
Під час роботи в різних компаніях я бачив багато архітектур даних. Іноді ці архітектури чудово пристосовані до конкретних бізнес-вимог, а іноді вони не дуже добре підходять, що призводить до дорогих проектів рефакторингу та накладних витрат на міграцію існуючих систем на вдосконалені. Нижче наведено короткий посібник, який допоможе вам приймати обґрунтовані рішення при впровадженні архітектури даних.
- Відмінності між платформою даних, сховищем даних та озером даних
- Загальні компоненти платформи даних
- Розуміння різних типів архітектур платформ даних
- Як вибрати та побудувати правильну архітектуру та компоненти
1. Відмінності між платформою даних, сховищем даних та озером даних
Перш ніж зануритися у світ платформ даних, давайте розрізняти три поняття, які часто плутають: платформа даних, сховище даних та озеро даних.
Data Lake
Data Lake – це сховище, яке містить величезні обсяги необроблених, неструктурованих, напівструктурованих і структурованих даних у їхньому природному форматі. Воно призначене для масштабного зберігання даних з різних джерел, таких як пристрої Інтернету речей, соціальні мережі, веб-журнали, датчики тощо.
Найпростішою аналогією для розуміння datalake є порівняння з папкою Windows: ви можете гнучко зберігати та організовувати різні файли незалежно від їх формату. Озеро даних підтримує широкий спектр типів і форматів даних, включаючи текст, зображення, відео тощо (JSON, XML, CSV, Parquet, Avro, …), забезпечуючи при цьому основу для використання, наприклад, для розширеної аналітики, машинного навчання або більш широких проектів у сфері науки про дані. Наприклад, AWS S3 або хмарне сховище Google (GCS) – це сервіси, які можна використовувати для створення озера даних.
Data Warehouses (Сховища даних)
Сховище даних – це централізоване сховище, яке зберігає структуровані (або напівструктуровані), очищені та оброблені дані з різних джерел. Подібно до того, як бібліотека систематично зберігає та організовує книги для легкого доступу та пошуку, сховище даних організовує структуровані дані з різних джерел у централізованому сховищі.
Дані очищаються, трансформуються та структуруються у визначені формати, що робить їх оптимізованими для аналітичних запитів та звітності, забезпечуючи при цьому високу продуктивність для бізнес-аналітики (BI) та процесів прийняття рішень. Snowflake, Bigquery (GCP) або Redshift (AWS) – це сервіси, які ви можете використовувати для створення свого сховища даних.
Data Platform Платформа даних
Платформа даних слугує уніфікованою системою для ефективного управління та аналізу великих наборів даних. Вона інтегрує такі компоненти, як бази даних, озера даних і сховища даних для обробки структурованих і/або неструктурованих даних залежно від сценаріїв використання.
Ця інфраструктура пропонує інструменти та послуги для різних завдань, пов’язаних з даними, таких як отримання, інтеграція, перетворення, зберігання, обробка, аналіз та візуалізація. Крім того, використовуючи хмарні технології, платформи даних забезпечують масштабованість, гнучкість і економічну ефективність (за умови правильного визначення) всіх операцій з даними компанії.
2. Загальні компоненти платформи даних
Хоча архітектурні особливості платформ даних можуть відрізнятися, вони, як правило, мають спільні фундаментальні шари. Хоча ці шари можуть бути організовані та вкладені по-різному для вирішення конкретних випадків використання (різні потоки даних), вони, як правило, мають однакові базові компоненти:
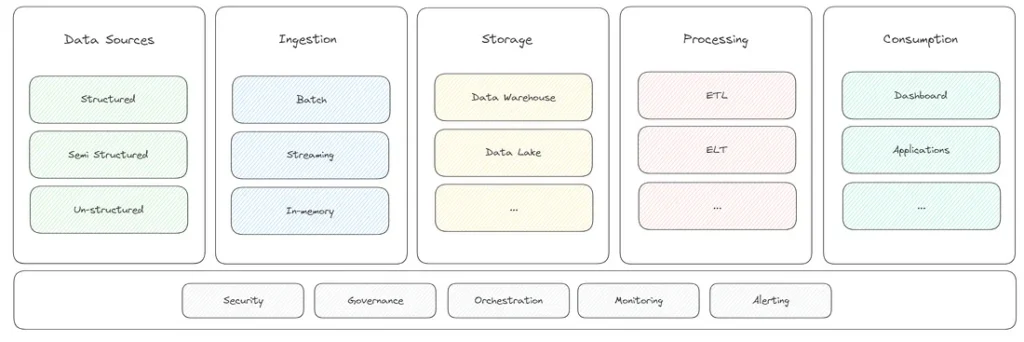
- Джерела даних (Data Source): На цьому рівні ви знайдете всі ваші джерела даних. Вони можуть бути: структурованими, наприклад, дані з вашої ERP, CRM, бази даних клієнтів тощо, напівструктурованими, наприклад, NoSQL, Json, XML тощо, або неструктурованими, наприклад, PDF, зображення, відео, соціальні мережі …
- Поглинання (Ingestion): Платформам даних потрібні механізми для отримання даних з різних джерел даних на рівень зберігання. Це можуть бути методи пакетного поглинання, потокового поглинання (в режимі реального часу) або їх поєднання. Поширені інструменти та технології, що використовуються для отримання даних, включають Apache Kafka, AWS Kinesis або кастомні ETL-процеси.
- Зберігання (Storage): Метою рівня зберігання, як випливає з назви, є зберігання даних, при цьому обробляючи дані різного типу, які надходять з різних джерел. Сховище може включати традиційні реляційні бази даних, розподілені файлові системи, об’єктні сховища або спеціалізовані бази даних, такі як бази даних часових рядів.
- Споживання (Consumption): На цьому рівні надаються механізми для запитів, аналізу та візуалізації даних для отримання інсайтів або прийняття рішень на основі даних. Для аналітики та бізнес-аналітики зазвичай використовуються такі технології, як механізми SQL, інструменти візуалізації даних, такі як Tableau або Power BI, а також фреймворки машинного навчання, такі як TensorFlow або PyTorch.
3. Розуміння різних типів архітектур платформ даних
Архітектура Lambda
Ця архітектура є однією з найбільш універсальних архітектур, оскільки дозволяє виконувати як обробку в реальному часі, так і пакетну обробку. Таким чином, вона дозволяє генерувати різноманітні вихідні дані, що відповідають широкому спектру аналітичних вимог. Зазвичай вона складається з чотирьох рівнів: вхідний, пакетний, швидкісний і рівень подачі.
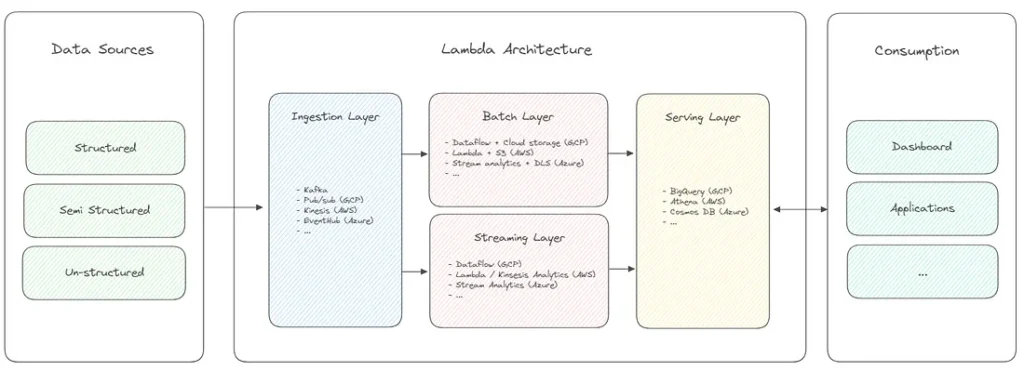
- Рівень прийому: за своєю суттю лямбда-архітектура працює на основі потокової парадигми. Вхідні потоки даних спочатку перехоплюються і зберігаються в надійному механізмі обміну повідомленнями, такому як Apache Kafka.
- Рівень стрімінгу дозволяє проводити аналітику майже в реальному часі, обробляючи дані в міру їх надходження до механізму обміну повідомленнями. Він відповідає за обробку даних у формат, придатний для аналізу, і гарантує, що найсвіжіші дані будуть оперативно доступні для запитів або для аналітичних потреб, чутливих до часу.
- Пакетний рівень легко вміщує історичну аналітику шляхом пакетної обробки збережених потокових даних з механізму обміну повідомленнями на більш пізньому етапі.
- Сервісний рівень виступає в ролі інтерфейсу для кінцевих споживачів. Він забезпечує ефективний доступ до оброблених даних, що надходять як з потоків реального часу, так і з історичної пакетної обробки.
Архітектура Kappa Architecture
Каппа-архітектура – це архітектура обробки даних, яка була представлена як альтернатива лямбда-архітектурі. Вона була розроблена, щоб об’єднати оптимізований підхід до обробки даних у реальному часі та пакетних рівнів, що робить її добре придатною для додатків, які потребують обробки з низькою затримкою та спрощеного управління даними.
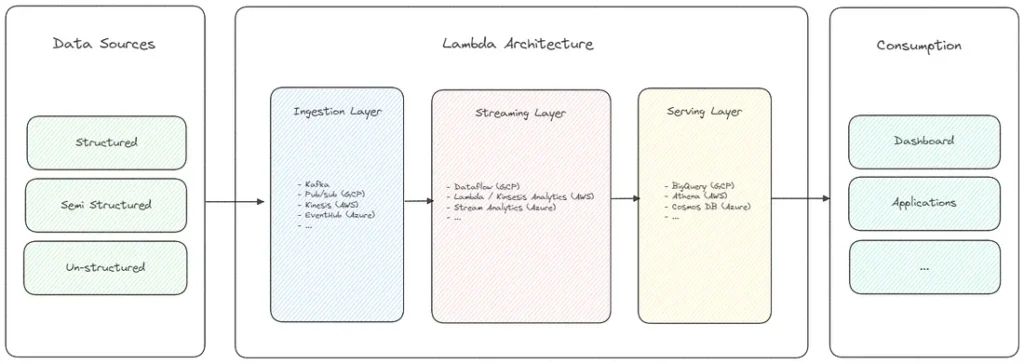
Дані вводяться в систему один раз, а потім обробляються безперервно в режимі реального часу без необхідності зберігати проміжні результати (незмінні потоки даних). Такий підхід усуває складнощі, пов’язані з управлінням декількома рівнями зберігання, і забезпечує послідовність і простоту обробки даних.
Архітектура Data Mesh
Архітектура Data Mesh – це відносно новий підхід до побудови платформ даних. Він спрямований на вирішення проблем масштабованості, гнучкості та володіння даними у великих організаціях.
Замість того, щоб покладатися на централізовану платформу даних, якою керує одна команда, підхід Data Mesh передбачає створення децентралізованої інфраструктури даних. Іншими словами, кожен домен даних відповідає за управління власним продуктом даних, включаючи життєвий цикл даних, отримання, зберігання, обробку та обслуговування.
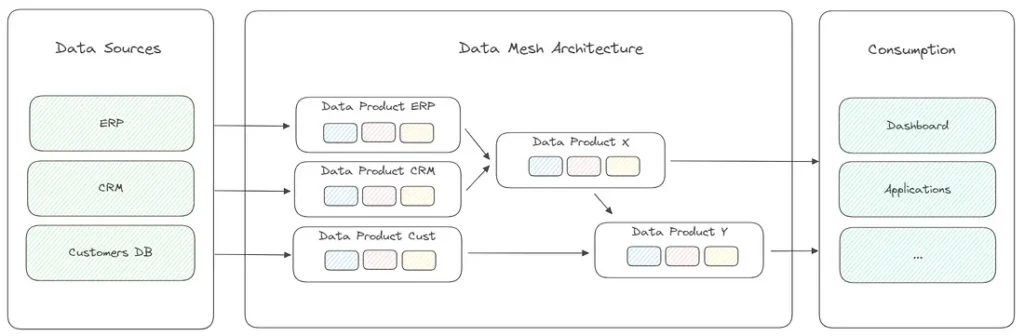
Замість того, щоб мати уніфікований рівень в архітектурі, кожен з рівнів (прийом, обробка, зберігання та обслуговування) інтегрований в продукти даних, орієнтовані на домен, що забезпечує гнучкість у створенні індивідуальних рішень для бізнесу. Більш детально про структуру продукту даних ви можете прочитати в цій статті.
4. Як обрати правильну архітектуру та компоненти для вашого випадку використання
Необхідно відповісти на багато ключових питань, щоб знати, який підхід буде найкращим для потреб бізнесу:
Які конкретні цілі та завдання стратегії роботи з даними?
Визначивши, як платформа даних сприятиме досягненню цих цілей (і, сподіваємось, забезпечить додаткову цінність), ви зможете визначити, які компоненти архітектури потрібні. Наприклад, такі цілі, як підвищення якості продукції або послуг, розширення охоплення і проникнення на ринок або стимулювання інновацій, вимагатимуть різних підходів, оскільки обмеження щодо гнучкості або термінів обробки даних можуть відрізнятися.
Наскільки важлива гнучкість і масштабованість для платформи даних?
Гнучкість і масштабованість є основними міркуваннями для будь-якої платформи даних, оскільки вони впливають на її здатність адаптуватися до мінливих потреб бізнесу і обробляти зростаючі обсяги даних. Це питання впливатиме на багато аспектів вибору архітектури та реалізації, таких як
- Архітектура платформи даних. Хоча архітектури платформ даних, про які йшлося раніше, відрізняються масштабованістю, лямбда- і каппа-архітектури не завжди відповідають вимогам гнучкості через труднощі з реорганізацією або міграцією даних у їхніх структурах. З іншого боку, парадигма сітки даних пропонує гнучкість, надаючи доменам автономію для адаптації своїх конвеєрів даних відповідно до їхніх мінливих бізнес-потреб.
- Вибір між локальними та хмарними рішеннями: хмарні платформи пропонують велику масштабованість, що дозволяє компаніям легко налаштовувати ресурси залежно від попиту, тоді як локальні рішення можуть забезпечити більший контроль, але можуть бути обмежені апаратними обмеженнями.
- Крім того, вибір між безсерверною та забезпеченою архітектурою. Безсерверні архітектури абстрагуються від управління інфраструктурою, дозволяючи масштабувати ресурси автоматично залежно від попиту (добре підходить для непередбачуваних робочих навантажень або додатків зі змінним характером використання). На відміну від них, архітектури з виділеними ресурсами вимагають ручного розподілу ресурсів, що може призвести до проблем з масштабуванням у періоди низького попиту або пікових навантажень. Тому організації, які прагнуть гнучкості та економічної ефективності, можуть віддати перевагу безсерверній архітектурі, тоді як організації з передбачуваними робочими навантаженнями або специфічними вимогами до продуктивності можуть обрати архітектуру з виділеними ресурсами, щоб зберегти більший контроль над розподілом ресурсів та оптимізацією продуктивності.
- Вибір типу бази даних також важливо враховувати, наприклад, рішення між базами даних NoSQL та SQL може суттєво вплинути на масштабованість та гнучкість. Бази даних NoSQL чудово підходять для горизонтального масштабування та універсальності в управлінні неструктурованими даними. На відміну від них, бази даних SQL відмінно справляються із запитами до структурованих даних і підтримують цілісність транзакцій. Тому вибір відповідного типу бази даних є дуже важливим, оскільки він безпосередньо впливає на здатність платформи забезпечувати масштабованість і гнучкість відповідно до потреб організації.
Які потреби в обробці та аналітиці в режимі реального часу?
У певних сценаріях, наприклад, при впровадженні систем динамічного ціноутворення або виявлення шахрайства, необхідність обробки даних у режимі реального часу стає вирішальною вимогою, яка диктує архітектуру вашої платформи даних. Наприклад, коригування цін на продукцію на основі різних факторів, таких як попит і ціни конкурентів, вимагає миттєвого прийняття рішень для максимізації прибутку і конкурентоспроможності. У таких ситуаціях використання обробки даних у режимі реального часу є очевидним вибором, що робить архітектуру Kappa особливо придатною.
Однак важливо зазначити, що хоча Kappa-архітектура чудово справляється з обробкою та аналітикою в режимі реального часу, вона може не бути оптимальним рішенням для завдань, пов’язаних з аналізом історичних даних, таких як аналіз довгострокових трендів або пакетна обробка історичних наборів даних. У таких випадках лямбда-архітектура може бути кращим варіантом, оскільки її пакетний рівень добре обладнаний для обробки цих специфічних потреб.
Які існують ресурсні обмеження та бюджетні міркування щодо побудови та підтримки платформи даних?
При створенні та підтримці платформи даних дуже важливо ретельно враховувати ресурсні обмеження та бюджетні фактори. Це передбачає оцінку наявних ресурсів, включаючи бюджетні асигнування, кількість наявних експертів, вартість їхнього залучення за потреби, а також можливості існуючої інфраструктури.
Крім того, для прийняття обґрунтованих рішень важливо оцінити економічну ефективність різних архітектурних варіантів. Ця оцінка повинна визначити пріоритетність інвестицій на основі очікуваної рентабельності інвестицій (ROI) і того, наскільки добре вони відповідають стратегічним цілям.
Нарешті, вибір між пропрієтарними та відкритими технологіями відіграє важливу роль у визначенні гнучкості та масштабованості. Слід ретельно зважити такі фактори, як можливості кастомізації, ризики прив’язки до постачальника та підтримка масштабованих рішень з боку спільноти. Наголос на гнучкості та масштабованості гарантує, що платформа даних залишатиметься адаптованою до вимог, що змінюються, і зможе ефективно пристосуватися до майбутнього зростання, незалежно від обраних технологій.
Джерела та додаткова література
https://www.acceldata.io/article/what-is-a-data-platform-architecture
https://www.scitepress.org/papers/2018/68693/68693.pdf
https://www.linkedin.com/pulse/data-platform-architectures-design-patterns-comparative-tfwoc
https://www.splunk.com/en_us/blog/learn/data-platform.html
https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/how-to-build-a-data-architecture-to-drive-innovation-today-and-tomorrow
ОРИГІНАЛ СТАТТІ:Anatomy of a Data Platform — How to choose your data architecture
АВТОР СТАТІ:Louis ADAM
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:

