Потокова (streaming) база даних – це тип бази даних, яка спеціально розроблена для обробки великих обсягів потокових даних у реальному часі. На відміну від традиційних баз даних, які зберігають дані пакетами перед обробкою, потокові бази даних обробляють дані одразу після їх створення, що дає змогу отримувати інформацію та аналізувати її в режимі реального часу. На відміну від традиційних механізмів потокової обробки, які не зберігають дані, потокова база даних може зберігати дані і відповідати на запити користувачів на доступ до даних. Потокові бази даних ідеально підходять для критичних до затримок додатків, таких як аналітика в реальному часі, виявлення шахрайства, моніторинг мережі та Інтернет речей (IoT), і можуть спростити стек технологій.
Коротка історія
Концепція потокової бази даних була вперше представлена в академічних колах у 2002 році. Група дослідників з Браунського, Брандейського та Массачусетського технологічних інститутів звернула увагу на потребу в управлінні потоками даних всередині баз даних і створила першу потокову базу даних Aurora. Через кілька років технологія була прийнята великими підприємствами. Три найбільші постачальники баз даних, Oracle, IBM і Microsoft, послідовно випустили свої рішення для потокової обробки даних, відомі як Oracle CQL, IBM System S і Microsoft SQLServer StreamInsight. Замість того, щоб розробляти потокову базу даних з нуля, ці постачальники безпосередньо інтегрували функціональність обробки потоків у свої існуючі бази даних.
З кінця 2000-х років розробники, натхненні MapReduce, відокремили функціональність обробки потоків від систем баз даних і розробили масштабні механізми обробки потоків, включаючи Apache Storm, Apache Samza, Apache Flink і Apache Spark Streaming. Ці системи були розроблені для безперервної обробки вхідних потоків даних і передачі результатів у наступні системи. Однак, на відміну від потокових баз даних, механізми обробки потоків не зберігають дані і, отже, не можуть обслуговувати спеціальні запити, ініційовані користувачем.
Потокові бази даних розвиваються паралельно з механізмами обробки потоків. Дві потокові бази даних, PipelineDB і KsqlDB, були розроблені в 2010-х роках і були популярні в той час. На початку 2020-х з’явилося кілька хмарних потокових баз даних, таких як RisingWave, Materialize і DeltaStream. Ці продукти мають на меті надати користувачам послуги потокової бази даних у хмарі. Для досягнення цієї мети основна увага приділяється розробці архітектури, яка повністю використовує ресурси хмари для досягнення необмеженої горизонтальної масштабованості та найвищої економічної ефективності.
Типові випадки використання
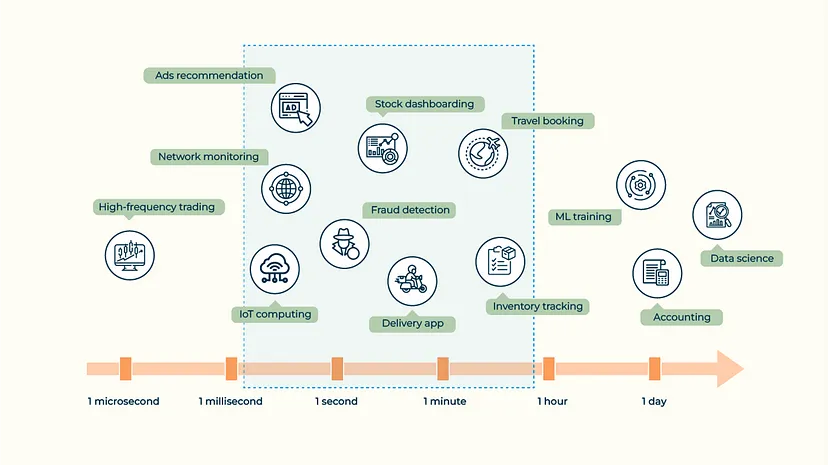
Потокові бази даних добре підходять для додатків, що працюють в режимі реального часу і потребують актуальних результатів з вимогою свіжості від субсекунд до хвилин. Такі додатки, як IoT і моніторинг мережі, вимагають субсекундної затримки, а вимоги до затримки для таких додатків, як рекламні рекомендації, інформаційні панелі запасів і доставка їжі, можуть варіюватися від сотень мілісекунд до декількох хвилин. Потокові бази даних безперервно надають результати з низькою затримкою і можуть добре підходити для цих додатків.
Деякі додатки не чутливі до свіжості даних і можуть терпіти затримки в десятки хвилин, годин або навіть днів. Деякі типові програми включають бронювання готелів та відстеження запасів. У цих випадках користувачі можуть розглянути можливість використання потокових баз даних або традиційних пакетних баз даних. Вони повинні приймати рішення на основі інших факторів, таких як економічна ефективність, гнучкість і складність технологічного стека.
Потокові бази даних зазвичай використовуються разом з іншими системами даних у додатках реального часу для полегшення двох класичних типів використання: потокового поглинання (ETL) і потокової аналітики.
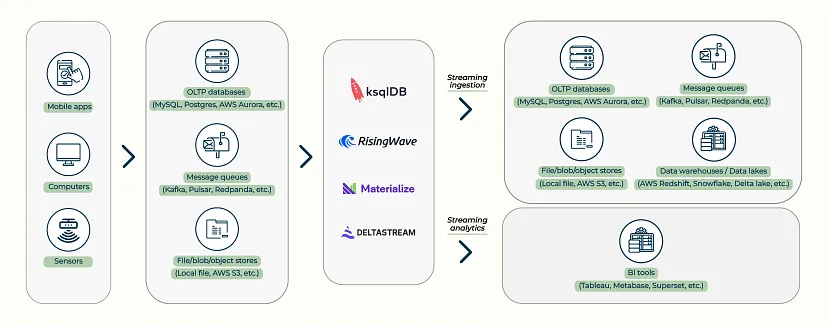
Потоковий прийом (ETL)
Потокове поглинання забезпечує безперервний потік даних від одного набору систем до іншого. Розробники можуть використовувати потокову базу даних для очищення потокових даних, об’єднання декількох потоків і переміщення об’єднаних результатів у наступні системи в режимі реального часу. У реальних сценаріях дані, що потрапляють до потокових баз даних, зазвичай надходять з баз даних OLTP, черг повідомлень або систем зберігання. Після обробки результати, найімовірніше, скидаються назад у ці системи або вставляються в сховища даних чи озера даних.
Потокова аналітика
Потокова аналітика зосереджена на виконанні складних обчислень і наданні свіжих результатів “на льоту”. У сценарії потокової аналітики дані зазвичай надходять з баз даних OLTP, черг повідомлень і систем зберігання. Результати зазвичай потрапляють в обслуговуючу систему для підтримки користувацьких запитів. Потокова база даних також може обслуговувати запити самостійно. Користувачі можуть підключати потокову базу даних безпосередньо до інструменту BI для візуалізації результатів.
Зі зростанням попиту на машинне навчання в режимі реального часу потокові бази даних також стали важливим інструментом для забезпечення гнучкої функціональної інженерії. Використовуючи потокові бази даних для зберігання перетворених даних у вигляді функцій, розробники можуть швидко реагувати на зміну шаблонів даних і нові події. Потокові бази даних дозволяють отримувати, обробляти і перетворювати дані в реальному часі на значущі властивості, що підвищує точність і ефективність моделей машинного навчання, а також зменшує дублювання даних і покращує їхню якість. Це дає змогу організаціям приймати швидші та більш обґрунтовані рішення, оптимізувати робочі процеси машинного навчання та отримати конкурентну перевагу.
Потокові бази даних проти традиційних баз даних
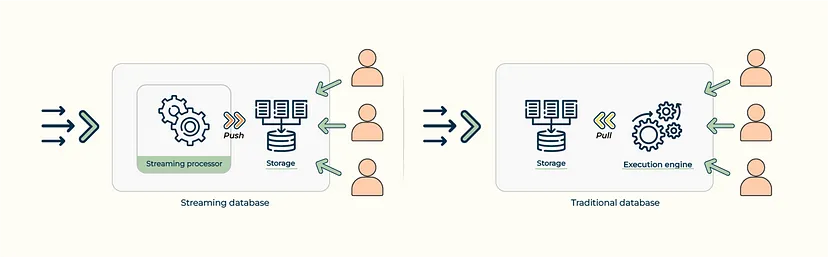
Традиційні бази даних призначені для зберігання великих обсягів пакетних даних і забезпечення швидкого, послідовного доступу до них за допомогою транзакцій і запитів. Вони часто оптимізовані для обробки складних операцій, таких як агрегації та об’єднання, які маніпулюють великими масивами даних. Моделі виконання традиційних баз даних часто називають моделями “Human-Active, DBMS-пасивна” (HADP). Тобто традиційна база даних пасивно зберігає дані, а запити, активно ініційовані людиною, запускають обчислення. Прикладами традиційних баз даних є OLTP-бази даних, такі як MySQL і PostgreSQL, та OLAP-бази даних, такі як DuckDB і ClickHouse.
Потокові бази даних, з іншого боку, призначені для поступової обробки великого обсягу даних, що безперервно надходять “на льоту”, і забезпечують доступ до даних і результатів з низькою затримкою для подальшої обробки та аналізу. Вони оптимізовані для обробки даних одразу після їх надходження, а не для масової обробки після збереження даних. Моделі виконання потокових баз даних часто називають моделями DBMS-active, Human-Passive (DAHP). Потокова база даних активно запускає обчислення по мірі надходження даних, а людина пасивно отримує результати з бази даних. Прикладами потокових баз даних є PipelineDB, KsqlDB та RisingWave.
Потокові бази даних проти OLTP-баз даних
OLTP-база даних сумісна з ACID і може обробляти паралельні транзакції. На відміну від них, потокові бази даних не гарантують відповідності стандарту ACID і, отже, не можуть використовуватися для підтримки транзакційних навантажень. З точки зору коректності даних, потокові бази даних забезпечують узгодженість і повноту даних. Добре спроектована потокова база даних повинна гарантувати наступні дві властивості:
- Семантика “точно один раз” означає, що кожна подія даних буде оброблена один і тільки один раз, навіть якщо станеться збій системи.
- Позачергова обробка означає, що користувачі можуть змусити потокову базу даних обробляти події даних у заздалегідь визначеному порядку, навіть якщо події даних надходять позачергово.
Потокові бази даних проти OLAP-баз даних
База даних OLAP оптимізована для ефективної відповіді на аналітичні запити, ініційовані користувачем. Бази даних OLAP зазвичай реалізують стовпчикові сховища і векторний механізм виконання для прискорення обробки складних запитів до великих обсягів даних. Бази даних OLAP найкраще підходять для випадків використання, коли інтерактивні запити є важливими. На відміну від OLAP-баз даних, потокові бази даних більше зосереджені на свіжості отриманих даних і використовують інкрементну модель обчислень для оптимізації затримок. Потокові бази даних зазвичай не використовують сховища стовпців, але можуть реалізовувати векторне виконання для обробки запитів.
ВИСНОВОК
Отже, потокові бази даних є важливою системою для організацій, які потребують аналізу великих обсягів даних у режимі реального часу. Забезпечуючи обробку в режимі реального часу, масштабованість і надійність, потокові бази даних можуть допомогти організаціям приймати кращі рішення, виявляти можливості і реагувати на загрози в режимі реального часу.
Відмова від відповідальності: Автор статті працює в RisingWave Labs і обговорює їхній продукт або послугу в цьому контенті. Погляди та думки, висловлені в цій статті, належать автору і призначені для надання інформативної інформації при просуванні RisingWave. Будь ласка, враховуйте зв’язок автора з RisingWave Labs при оцінці контенту.
ОРИГІНАЛ СТАТТІ:What Is a Streaming Database?
АВТОР СТАТІ:RisingWave Labs
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X:


