
Ви коли-небудь замислювалися, як DA та DS орієнтуються у світі аналітики? Уявіть собі команду розробників, яка зосереджена на тому, щоб клієнти залишалися задоволеними під час збоїв у роботі. Від створення додатків до оптимізації послуг з відновлення – все для того, щоб звести до мінімуму збої в роботі. Вгадайте, яка моя секретна зброя як керівника відділу аналітики (спойлер: це не spreadsheets/EXCEL !)?
Відповідь: SQL.
Ця мова, незважаючи на свою старомодність, є моїм ключем до швидкого і приємного отримання інсайтів зі сховища даних (Azure Synapse/Azure SQL DB залежно від аналізу).
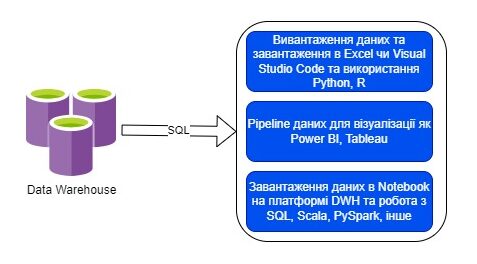
У цій статті я покажу, як я використовував SQL для вирішення реальної бізнес-проблеми. Ми заглибимося в:
- Виклик, з яким зіткнулася наша команда
- Моя гіпотеза, заснована на даних
- Конкретний набір даних
- SQL-запити, які допомогли отримати відповіді
Сподіваюсь, ця публікація не тільки дасть вам уявлення про індустрію, але й зарядить дофаміном для вивчення SQL.
Давайте зануримося!
1. Проблема бізнесу
Згадаймо мету команди. Ми зосереджуємося на трансформації досвіду клієнтів щодо перебоїв у роботі через розробку продуктів та операційне вдосконалення.
Завдяки інсайтам, заснованим на даних, наша команда скоротила кількість дзвінків клієнтів удвічі. Однак я бачу, що показники кількості дзвінків перетворюються на стабільну тенденцію.
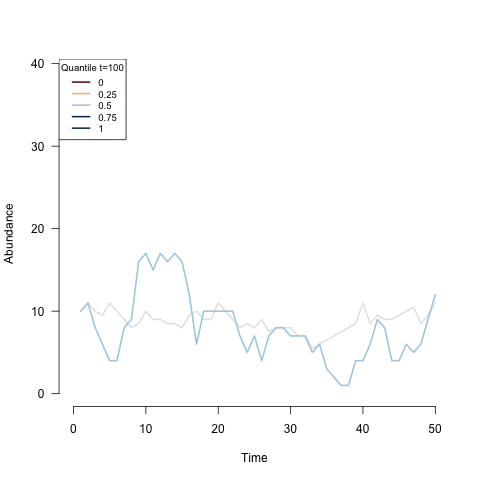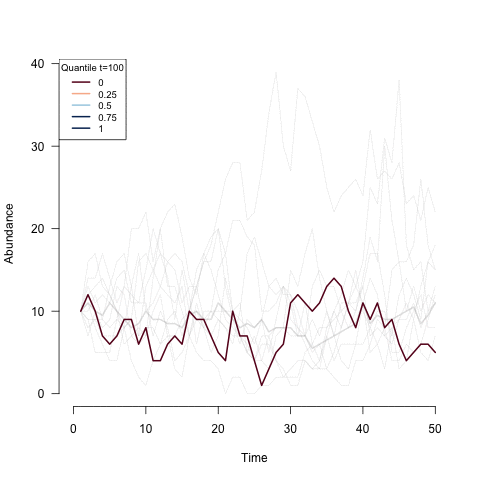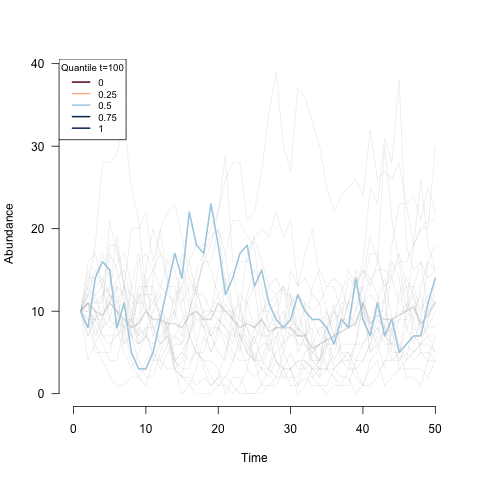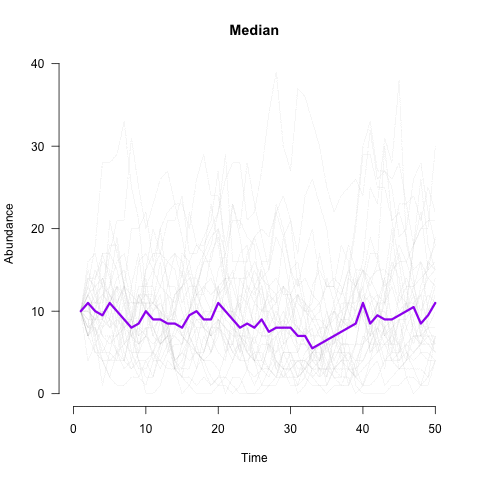
Ось 2 можливих сценарії:
- Чи досягло використання функції насичення (saturation)? Це означає, що незалежно від того, яку функцію ми впроваджуємо далі, клієнти певної демографічної групи надають перевагу дзвінкам, а не мобільним/веб-додаткам.
Або…
- Чи ми все ще недостатньо задовольняємо потреби клієнтів усіма функціями, які їм надаємо?
Я схиляюся до другого варіанту.
2. Моя гіпотеза
Отже, моя гіпотеза була такою:
Ми недостатньо задовольняємо потреби клієнтів.
Це була загальна гіпотеза, але хороший початок. Щоб ефективно вирішити проблему, яку ми мали, я вдосконалив її далі:
Невелика група клієнтів становить понад 80% загальної кількості телефонних дзвінків. І саме ця група потребує більше нашої допомоги.
Для перевірки гіпотези мені потрібні були такі дані:
- записи дзвінків на рівні клієнта
- дані, починаючи з 2022 року, коли ми почали спостерігати зацікавленість у першій функції
- записи дзвінків повинні містити інформацію про аварійні події та деталі дзвінків, включаючи зміст дзвінка та інформацію про абонента, для подальшого глибокого аналізу, якщо моя гіпотеза підтвердиться.
3. Набір даних
Точно знаючи, що мені потрібно, я вирішив дослідити базу даних. Клієнт, на якого я працюю, не мав хорошої документації по базі даних, тому я працював з інженером даних, щоб зібрати необхідну інформацію.
Ось 2 таблиці даних, які виглядають потенційними:
- call table: записи дзвінків за останні два десятиліття на рівні клієнтів з деталями про абонента, зміст дзвінка та відповідні аварійні події — Фантастично! Перспективна таблиця даних!
- outage events: деталі аварійних подій на рівні подій — Чудово!
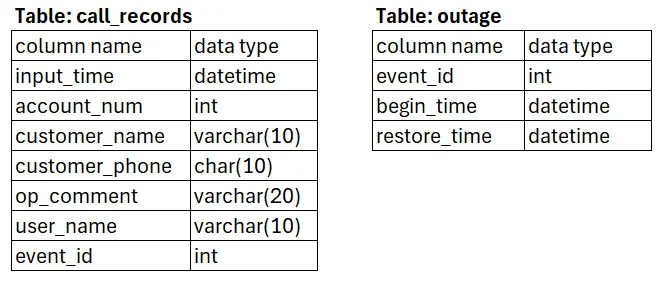
Зробивши кілька запитів, я підтвердив, що це саме ті таблиці, котрі я можу використати.
Гаразд, давайте почнемо.
4. Запити
4.1 Знайти відсоток клієнтів, які зробили 80% від загальної кількості телефонних дзвінків
Кілька міркувань перед тим, як я почну витягувати цифри:
- Мене цікавили лише телефонні дзвінки, або автоматизовані, або дзвінки агентів, оскільки ці дзвінки були дорогими для бізнесу.
- Якщо моя гіпотеза підтвердиться, я заглиблюся в записи дзвінків і мені потрібні дані без пропусків у інформації про абонента та події, що означає видалення відсутніх даних з аналізу. (якщо у вас більше ніж 5% відсутніх даних, будьте обережні!)
Це повний запит:
--find the percentage of customers who made more than 80% of phone calls over the past 2 years
--find running total calls by customers
WITH calls AS (
SELECT account_num
, sum(count(*)) over (order by count(*) desc) as rolling_total
FROM call_records
WHERE year(input_time) BETWEEN 2022 AND 2023
AND event_id != 0
AND account_num is not null
AND (user_name LIKE 'E%' OR user_name LIKE 'e%' OR user_name LIKE 'c%'
OR (user_name LIKE 'C%' AND user_name != 'COF')
OR user_name = 'IVR')
GROUP BY account_num
)
--find the percentage of customers who made up over 80% of total phone calls
SELECT (count(*)+1)* 100.0 / (SELECT count(*) FROM calls) as pct
FROM calls
WHERE rolling_total < 0.8 * (SELECT max(rolling_total) from calls)А тепер найцікавіше. Вгадайте, скільки він пробіг?
10 секунд! Вона проаналізувала 4 мільйони дзвінків і дала мені відповідь всього за ковток кави. Кому це не сподобається?
І моя гіпотеза виявилася правдивою. Настав час копнути глибше.

4.2 Що ми можемо зробити, щоб краще обслуговувати цю групу, щоб їм не потрібно було здійснювати дзвінки?
Щоб вирішити цю проблему, мені потрібно було з’ясувати їхні мотиви для дзвінка. Для цього я розбила проблему на невеликі питання, які можна вирішити:
- Чи були у них більш тривалі та часті перебої в роботі, ніж в іншій групі, і чи було більше дзвінків?
- В яких сферах ми не змогли допомогти їм своїми можливостями?
Розглянемо перше питання. Ось запит для відповіді на нього:
--zoom in on outage length and frequency each group of customers experienced over past 2 years
--find running total calls (%) by customers
WITH calls AS (
SELECT account_num
, count(DISTINCT c.event_id) as total_outages
, avg(datediff(minute, begin_time, restore_time)) as length
, sum(count(*)) over (order by count(*) desc) * 1.0 / sum(count(*)) over () as rolling_pct
FROM call_records c
JOIN outage o
ON c.event_id = o.event_id
WHERE year(input_time) BETWEEN 2022 AND 2023
AND account_num is not null
AND (user_name LIKE 'E%' OR user_name LIKE 'e%' OR user_name LIKE 'c%'
OR (user_name LIKE 'C%' AND user_name != 'COF')
OR user_name = 'IVR')
GROUP BY account_num
),
rolling_previous AS (
SELECT *, lag(rolling_pct,1,0) over (order by rolling_pct) as prev_pct FROM calls
)
--find the frequency and length of outage events for each group
(SELECT 'active callers' as group
, avg(length) as avg_length
, avg(total_outages) as avg_frequency
FROM rolling_previous
WHERE prev_pct < 0.8)
UNION
(SELECT 'non-active callers' as group
, avg(length) as avg_length
, avg(total_outages) as avg_frequency
FROM rolling_previous
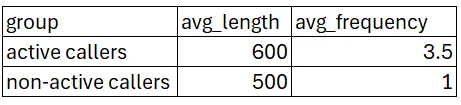
WHERE prev_pct >= 0.8)Активні абоненти не мали набагато довших відключень, ніж інша група, але мали значно більше відключень за останні 2 роки.
Переходимо до другого питання – в якій сфері ми не змогли допомогти їм за допомогою наших додатків?
-- find most popular reasons for calling
SELECT substring(op_comment,1,5) as call_content,
count(*)*100.0 / sum(count(*)) over () as pct
FROM rolling_previous c
JOIN call_records r ON r.account_num = c.account_num
WHERE prev_pct < 0.8
GROUP BY substring(op_comment,1,5)
ORDER BY pct DESCВиявилося, що це час прибуття. Більшість дзвінків стосувалися саме цього.

Гаразд, тоді я зрозумів, що у нас є проблеми як з мережевою системою (частота відключень), так і зі службами відновлення та/або каналами передачі даних (оновлення даних під час відключень).
Примітка: Додатки для аварійних відключень за своєю суттю є додатками для передачі даних, які передають оновлення клієнтам під час відключень. Отже, якщо клієнти вимагають оновлення, ми не можемо виключити можливість проблеми з каналом передачі даних.
4.3 Оптимізація запитів
Ви помітили, що CTE (загальні табличні вирази) досить схожі в кожному із запитів, чи не так? Краще за все створити представлення для такого сценарію, щоб не переписувати його знову і знову. Ось код для цього.
Крім того, подання не займають фізичного місця в базі даних, а отже, не впливають на продуктивність. У вас все ще є 10-секундна розкіш!
--create view for re-use
CREATE OR REPLACE VIEW rolling_previous AS
WITH calls AS (
SELECT account_num
, count(DISTINCT c.event_id) as total_outages
, avg(datediff(minute, begin_time, restore_time)) as length
, sum(count(*)) over (order by count(*) desc) * 1.0 / sum(count(*)) over () as rolling_pct
FROM call_records c
JOIN outage o
ON c.event_id = o.event_id
WHERE year(input_time) BETWEEN 2022 AND 2023
AND account_num is not null
AND (user_name LIKE 'E%' OR user_name LIKE 'e%' OR user_name LIKE 'c%'
OR (user_name LIKE 'C%' AND user_name != 'COF')
OR user_name = 'IVR')
GROUP BY account_num
)
SELECT *, lag(rolling_pct,1,0) over (order by rolling_pct) as prev_pct FROM calls5. Підбиваємо підсумки
Ви все ще думаєте, що SQL не є вашим повсякденним героєм? Це лише невелика частина того, як ця надійна мова може прокласти собі шлях до вирішення реальних проблем. Приготуйтеся вивільнити силу маніпулювання даними!
Сподіваюся, цей приклад використання SQL для вирішення реальних проблем зацікавив вас. Оволодіння навіть базовими основами SQL має велике значення.
Це все на сьогодні.
Будьте здорові та обробляйте дані!
Якщо ви вважаєте цю статтю корисною та цікавою, будь ласка, поставте лайк і поділіться нею з іншими, кому вона також може бути цікавою.
Дайте мені знати в коментарях про проблеми, які вирішує ваш SQL! І не забувайте слідкувати за мною, щоб дізнатись більше історій про дані.
Дякую, що прочитали!
ОРИГІНАЛ СТАТТІ:This is Exactly How I Use SQL at Work as an Analyst
АВТОР СТАТІ:Luna (Van) Doan
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


