
Спочатку
Залежно від характеристик та вимог до даних, не завжди можна вирішити проблему за допомогою одного лише підходу до моделювання даних, але краще моделювати дані таким чином, щоб вони відповідали характеристикам та вимогам даних у кожному конкретному випадку.
Отже, те, про що я буду говорити тут, – це лише приклад того, як нам вдалося успішно відповісти на характеристики та вимоги даних, відмовившись від використання моделювання даних SCD замість використання SCD в моделюванні даних, тому я сподіваюся, що ви прочитаєте це лише як довідку.
Про що ми говоримо тут
- Розробка та експлуатація відповідно до SCD з використанням dbt
- Про підхід до зупинки SCD
Про що ми тут не говоримо
- Основний опис SCD
- Огляд базового моделювання даних
- Збір вихідних даних та управління ними
припущення
Далі я розгляну наступні характеристики даних та вимоги до моделювання.
- Інформація та факти, які вже виміряні та узагальнені в кожному записі журналу подій
- Вимоги до моделювання
Я хочу робити щоденну агрегацію KPI.
-Сегменти нарізаються за наступною інформацією
-Користувачі
-Регіон
Я буду використовувати публічні дані GA4, надані Google (далі – публічні дані), як приклад даних, що відповідають цим вимогам.

Приклад моделювання даних
Ці публічні дані – це дані сайту ЄК, згенеровані з GA4.
Один запис повинен містити наступні колонки.
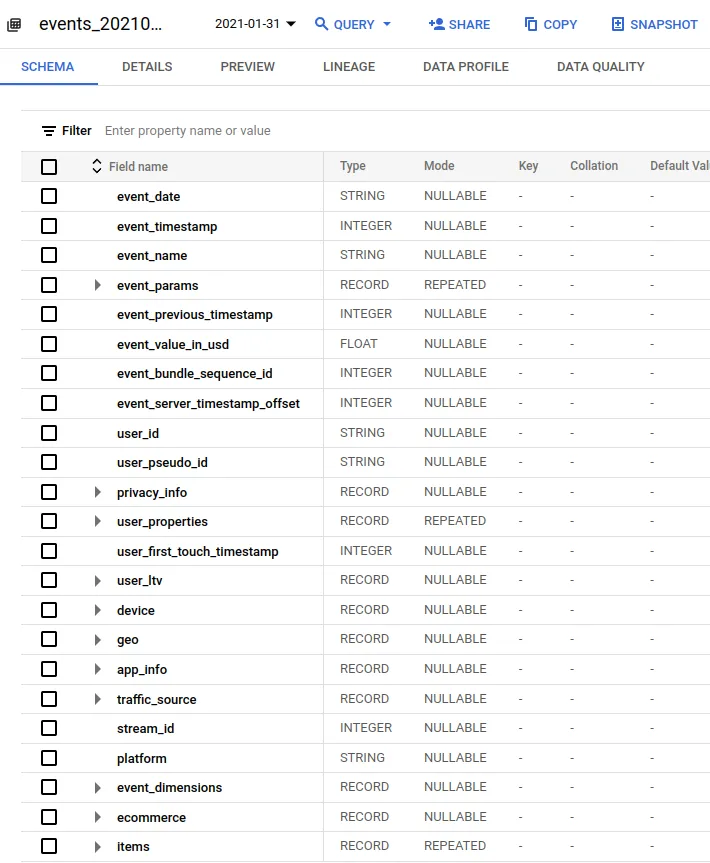
Ці колонки можна підсумувати наступним чином.
- Мітки часу подій
- Метадані сторінки
- Доступ до інформації про користувача
- Інформація про пристрій
- Географічна інформація
- Дані про дорожній рух
- Інформація про елементи сайту ЄС
На основі наведених вище даних я змоделюю дані про доступ користувачів, щоб розрахувати DAU і розбити їх на наступні сегменти.
- Інформація про користувача
- Реакція користувачів
На малюнку нижче показано моделювання даних, яке я створив для прикладу.
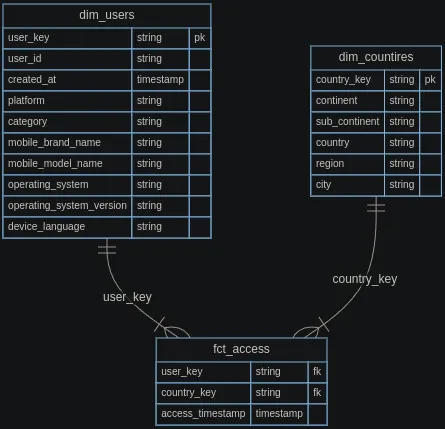
На основі цього моделювання даних можна розрахувати наступні метрики, наприклад
- DAU/WAU/MAU
- RR
і т.д…
Подальший аналіз можна провести, сегментувавши ці метрики за вимірами.
Зіркова схема + реалізація SCD з dbt
При реалізації Star Schema та SCD в dbt першим вибором є snapshot, стандартна функція dbt, яка підтримує реалізацію відповідно до SCD Type2.
Знімок – це функція, яка дозволяє обробляти SCD Type2 шляхом простого написання коду, подібного до інших моделей dbt, і розміщення необхідних елементів для знімка в конфігурації цієї моделі.
Наведемо конкретний приклад, якщо ви хочете створити вимір інформації про користувача, ви можете реалізувати його, написавши наступним чином.
{% snapshot dim_scd__users %}
{{
config(
target_schema=target.schema,
target_database=target.project,
unique_key="user_key",
strategy="timestamp",
updated_at="updated_at"
)
}}
select
{{ dbt_utils.generate_surrogate_key(['user_id', 'created_at']) }} as user_key,
user_id,
created_at,
platform,
device.category,
device.mobile_brand_name,
device.mobile_model_name,
device.operating_system,
device.operating_system_version,
device.language as device_language,
max(event_timestamp) as updated_at
from
{{ ref('stg__events') }}
where
date(event_timestamp) = "{{ var('date') }}"
group by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
{% endsnapshot %}sТепер dbt знімок або dbt збірка будуть оброблятися внутрішньо dbt відповідно до SCD Type2.
Крім того, реалізація Star Schema завершується впровадженням таблиці фактів, яку можна об’єднати з таблицею розмірів.
with
import_stg as (
select * from {{ ref('stg__events') }} where date(event_timestamp) = "{{ var('date') }}"
),
import_dim_users as (
select * from {{ ref('dim_scd__users') }} where date(dbt_valid_to) is null
)
select
import_dim_users.user_key,
import_stg.event_timestamp as access_timestamp,
import_stg.event_timestamp
from
import_stg
inner join
import_dim_users
on
import_stg.user_id = import_dim_users.user_id
and import_stg.created_at = import_dim_users.created_atКрім того, прийнявши інкремент як матеріалізоване значення таблиці фактів, можна зберігати дані відповідно до тонкої деталізації доступу.
Міркування щодо впровадження зі знімком
Як згадувалося вище, знімок можна використовувати для простої реалізації розмірних таблиць.
Знімок реалізовано у двох режимах (у dbt-знімку це називається “стратегія”), де процес додавання даних виконується шляхом аналізу відмінностей у деяких стовпчиках у внутрішньому процесі.
- мітка часу: додає дані на основі стовпців, які представляють оновлення даних, наприклад, оновлені на
- check: Об’єднує значення декількох стовпців і додає дані, якщо є різниця.
(Дата оновлення даних автоматично вводиться як дата, що обробляється в реальності, тому може бути введена ненавмисна дата оновлення).
Якщо джерело має значення, які можуть відображати зміни в даних, його можна реалізувати за допомогою знімка “як є” (snapshot as is).
Як показано на малюнку нижче, функціональність, що гарантується, залежить від рівня джерела, з яким ви працюєте.
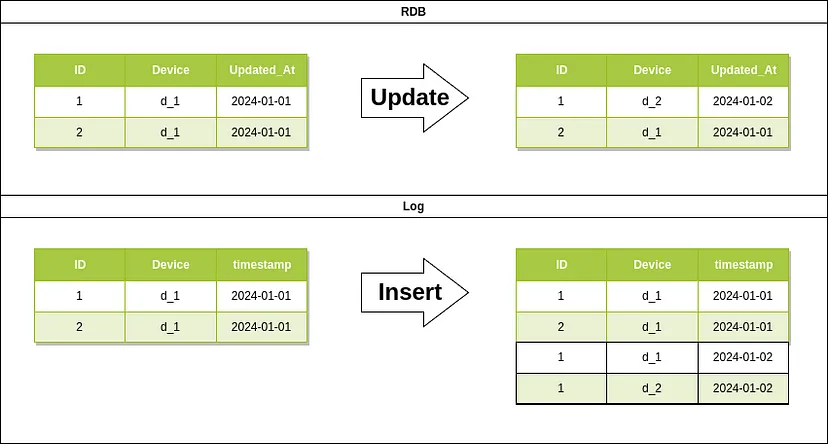
- При використанні RDB як джерела, оновлення даних гарантується на стороні RDB.
- У випадку журналів дані лише додаються до журналу, тому важко бути впевненим, які дані були оновлені і які дані є правильними на момент обробки.
Це означає, що моментальні знімки можна без проблем розгортати для розмірностей з RDB-джерел, але для розмірностей з журналів необхідно додати процес перед процесом створення знімка, як це робиться для RDB-джерел.
Прикладом процесу, який слід додати, є самозвернення до таблиці розмірів для перевірки відмінностей.
{% snapshot dim_scd__users %}
{{
config(
target_schema=target.schema,
target_database=target.project,
unique_key="user_key",
strategy="timestamp",
updated_at="updated_at"
)
}}
with
base as (
select
{{ dbt_utils.generate_surrogate_key(['user_id', 'created_at']) }} as user_key,
user_id,
created_at,
platform,
device.category,
device.mobile_brand_name,
device.mobile_model_name,
device.operating_system,
device.operating_system_version,
device.language as device_language,
max(event_timestamp) as updated_at
from
{{ ref('stg__events') }}
where
date(event_timestamp) = "{{ var('date') }}"
group by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
)
select
base.*
from
base
left join
-- In dbt, {{ this }} is an internal process that performs self-referencing
{{ this }} as prev_dim
on
base.user_key = prev_dim.user_key
-- Narrow down the data that is not in the self-referenced table in the subsequent where.
where
prev_dim.user_key is null
or (
base.platform || base.category || base.mobile_brand_name || base.operating_system || base.operating_system_version || base.device_language !=
prev_dim.platform || prev_dim.category || prev_dim.mobile_brand_name || prev_dim.operating_system || prev_dim.operating_system_version || base.device_language
)
{% endsnapshot %}Таким чином, деякі характеристики даних можуть не підтримуватися лише функцією моментальних знімків.
Розробка та експлуатація з використанням SCD
Існують різні міркування при розробці та експлуатації, які включають в себе і сам SCD.
міркування
розвиток
- Чи достатньо стовпчика, який бере різницю?
- Обробка, яка зберігає ідемпотентність.
- Узгодженість дат у таблицях розмірностей і фактів, що об’єднуються.
- Розглянемо вплив на унікальність при додаванні стовпців до існуючої розмірної таблиці під час роботи.
В експлуатації
- При повторній обробці минулої обробки необхідно обробляти до останньої дати, щоб зберегти ідемпотентність.
- При оновленні ключів, що використовуються для з’єднання таблиць розмірностей, пов’язані з ними таблиці фактів також повинні бути оновлені.
Приклад розробки/експлуатації
Як приклад, я поясню конкретну розробку та роботу з використанням відкритих даних.
1.Розкладає стовпці публічних даних на виміри та факти.
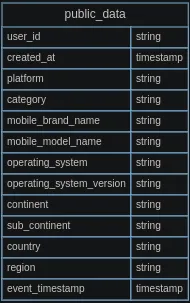
Наведена вище таблиця відповідає першоджерелу, тож давайте розбиваємо її наступним чином.

2.Визначте ключі, щоб можна було об’єднати декомпоновані виміри та факти
- Визначення ключів дозволяє виразити, що дані, які ви маєте у вимірі, є унікальними.
- Наприклад, для dim_users створіть сурогатний ключ за допомогою функції dbt_utils.generate_surrogate_key для user_id і created_at.
- Створюйте моделі даних, враховуючи два вищезгадані пункти.
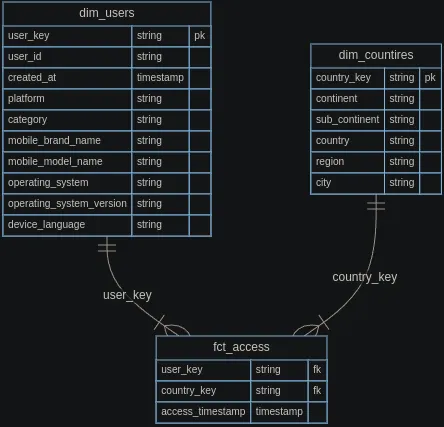
3.Впровадити процес перевірки розбіжностей у розмірах
Зразок коду.
{% snapshot dim_scd__users %}
{{
config(
target_schema=target.schema,
target_database=target.project,
unique_key="user_key",
strategy="timestamp",
updated_at="updated_at"
)
}}
with
base as (
select
{{ dbt_utils.generate_surrogate_key(['user_id', 'created_at']) }} as user_key,
user_id,
created_at,
platform,
device.category,
device.mobile_brand_name,
device.mobile_model_name,
device.operating_system,
device.operating_system_version,
device.language as device_language,
max(event_timestamp) as updated_at
from
{{ ref('stg__events') }}
where
date(event_timestamp) = "{{ var('date') }}"
group by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
)
select
base.*
from
base
left join
-- In dbt, {{ this }} is an internal process that performs self-referencing
{{ this }} as prev_dim
on
base.user_key = prev_dim.user_key
-- Narrow down the data that is not in the self-referenced table in the subsequent where.
where
prev_dim.user_key is null
or (
base.platform || base.category || base.mobile_brand_name || base.operating_system || base.operating_system_version || base.device_language !=
prev_dim.platform || prev_dim.category || prev_dim.mobile_brand_name || prev_dim.operating_system || prev_dim.operating_system_version || base.device_language
)
{% endsnapshot %}4.Замінник ключа таблиці фактів можна отримати, з’єднавши таблицю розмірностей зі стовпчиком, який використовувався для створення замінника ключа таблиці розмірностей.
Приклад коду
with
import_stg as (
select * from {{ ref('stg__events') }} where date(event_timestamp) = "{{ var('date') }}"
),
import_dim_users as (
select * from {{ ref('dim_scd__users') }} where date(dbt_valid_from) <= "{{ var('date') }}"
),
import_dim_countries as (
select * from {{ ref('dim_scd__countries') }} where date(dbt_valid_from) <= "{{ var('date') }}"
),
-- Refer to the latest data at a limited time with a specific surrogate key
get_latest_dim_users as (
select
import_dim_users.*
from
import_dim_users
inner join
(
select
user_key,
max(dbt_valid_from) latest_from
from
import_dim_users
group by 1
) as latest_data
on
import_dim_users.user_key = latest_data.user_key
and import_dim_users.dbt_valid_from = latest_data.latest_from
),
-- Refer to the latest data at a limited time with a specific surrogate key
get_latest_dim_countries as (
select
import_dim_countries.*
from
import_dim_countries
inner join
(
select
country_key,
max(dbt_valid_from) latest_from
from
import_dim_countries
group by 1
) as latest_data
on
import_dim_countries.country_key = latest_data.country_key
and import_dim_countries.dbt_valid_from = latest_data.latest_from
)
select
get_latest_dim_users.user_key,
get_latest_dim_countries.country_key,
import_stg.event_timestamp as access_timestamp,
import_stg.event_timestamp
from
import_stg
inner join
get_latest_dim_users
on
import_stg.user_id = get_latest_dim_users.user_id
and import_stg.created_at = get_latest_dim_users.created_at
inner join
get_latest_dim_countries
on
import_stg.geo.continent = get_latest_dim_countries.continent
and import_stg.geo.sub_continent = get_latest_dim_countries.sub_continent
and import_stg.geo.country = get_latest_dim_countries.country
and import_stg.geo.region = get_latest_dim_countries.region
and import_stg.geo.city = get_latest_dim_countries.city5.Нарешті, отримайте значення, необхідні для факту, з даних і збережіть їх у таблиці фактів.
Ви можете розробляти виміри та факти з публічних даних, використовуючи вищеописані кроки.
Ви можете додавати розмірні таблиці та стовпці, виконуючи ті ж самі кроки під час роботи.
Припинив вживати SCD
Підсумовуючи наведені вище пояснення, розробка та експлуатація з використанням СКД, як правило, не може гарантувати узгодженість таблиць розмірів, якщо впровадження та експлуатація не враховують оновлення даних, які відбуваються нерегулярно.
SCD може забезпечити ефективне використання ресурсів даних, таких як:
- Обсяг даних, що зберігаються, можна стиснути, оскільки додаються лише оновлені та нові виміри.
- Витрати на сканування запитів можна зменшити за рахунок обсягу збережених даних
Переваги, які можуть бути надані, зосереджені на ефективному використанні, тому можна вважати, що витрати на розробку та експлуатацію не враховуються.
Іншими словами, якщо витрати на розробку та експлуатацію вважаються вищими, ніж витрати на ефективне використання, існує також метод моделювання даних без застосування SCD.
Зіркова схема, яка не запроваджує SCD, може забезпечити наступні переваги для розвитку та експлуатації.
- Процес перевірки відмінностей можна опустити при застосуванні розмірних таблиць.
- Легше підтримувати узгодженість, оскільки деталізація оновлення таблиць фактів і розмірностей збігається.
- Повторна обробка, наприклад, засипка, більше не руйнує хронологічний порядок вимірів.
Впровадження, яке зупинило SCD
Я підсумував, що потрібно враховувати при впровадженні Star Scheme без використання SCD.
- Узгодження деталізації оновлення таблиць розмірностей і таблиць фактів
- Переглядайте тільки дані вимірювань за той самий день і не враховуйте відмінності з минулими даними.
- Таблиці розмірів, на які посилаються таблиці фактів, об’єднуються посиланням на ту саму дату обробки.
Наведені вище міркування є лише реалізацією; описане вище моделювання даних залишається незмінним незалежно від SCD.
Як функцію dbt можна змінити наступним чином.
- Виключено обробку за допомогою dbt-знімків.
- Процес перевірки відмінностей від самопосилань таблиць розмірів більше не потрібен.
- Таблиці розмірів також можна змінити на інкрементну модель dbt.
- Таблиця фактів повинна мати можливість посилатися і приєднувати розмірні таблиці тільки з того ж дня.
Код нижче є фактичною реалізацією всього цього.dim__users
with
import_stg as (
select *
from {{ ref('stg__events') }}
{% if not(var('backfill')) -%}
where
date(event_timestamp) = "{{ var('date') }}"
{%- endif %}
),
get_daily_values as (
select
date(event_timestamp) date,
user_id,
created_at,
platform,
device.category,
device.mobile_brand_name,
device.mobile_model_name,
device.operating_system,
device.operating_system_version,
device.language as device_language,
max(event_timestamp) as updated_at
from
import_stg
group by 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
)
select
{{ dbt_utils.generate_surrogate_key(['user_id', 'created_at', 'updated_at']) }} as user_key,
*
from
get_daily_valuesdim__countries
with
import_stg as (
select *
from {{ ref('stg__events') }}
{% if not(var('backfill')) -%}
where
date(event_timestamp) = "{{ var('date') }}"
{%- endif %}
),
get_daily_values as (
select
date(event_timestamp) date,
geo.continent,
geo.sub_continent,
geo.country,
geo.region,
geo.city,
max(event_timestamp) as updated_at
from
import_stg
group by 1, 2, 3, 4, 5, 6
)
select
{{ dbt_utils.generate_surrogate_key(['continent','sub_continent','country','region','city','updated_at']) }} as country_key,
*
from
get_daily_valuesfct__access
with
import_stg as (
select *
from {{ ref('stg__events') }}
{% if not(var('backfill')) -%}
where
date(event_timestamp) = "{{ var('date') }}"
{%- endif %}
),
import_dim_users as (
select *
from {{ ref('dim__users') }}
{% if not(var('backfill')) -%}
where
date(updated_at) = "{{ var('date') }}"
{%- endif %}
),
import_dim_countries as (
select *
from {{ ref('dim__countries') }}
{% if not(var('backfill')) -%}
where
date(updated_at) = "{{ var('date') }}"
{%- endif %}
)
select
import_dim_users.user_key,
import_dim_countries.country_key,
import_stg.event_timestamp as access_timestamp,
import_stg.event_timestamp
from
import_stg
inner join
import_dim_users
on
import_stg.user_id = import_dim_users.user_id
and import_stg.created_at = import_dim_users.created_at
and date(import_stg.event_timestamp) = date(import_dim_users.updated_at)
inner join
import_dim_countries
on
import_stg.geo.continent = import_dim_countries.continent
and import_stg.geo.sub_continent = import_dim_countries.sub_continent
and import_stg.geo.country = import_dim_countries.country
and import_stg.geo.region = import_dim_countries.region
and import_stg.geo.city = import_dim_countries.city
and date(import_stg.event_timestamp) = date(import_dim_countries.updated_at)Навіть у порівнянні з таблицею вимірів користувача та таблицею фактів, згаданими вище, ви можете побачити, що тут реалізовано значно менше коду.
Порівняно зі зразком коду, я зміг скоротити код, як показано нижче.
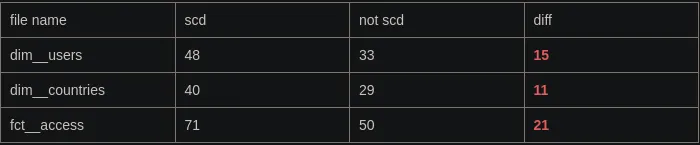
Загалом збережено 47 рядків коду всього у 3 файлах.
Окрім простих порівнянь чисел, внутрішня логіка також залишилася чистою.
Наступні зміни були зроблені в коді без SCD:
- Перевірка відмінностей від самопосилань не проводиться
- Послідовна обробка в хронологічному порядку від вихідної дати пропущена.
- Обробка засипки може виконуватися без фільтрації розділів.
З вищесказаного випливає, що можна зменшити витрати на розробку та експлуатацію, запровадивши моделювання даних без SCD для таких характеристик даних, як публічні дані, згадані в прикладі.
Будь ласка, зверніться до github для детального опису yaml-файлів та структури каталогів.
Підсумок
Хоча SCD сприяє ефективному управлінню ресурсами залежно від характеристик даних, цілісність даних може бути порушена, якщо операції з розробки та експлуатації не структуровані відповідно до цих міркувань.
Обробку, необхідну для впровадження SCD, можна оминути, просто використовуючи функцію моментальних знімків dbt, але якщо на стороні джерела немає функції, яка б забезпечувала оновлення даних, то в процесі ELT виникне необхідність у додатковому впровадженні.
Якщо ви приділяєте більше уваги розробці та експлуатаційним витратам, ніж управлінню ресурсами, впровадження моделювання даних, яке не використовує SCD, полегшить реалізацію, яка підтримує цілісність даних, оминаючи міркування, що вимагаються при використанні SCD.
Крім того, я вважаю, що нові інструменти, такі як dbt, допоможуть підвищити швидкість і точність цих розробок, а також є інструментами, які можуть ефективно впроваджувати скрап- і білд-моделювання даних.
Як я вже згадував на початку, я вважаю, що розгляд і впровадження моделювання даних, яке відповідає характеристикам і вимогам даних, призведе до кращої реалізації конвеєра даних.
Дякую, що дочитали до кінця.
Посилання
- https://maximebeauchemin.medium.com/functional-data-engineering-a-modern-paradigm-for-batch-data-processing-2327ec32c42a
- https://medium.com/@rchang/a-beginners-guide-to-data-engineering-part-ii-47c4e7cbda71
- https://medium.com/@aaronbannin/dbt-incremental-cookbook-d70331ef879a
ОРИГІНАЛ СТАТТІ:Why I stopped using SCD in my data modeling.
АВТОР СТАТІ:cafenoctia
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


