Застосовуйте найкращі практики програмної інженерії до даних
Хоча оболонка DuckDB пропонує нам можливість інтерактивного аналізу нашого набору даних, стає очевидною потреба у більш структурованому, спільному та контрольованому підході до наших перетворень SQL.
Саме тут dbt сяє 🤩. dbt дозволяє нам розглядати наші перетворення даних як код, що означає, що ми можемо застосовувати такі практики програмної інженерії, як контроль версій, перегляд коду (Recce shines 💖) та автоматизоване тестування до наших робочих процесів з даними.
Спирайтеся на роботу один одного
Організовуючи кілька SQL-запитів у логічні моделі баз даних, ми не тільки підвищуємо чіткість і зручність перетворення даних, але й даємо можливість нашій команді даних ітеративно спиратися на напрацювання один одного. Такий спільний підхід гарантує, що наші моделі даних є надійними, точними та відображають найновішу бізнес-логіку та аналітичні ідеї.
Надійне середовище
Крім того, функції документування dbt дозволяють нам автоматично створювати вичерпну документацію наших моделей даних, що полегшує новим членам команди розуміння ландшафту даних, а зацікавленим сторонам – довіру до наших рішень, заснованих на даних.
Розробка на основі даних
Таким чином, dbt надає нам необхідні інструменти для ефективного управління нашими SQL перетвореннями, сприяючи розвитку спільної та ітеративної культури даних, яка є важливою для того, щоб залишатися конкурентоспроможними в сучасному світі, керованому даними.
До зустрічі в частині 2
Підписуйтесь на нашу сторінку в LinkedIn, щоб бути в курсі останніх подій! 🤩
Оновлення: частина 2 вже доступна. Слідкуйте за моїм прикладом проекту, коли ми розглянемо, чому dbt чудово підходить для моделювання проектів з даними. О, і ми також відповімо на деякі з тих важливих питань про плейлисти Spotify!
Більше статей від In The Pipeline
ОРИГІНАЛ СТАТТІ:From Zero to dbt: How to Analyze and Build Data Models from Spotify’s Million Playlist Data
АВТОР СТАТІ:Douenergy
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X:

