(ДИНАМІЧНА ЗВІТНІСТЬ, НЕОБХІДНА КОЖНОМУ БІЗНЕСУ)
ЯК ДЛЯ АНАЛІТИКА ДАНИХ, ЦЕ, МОЖЛИВО, ОДИН З НАЙЦІКАВІШИХ ПРОЕКТІВ, ЯКІ ВИ КОЛИ-НЕБУДЬ ОТРИМУВАЛИ, ТОМУ ЩО ВИ ЗМОЖЕТЕ ПОБАЧИТИ, ЯК ЗМІНЮЮТЬСЯ БІЗНЕС-ПОКАЗНИКИ В РЕАЛЬНОМУ ЧАСІ.
У реальному світі компанії щодня отримують нові дані в свою базу даних, і тому динамічні звіти є необхідними.
ЩО ТАКЕ ДИНАМІЧНІ ДАШБОРД-ЗВІТИ?
Динамічні звіти – це звіти, які відображають останні оновлення/зміни в базі даних.
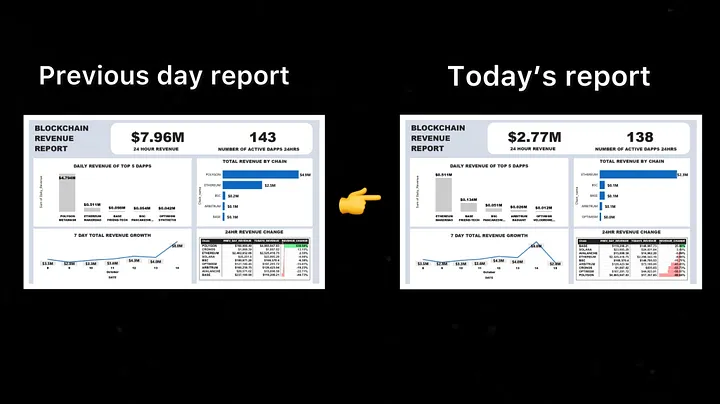
Приклад: Вчора інтернет-магазин отримав 2500 замовлень від своїх клієнтів, а сьогодні – 2800 замовлень. Статична інформаційна панель покаже лише загальну кількість замовлень за попередній день, тоді як динамічний звіт покаже загальну кількість замовлень за останній робочий день, тобто 2800 замовлень, а також може відображати зростання кількості замовлень між попереднім і поточним днями. Нижче наведено простий приклад того, як працює динамічний звіт: після оновлення сторінки інформаційної панелі у вашому інструменті BI динамічний звіт відображає останні зміни в даних.
Динамічні звіти інформаційної панелі(dashboard) важливі, оскільки вони можуть бути використані для відстеження важливих показників зростання бізнесу, таких як відтік/утримання клієнтів, зростання/зменшення доходу бізнесу та кількість нових клієнтів за день, тиждень, місяць, рік тощо.
У цьому проекті я буду створювати динамічний звіт з використанням даних, отриманих з криптовалютного веб-аплікатора, цей загальнодоступний веб-аплікатор надає дані про дохід, який генерується декількома криптовалютними проектами на щоденній основі.
Мета цього проекту – проаналізувати зростання доходу з часом, щоденний дохід, відстежити, скільки криптовалютних проектів фактично активні і отримують дохід на щоденній основі, а також 24-годинні зміни доходу.
Ось приклад звіту, який ми будемо отримувати щодня.
Використані інструменти та технології:
- Python
- База Даних SQL SERVER
- POWER BI
- Планувальник завдань Windows
АРХІТЕКТУРА ПРОЕКТУ

КРОК 1
Створіть скрипт на python для вилучення даних з вашої бази даних. Скрипт нижче витягує дані з API і завантажує їх в базу даних SQL сервера.
Нагадування: Не звертайте уваги на те, наскільки простим або складним може виглядати скрипт, а просто зрозумійте, що він витягує дані з джерела даних і завантажує їх в нашу базу даних. Ви можете прочитати заголовки зеленого кольору на початку кожного підскрипта, щоб зрозуміти, що робить цей підскрипт.
#Importing needed libraries
import pandas as pd
from sqlalchemy import create_engine
import sqlalchemy
import os
import requests
from datetime import date
from sqlalchemy import MetaData
from sqlalchemy import Table, Column, Integer, String, Numeric
from sqlalchemy.dialects.mysql import VARCHAR
import pyodbc
#GETTING CURRENT DATE BECAUSE THE DOESN'T COME WITH A DATE COLUMN
now = date.today()
now
todays_date = now.strftime('%Y/%m/%d')
todays_date
#EXTRACTING DATA FROM ETHEREUM API
eth_api = 'https://api.llama.fi/overview/fees/ethereum?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue'
params = {'chain':'Ethereum'}
r = requests.get(eth_api,
params = params)
eth_json = r.json()
eth_df = pd.DataFrame(eth_json['protocols'])
eth_df.head(3)
#CREATING A FUNCTION TO EXTRACT DATA FROM ANY API LINK PROVIDED
def extract_from_api(api_url, chain_name,params):
params = {'chain': chain_name}
r = requests.get(api_url,
params = params)
chain_json = r.json()
chain_df = pd.DataFrame(chain_json['protocols'])
return chain_df
#THIS FUNCTION TRANSFORMS THE DATA, AND KEEPS THE NECESSARY COLUMNS NEEDED
def transform_data(chain_df, chain_name):
cols = ['defillamaId', 'name', 'module','category', 'dailyRevenue', 'dailyFees']
chain_df = chain_df[cols]
chain_df.insert(4, "CHAIN_NAME", chain_name)
chain_df.insert(7, "DATE", todays_date)
return chain_df
#THIS FUNCTION EXECUTES THE SET OF FUNCTIONS CREATED ABOVE
def extract_and_transfrom(api_url, chain_name, params):
chain_df = extract_from_api(api_url, chain_name, params)
chain_df = transform_data(chain_df, chain_name)
return chain_df
#RUNNING THE ETL FUNCTIONS CREATED ON EACH API LINK PROVIDED
eth_df = extract_and_transfrom('https://api.llama.fi/overview/fees/ethereum?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'ETHEREUM', params)
arb_df = extract_and_transfrom('https://api.llama.fi/overview/fees/arbitrum?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'ARBITRUM', params)
op_df = extract_and_transfrom('https://api.llama.fi/overview/fees/optimism?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'OPTIMISM', params)
bsc_df = extract_and_transfrom('https://api.llama.fi/overview/fees/BSC?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'BSC', params)
polygon_df = extract_and_transfrom('https://api.llama.fi/overview/fees/polygon?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'POLYGON', params)
avalache_df = extract_and_transfrom('https://api.llama.fi/overview/fees/avalanche?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'AVALANCHE', params)
base_df = extract_and_transfrom('https://api.llama.fi/overview/fees/base?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'BASE', params)
solana_df = extract_and_transfrom('https://api.llama.fi/overview/fees/solana?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'SOLANA', params)
cronos_df = extract_and_transfrom('https://api.llama.fi/overview/fees/cronos?excludeTotalDataChart=true&excludeTotalDataChartBreakdown=true&dataType=dailyRevenue', 'CRONOS', params)
#PUTTING ALL PANDAS DATAFRAMES INTO A LIST
chain_df_list = [eth_df,
arb_df,
op_df,
bsc_df,
polygon_df,
base_df,
avalache_df,
solana_df,
cronos_df]
#IMPORTING SQLALCHEMY LIBRARIES
from sqlalchemy import MetaData
from sqlalchemy import Table, Column, Integer, String, Numeric
from sqlalchemy.dialects.mysql import VARCHAR
import pyodbc
#CONNECTING WITH SQL SERVER DATABASE USING SQL ALCHEMY
SERVER = os.environ.get('MS SQL SERVER NAME')
DRIVER = os.environ.get('MS SQL SERVER DRIVER')
database_name = 'defi_db'
SQL_SERVER_CONNECTION = sqlalchemy.create_engine(f'mssql://{SERVER}/{database_name}?driver={DRIVER}')
SERVER = os.environ.get('MS SQL SERVER NAME')
DRIVER = os.environ.get('MS SQL SERVER DRIVER')
database_name = 'defi_db'
cnxn_str = (f"Driver={DRIVER};"
f"Server= {SERVER};"
"Database=defi_db;"
"Trusted_Connection=yes;")
cnxn = pyodbc.connect(cnxn_str)
cursor = cnxn.cursor()
#THIS FUNCTION LOADS THE DATA EXTRACTED FROM THE API INTO A SQL SERVER DATABASE
#ALL THE PANDAS DATAFRAME TABLES GOTTEN FROM THE API CALL AND CONCATENATED INTO
#ONE TABLE AND LOADED INTO THE DATABASE USING THIS FUNCTION BELOW
def concatenate_and_load(chain_list):
final_df = pd.concat(chain_list)
final_df.to_sql('staging_defi_revenue_details', SQL_SERVER_CONNECTION,
if_exists = 'replace', index = False,
dtype = {'defillamaId': sqlalchemy.types.INTEGER(),
'name': sqlalchemy.types.String(50),
'module': sqlalchemy.types.String(50),
'category': sqlalchemy.types.String(50),
'CHAIN_NAME': sqlalchemy.types.String(50),
'dailyRevenue': sqlalchemy.types.Numeric(10,2),
'dailyFees':sqlalchemy.types.Numeric(10,2),
'DATE': sqlalchemy.types.Date()})
#REMOVING DUPLICATES FROM THE STAGING TABLE BEFORE INSERTING INTO
#DATA WAREHOUSE TABLE
cursor.execute('with check_for_duplicate_data as (\
select defillamaId, name, module, category,\
CHAIN_NAME, dailyRevenue, dailyFees, DATE,\
row_number() over (partition by defillamaId,\
name, module, category, CHAIN_NAME, dailyRevenue, dailyFees, DATE\
order by defillamaId, name, module, category,\
CHAIN_NAME, dailyRevenue, dailyFees, DATE) as duplicate_count\
from [dbo].[staging_defi_revenue_details])\
delete from check_for_duplicate_data \
where duplicate_count > 1')
#INSERTING INTO DATA WAREHOUSE TABLE
cursor.execute('INSERT INTO dbo.DW_DEFI_REVENUE_TABLE
(Defi_lama_ID, Dapp_name, Module, Category, Chain_name, Daily_Revenue,
Daily_Fees, Date) select * from dbo.staging_defi_revenue_details')
#COMMITING THE EXECUTION
cnxn.commit()
print('data successfully loaded into SQL SERVER DATABASE')
#LOADING THE TABLE INTO THE DATABASE
concatenate_and_load(chain_df_list)
#CLSOING AND DISPOSING CONNECTION TO THE DATABASE
SQL_SERVER_CONNECTION.dispose()
cnxn.close()
КРОК 2
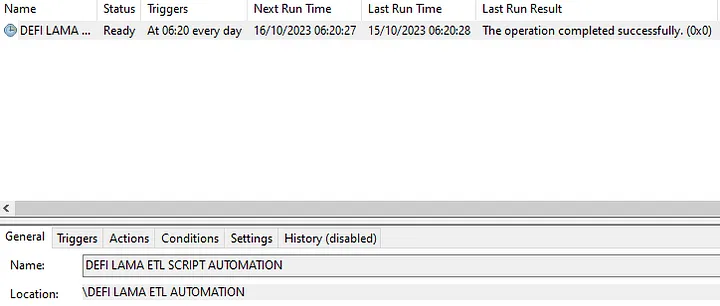
Автоматизуйте python-скрипт за допомогою crontab або планувальника Windows, у моєму випадку я використовую планувальник Windows, і як показано нижче, скрипт запускається щодня о 6:20 ранку.
КРОК 3
Створюйте динамічні SQL-views для відстеження важливих інсайтів, а потім конвертуйте їх у відповідні візуалізації за допомогою power bi або будь-якого іншого інструменту BI.
- ЗАГАЛЬНИЙ ДОХІД ЗА 24 ГОДИНИ
CREATE VIEW TOTAL_24HOUR_REVENUE
AS
--CREATING A VIEW TO SHOW TOTAL REVENUE
select round(SUM(Daily_Revenue),0) AS TOTAL_REVENUE
from DW_DEFI_REVENUE_TABLE
--WHERE CLAUSE ENSURES WE ARE ONLY GETTING DATA THE CURRENT DATE
WHERE Date = cast(getdate() as date)Нижче наведено результат при перетворенні на візуалізацію power bi card.

2. 24-ГОДИННИЙ ЗАГАЛЬНИЙ ДОХІД ТОП-5 БЛОКЧЕЙНІВ
--CREATING A VIEW TO SHOW THE TOP 5 BLOCKCHAINS BY REVENUE GENERATED
--WITHIN THE LAST 24 HOURS.
CREATE VIEW TOP_5_HIGHEST_EARNING_BLOCKCHAINS_LAST_24HRS
AS
SELECT top (5) Chain_name,
round(SUM(Daily_Revenue),0) AS TOTAL_DAILY_REVENUE
FROM DW_DEFI_REVENUE_TABLE
WHERE Date = cast(getdate() as date)
GROUP BY Chain_name
ORDER BY SUM(Daily_Revenue) DESCНижче наведено результат при перетворенні в гістограму “Power-BI”.
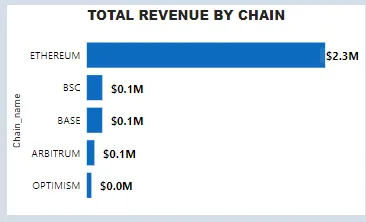
До речі, якщо ви, як і я, любите працювати з даними та створювати рішення на основі даних, будь ласка, не соромтеся зв’язуватися зі мною на LINKED IN за цим посиланням:www.linkedin.com/in/ifeanyi-okoye-a857911ba
3. ГРАФІК ДОХОДІВ ЗА 7 ДНІВ
-- CREATING A VIEW TO CALCULATE GROWTH IN TOTAL REVENUE
-- OVER A 7 DAY PERIOD.
CREATE VIEW TOTAL_DAILY_REVENUE_7_DAYS AS
select Date, sum(Daily_Revenue) as TOTAL_DAILY_REVENUE
from DW_DEFI_REVENUE_TABLE
where Date between
cast(getdate() - 7 as date) and
cast(getdate() as date)
group by DateНижче наведено результат при перетворенні в PowerBI лінійну діаграму.
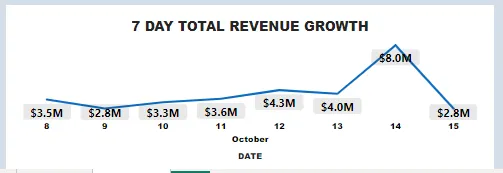
4. ЗАГАЛЬНА КІЛЬКІСТЬ АКТИВНИХ ДЕЦЕНТРАЛІЗОВАНИХ ДОДАТКІВ ЗА ОСТАННІ 24 ГОДИНИ
--AN DAPP IS CONSIDERED ACTIVE IF IT HAS GENERATED ANY FORM OF
--REVENUE WITHIN 24 HOURS.
CREATE VIEW TOTAL_NUMBER_OF_ACTIVE_DEFI_PLATFORMS
AS
WITH TOTAL_NUMBER_OF_ACTIVE_DEFI_PLATFORMS AS (
select DISTINCT Module, SUM(Daily_Revenue) AS TOTAL_REVENUE,
SUM(Daily_Fees) AS TOTAL_FEES
from DW_DEFI_REVENUE_TABLE
where Date = CAST(GETDATE() AS DATE)
and Module not like Chain_name
AND (Daily_Revenue IS NOT NULL
OR Daily_Fees IS NOT NULL)
GROUP BY Module
HAVING (SUM(Daily_Revenue) != 0
OR SUM(Daily_Fees) != 0))
SELECT COUNT(*) AS ACTIVE_DEFI_PLATFROM_COUNT
FROM TOTAL_NUMBER_OF_ACTIVE_DEFI_PLATFORMS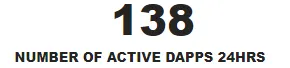
5. 24-ГОДИННА ЗМІНА ДОХОДУ
--BELOW VIEW TRACKS 24 HOUR REVENUE CHANGE
CREATE VIEW _24HR_REVENUE_CHANGE AS
with todays_revenue as (
SELECT Chain_name, sum(Daily_Revenue) as revenue_today
FROM DW_DEFI_REVENUE_TABLE
where date = cast(getdate() as date)
group by Chain_name),
yesterdays_revenue as (
select Chain_name, sum(Daily_Revenue) as revenue_yesterday
FROM DW_DEFI_REVENUE_TABLE
where date = cast(getdate() - 1 as date)
group by Chain_name)
select tr.Chain_name, sum(ry.revenue_yesterday) AS YESTERDAYS_REVENUE,
sum(tr.revenue_today) AS TODAYS_REVENUE,
((sum(tr.revenue_today) - sum(ry.revenue_yesterday)) / sum(ry.revenue_yesterday))
AS PERCENTAGE_CHANGE_IN_REVENUE_24HRS
from todays_revenue tr
inner join yesterdays_revenue ry
on tr.Chain_name = ry.Chain_name
group by tr.Chain_name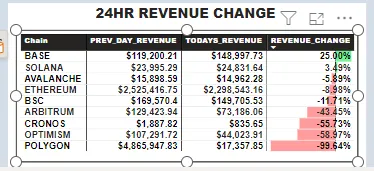
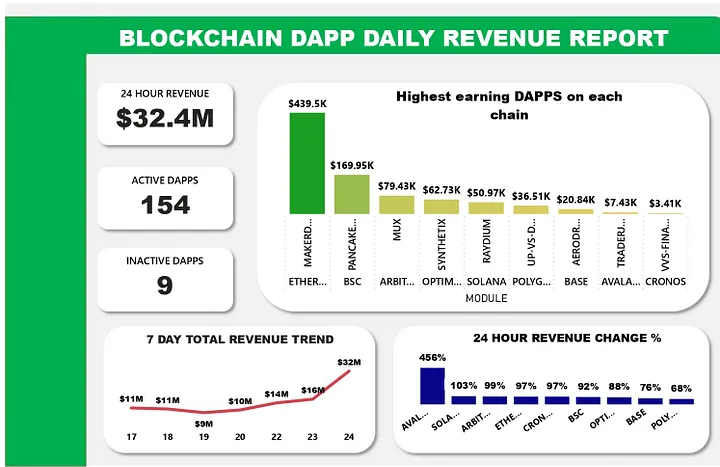
ПІДСУМКОВИЙ ЗВІТ, ЩО ВІДОБРАЖАЄ ВСІ ВАЖЛИВІ ІНСАЙТИ В ОДНІЙ ІНФОРМАЦІЙНІЙ ПАНЕЛІ.
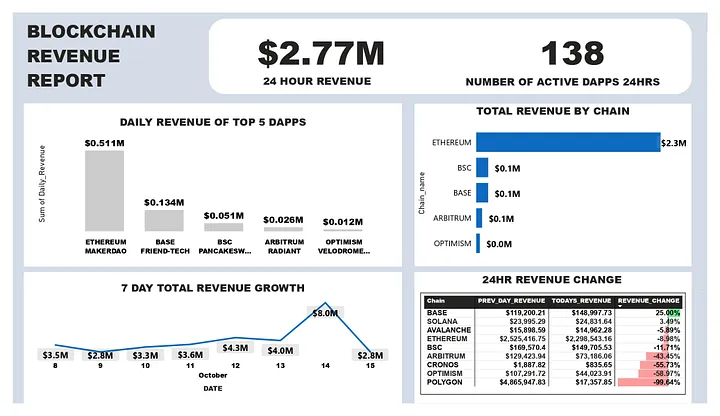
ВАЖЛИВІ ІНСАЙТИ, ЯКІ МИ ЗАПИСУЄМО.
Згідно з даними, отриманими за останні 7 днів, Ethereum генерує найбільший дохід на щоденній основі, і цей дохід є досить стабільним, що є вагомим показником стабільності екосистеми.
Friend tech, децентралізований додаток на ланцюжку BASE, нещодавно зазнав значного падіння доходів.
За величезним стрибком доходів екосистеми полігонів послідувало масове падіння через 24 години, як показано на 24-годинному графіку зміни доходів, більша частина цих доходів надійшла від Metamask – децентралізованого гаманця, що використовується для зберігання криптовалют.
ВИСНОВОК
Оскільки дані постійно змінюються, скрипти, що використовуються в таких проектах, можуть потребувати оновлення час від часу, щоб врахувати будь-які нові зміни у вихідних даних.
Сподіваємося, що ця стаття була для когось корисною, не соромтеся задавати будь-які питання в коментарях.
ОРИГІНАЛ СТАТТІ:HOW TO AUTOMATE YOUR DASHBOARD REPORT USING PYTHON, SQL AND POWER BI.
АВТОР СТАТІ:Kingsley Okoye
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X:
