Аналіз часових рядів є дуже корисною і потужною технікою для вивчення даних, які змінюються з часом, таких як продажі, трафік, клімат тощо. Виявлення аномалій – це процес ідентифікації значень або подій, які відхиляються від нормального тренду даних. У цій статті я поясню, що таке часовий ряд, які його складові, чим він відрізняється від інших типів даних, як можна виявити аномалії в часовому ряді та які існують найпоширеніші методи для цього.
Вступ до аналізу часових рядів
Часові ряди (Time series)- це дані, які фіксують значення однієї або декількох змінних у різні моменти часу. Наприклад, кількість відвідувачів веб-сайту щодня, середня температура в місті щомісяця, ціна акції щогодини тощо. Часові ряди дуже важливі, тому що вони дозволяють нам аналізувати минуле, розуміти сьогодення і прогнозувати майбутнє. Крім того, часові ряди допомагають нам виявити приховані закономірності та тенденції в даних, які можуть бути використані для покращення рішень та стратегій.
Однак аналіз часових рядів також має свої виклики та відмінності від аналізу нетемпоральних даних. Одна з головних відмінностей полягає в тому, що часові ряди залежать від часу, тобто порядок і діапазон даних є релевантними і не можуть бути проігноровані або змінені. Інша відмінність полягає в тому, що часові ряди часто є нестаціонарними, тобто їхні статистичні властивості (наприклад, середнє значення та дисперсія) змінюються з часом. Це ускладнює застосування традиційних статистичних методів, які передбачають стаціонарність даних.
Крім того, аналіз часових рядів вимагає іншого підходу до виявлення аномалій. Аномалії – це значення або події, які значно відхиляються від нормального тренду даних. Аномалії можуть бути спричинені помилками вимірювання, структурними змінами, шахрайськими діями, винятковими подіями тощо. Виявлення аномалій є важливим, оскільки воно може надати цінну інформацію про проблеми або можливості, приховані в даних. Однак виявлення аномалій у часових рядах є складнішим завданням, ніж у нечасових даних, оскільки необхідно враховувати часову залежність, нестаціонарність та динамічний характер даних.
Основні поняття аналізу часових рядів
Перш ніж перейти до деталей методів аналізу часових рядів та виявлення аномалій, необхідно визначити, що таке часовий ряд і які його складові. Часовий ряд – це послідовність значень однієї або декількох змінних, виміряних у різні моменти часу.
Часовий ряд складається з трьох основних компонентів: дата, час і характеристики. Дата і час вказують, коли було виміряно значення змінної. Характеристики – це самі змінні, які ми хочемо проаналізувати. У нашому прикладі дата – це день місяця, погода – день тижня, а характеристика – кількість відвідувачів.
Щоб мати можливість аналізувати часовий ряд, ми повинні відповідати певним вимогам. Першою вимогою є наявність достатньої кількості точок даних, тобто спостережень за змінною в часі. Кількість необхідних точок даних залежить від типу аналізу, який ми хочемо провести, і від того, як часто збираються дані. Наприклад, якщо ми хочемо проаналізувати сезонність даних, тобто періодичну зміну даних як функцію часу, нам потрібно мати принаймні один повний цикл спостережень, який охоплює всі можливі сезони. Якщо дані збираються щодня, нам потрібно мати дані щонайменше за рік, щоб мати можливість аналізувати річну сезонність.
Друга вимога полягає в тому, щоб добре розуміти область даних, тобто контекст, в якому вони були отримані, і значення змінних. Це допомагає нам інтерпретувати результати аналізу та визначити можливі причини аномалій. Наприклад, якщо ми аналізуємо кількість відвідувачів веб-сайту, нам потрібно знати, який тип веб-сайту, яка його цільова аудиторія, які його цілі, які фактори впливають на трафік тощо.
Третя вимога – це чітке визначення цілей аналізу, тобто того, що ми хочемо дізнатися з даних і як ми хочемо їх використовувати. Цілі аналізу можуть бути різними, залежно від варіанту використання та дослідницького питання. Наприклад, ми можемо проаналізувати часовий ряд для того, щоб:
- Описувати поведінку даних у часі та її основні характеристики
- Прогнозувати майбутні значення даних на основі минулих значень
- Виявляти аномалії в даних та їх причини
- Тестувати гіпотези про дані та їх взаємозв’язки
- Оптимізувати рішення та дії на основі даних
Розуміння аномалій у часових рядах
Перш ніж ми розглянемо, як виявляти аномалії в часових рядах, нам потрібно зрозуміти, що таке аномалії і як вони проявляються в даних. Аномалія – це значення або подія, яка значно відхиляється від нормального тренду даних. Аномалії бувають двох типів: точкові або колективні. Точкові аномалії – це ізольовані значення, які сильно відрізняються від інших значень у часовому ряді. Колективні аномалії – це групи значень, які відрізняються від решти часового ряду.
Наприклад, на наступному малюнку ми бачимо часовий ряд, який фіксує кількість відвідувачів веб-сайту щодня протягом місяця. Точкові аномалії позначені червоним кольором, а колективні – синім.
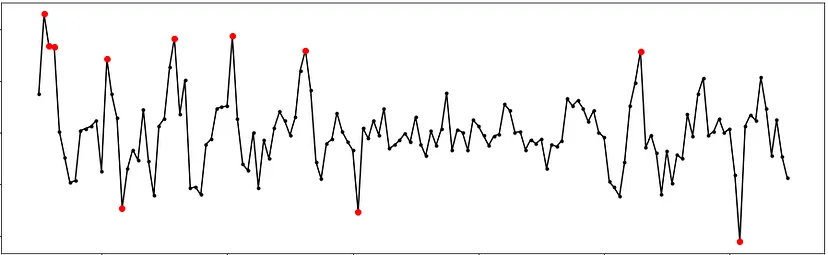
Аномалії можуть мати різні причини і значення. Деякі аномалії можуть бути спричинені помилками вимірювання, передачі або обробки даних. Такі аномалії часто називають шумом, і їх можна ігнорувати або виправити. Інші аномалії можуть бути спричинені структурними змінами, шахрайськими діями, винятковими подіями або іншими факторами, що впливають на дані. Ці аномалії часто називають сигналами, і вони можуть бути важливими для виявлення та аналізу.
Для того, щоб виявити аномалії в часових рядах, нам спочатку потрібно мати очікування щодо нормального руху даних у часі. Ці очікування ґрунтуються на аналізі основних компонентів часового ряду, а саме:
- Тренд, тобто напрямок і швидкість зміни даних у довгостроковій перспективі. Наприклад, зростаючий тренд вказує на те, що дані з часом збільшуються, тоді як спадаючий тренд вказує на те, що дані з часом зменшуються.
- Cезонність, тобто періодичну зміну даних як функцію часу. Наприклад, річна сезонність вказує на те, що дані мають циклічний характер, який повторюється щороку, наприклад, продажі в іграшкових магазинах зростають у грудні та знижуються в січні.
- Циклічність (cyclicality), тобто нерегулярна зміна даних як функція часу. Наприклад, економічна циклічність вказує на те, що дані мають тенденцію до коливання, яка залежить від зовнішніх факторів, таких як ВВП, інфляція, безробіття тощо.
- Шум (noise), тобто випадкова варіація даних як функція часу. Наприклад, шум може бути спричинений помилками вимірювання, передачі або обробки даних.
На наступному рисунку ми бачимо приклад часового ряду, який має зростаючий тренд, щорічну сезонність та шум.
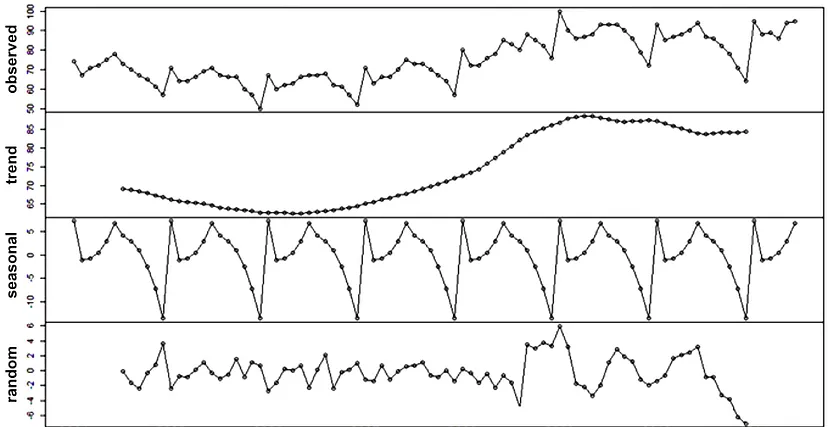
Аналізуючи часовий ряд, ми повинні враховувати ці компоненти і розуміти, як вони змінюються з часом. Зміна одного або декількох компонентів може вказувати на наявність аномалії в даних.
Вимоги до даних для аналізу часових рядів
Як ми вже бачили, для того, щоб мати можливість аналізувати часовий ряд і виявляти аномалії, нам потрібно мати дані, які відповідають певним вимогам. Першою вимогою є наявність достатньої кількості точок даних, тобто спостережень за змінною в часі. Кількість необхідних точок даних залежить від типу аналізу, який ми хочемо провести, і від того, як часто збираються дані. Наприклад, якщо ми хочемо проаналізувати тенденцію даних, нам потрібно мати щонайменше десяток точок даних, які охоплюють досить тривалий період часу. Якщо ми хочемо проаналізувати сезонність даних, нам потрібно мати принаймні один повний цикл спостережень, який охоплює всі можливі сезони. Якщо ми хочемо проаналізувати шум даних, нам потрібно мати щонайменше двадцять точок даних, які є достатньо варіабельними.
Друга вимога – мати дані, які фіксують зміни в часі, тобто відображають зміни змінної як функцію часу. Це означає, що дані повинні збиратися через регулярні та послідовні інтервали часу, без пропусків або дублювання деяких спостережень. Крім того, дані мають бути вирівняні в часі, тобто кожне спостереження має відповідати часу, коли змінна була виміряна. Це означає, що дані мають бути перетворені у відповідний формат для аналізу часових рядів, наприклад, формат «дата-час».
Третя вимога – мати дані, які відповідають мінімальним вимогам для аналізу основних компонентів часового ряду, тобто тренду, сезонності та шуму. Ці вимоги варіюються залежно від моделі, яку ми хочемо використати для аналізу. Наприклад, якщо ми хочемо використати лінійну модель для тренду, нам потрібно мати дані, які мають лінійну залежність між змінною та часом. Якщо ми хочемо використати експоненціальну модель для тренду, нам потрібно мати дані, які мають експоненціальну залежність між змінною і часом. Якщо ми хочемо використати модель ARIMA для сезонності та шуму, нам потрібно мати стаціонарні або диференційовані дані.
Диференціація в аналізі часових рядів
Як ми бачили, однією з головних проблем при аналізі часових рядів є наявність нестаціонарності в даних, тобто той факт, що статистичні властивості даних (такі як середнє значення та дисперсія) змінюються з часом. Це ускладнює застосування традиційних статистичних методів, які передбачають стаціонарність даних. Для того, щоб використовувати ці методи, ми повинні спочатку перетворити дані так, щоб вони стали стаціонарними або, принаймні, приблизно стаціонарними. Одним з найпоширеніших методів для цього є диференціювання.
Диференціювання полягає у відніманні попереднього значення від кожного значення часового ряду, в результаті чого отримуємо новий часовий ряд, який відображає зміну даних у часі. Наприклад, якщо ми маємо часовий ряд {x1, x2, x3, …}, його перша різниця буде {x2 – x1, x3 – x2, …}. Диференціювання можна повторювати кілька разів, отримуючи таким чином другу різницю, третю різницю і т.д. Диференціювання має на меті вилучити з часового ряду компоненти тренду та сезонності, які є основними причинами нестаціонарності. Насправді, якщо дані мають тренд або сезонність, то їх значення будуть корелювати з попередніми або наступними значеннями. Віднімання цих значень зменшує або усуває цю кореляцію.
Наприклад, ми бачимо часовий ряд, який має зростаючий тренд і щорічну сезонність. Його перша різниця усуває тренд, але не сезонність. Друга різниця усуває і тренд, і сезонність.
Диференціація лежить в основі однієї з найпоширеніших моделей для аналізу часових рядів і виявлення аномалій – моделі ARIMA.
Вступ до моделі ARIMA
Модель ARIMA є однією з найбільш широко використовуваних моделей для аналізу часових рядів і виявлення аномалій. ARIMA розшифровується як авторегресійне інтегроване ковзне середнє. Ця модель поєднує в собі три основні компоненти:
- Авторегресійний (AR) компонент, який моделює кореляцію між значеннями часового ряду та попередніми значеннями. Наприклад, якщо дані є циклічними, на значення часового ряду впливатимуть минулі значення.
- Вбудований (I) компонент, який моделює диференціацію часового ряду, щоб зробити його стаціонарним. Наприклад, якщо дані мають тренд або сезонність, диференціація видаляє ці компоненти з часового ряду.
- Компонент ковзного середнього (MA), який моделює кореляцію між помилками часового ряду та попередніми помилками. Наприклад, якщо дані містять шум, на помилки часового ряду впливатимуть помилки минулих періодів.
Модель ARIMA має три основні параметри: p, d і q. Параметр p вказує на кількість членів авторегресії, які використовуються в моделі. Параметр d вказує, скільки разів необхідно диференціювати часовий ряд, щоб зробити його стаціонарним. Параметр q вказує на кількість членів ковзного середнього, що використовуються в моделі. Наприклад, модель ARIMA(1,1,1) використовує авторегресійний член, різницю та ковзну середню.
Модель ARIMA можна використовувати для опису, прогнозування та виявлення аномалій у часовому ряді. Для цього потрібно виконати кілька кроків:
- По-перше, нам потрібно перевірити, чи є часовий ряд стаціонарним чи ні. Ми можемо використовувати статистичні тести, такі як розширений тест Дікі-Фуллера, щоб перевірити, чи є середнє та дисперсія часового ряду постійними в часі.
- По-друге, нам потрібно диференціювати часовий ряд до тих пір, поки він не стане стаціонарним. Ми можемо використовувати графіки, такі як графік автокореляційної функції та часткової автокореляційної функції, щоб визначити кількість необхідних різниць.
- По-третє, нам потрібно оцінити параметри ARIMA-моделі за допомогою методів оптимізації, таких як метод максимальної правдоподібності. Для вибору оптимальних значень параметрів p, d та q ми можемо використовувати критерії відбору моделей, такі як інформаційний критерій Акаіке або Байєса, щоб вибрати оптимальні значення параметрів p, d та q.
- По-четверте, нам потрібно перевірити модель ARIMA за допомогою методів верифікації, таких як тест Люнга-Бокса або тест Жарке-Бера. Ми можемо використовувати графіки, такі як графік залишків або графік прогнозу, щоб перевірити, чи добре модель узгоджується з даними і чи є в них якісь аномалії.
- По-п’яте, ми повинні використовувати модель ARIMA для опису основних характеристик часового ряду, прогнозування майбутніх значень часового ряду та виявлення аномалій у часовому ряді. Ми можемо використовувати показники точності, такі як середня квадратична похибка або середня абсолютна похибка, щоб оцінити якість прогнозів та аномалій.
Виявлення аномалій часових рядів
Після оцінки та перевірки моделі ARIMA для наших часових рядів, ми можемо використовувати її для виявлення аномалій у даних. Аномалія – це значення або подія, яка значно відхиляється від нормального тренду даних. Щоб виявити аномалії, нам потрібно порівняти спостережувані значення часового ряду зі значеннями, передбаченими моделлю ARIMA. Якщо різниця між цими двома значеннями перевищує певний поріг, ми можемо вважати спостережуване значення аномалією.
Поріг для визначення аномалій залежить від декількох факторів, таких як рівень довіри, розподіл помилок, частота даних тощо. Загалом, для визначення порогу можна використовувати поняття довірчого інтервалу. Довірчий інтервал – це інтервал, який містить прогнозоване значення з певною ймовірністю. Наприклад, 95% довірчий інтервал означає, що прогнозоване значення знаходиться в цьому діапазоні з ймовірністю 95%. Якщо спостережуване значення виходить за межі довірчого інтервалу, ми можемо вважати його аномалією.
Коли ми виявляємо аномалії в часовому ряді, ми також повинні спробувати зрозуміти їх причини і значення. Деякі аномалії можуть бути спричинені помилками вимірювання, передачі або обробки даних. Такі аномалії часто називають шумом, і їх можна ігнорувати або виправити. Інші аномалії можуть бути спричинені структурними змінами, шахрайськими діями, винятковими подіями або іншими факторами, що впливають на дані. Ці аномалії часто називають сигналами, і їх важливо виявляти та аналізувати.
Щоб зрозуміти причини і значення аномалій, ми повинні використовувати наші знання про область даних, тобто контекст, в якому дані генеруються, і значення змінних. Крім того, ми повинні використовувати додаткові джерела інформації, такі як інші пов’язані часові ряди, історичні дані, новини, звіти тощо. Це допомагає нам інтерпретувати результати виявлення аномалій і визначити можливі дії, які слід вжити.
У цій статті ми розглянули, як використовувати модель ARIMA для аналізу часових рядів і виявлення аномалій.
Висновок
У цій статті ми розглянули, як використовувати модель ARIMA для аналізу часових рядів та виявлення аномалій. Ми побачили, що таке часовий ряд, які його компоненти, чим він відрізняється від інших типів даних, як можна виявити аномалії в часовому ряді та які існують найпоширеніші методи для цього. Ми побачили, як перевірити стаціонарність даних, як диференціювати часові ряди, як оцінити та перевірити модель ARIMA, як використовувати модель ARIMA для опису, прогнозування та виявлення аномалій у часових рядах, а також як інтерпретувати результати виявлення аномалій.
Аналіз часових рядів та виявлення аномалій є дуже корисними та потужними методами для вивчення даних, які змінюються з часом, таких як продажі, трафік, клімат тощо. Ці методи дозволяють нам аналізувати минуле, розуміти сьогодення та прогнозувати майбутнє. Крім того, вони допомагають виявити приховані закономірності та тенденції в даних, які можна використати для покращення рішень і стратегій. Нарешті, ці методи допомагають нам виявити приховані проблеми або можливості в даних, які можуть бути викликані аномаліями в даних.
Сподіваюся, ця стаття була для вас корисною та цікавою. Якщо у вас виникли запитання чи коментарі, будь ласка, не соромтеся звертатися до мене. Дякую, що прочитали мою статтю.
ОРИГІНАЛ СТАТТІ:Anomaly detection for Time Series Analysis
АВТОР СТАТІ:Carlo C.
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook: