На цій сторінці
- Розрахунок LTV: Купуй, поки не помреш
- Як користуватися електронною таблицею Google
- Моделюйте та прогнозуйте майбутні покупки клієнтів
- Оцініть своїх клієнтів
- Винагороджуйте своїх найкращих клієнтів
Цінність життя клієнта (Customer Lifetime Value, LTV) – це сума грошей, яку окремий клієнт витратить на даний бізнес у майбутньому. Цей показник часто використовується для оцінки когорти клієнтів у вашій клієнтській базі, визначення того, скільки потрібно витратити на залучення або утримання нових користувачів у даній когорті, ранжування клієнтів і вимірювання успіху маркетингових заходів на основі базового прогнозу LTV.
Розрахунок LTV не є простим для підприємств електронної комерції, оскільки майбутні платежі не є договірними: у будь-який момент клієнт може більше ніколи не здійснити жодної покупки. Крім того, прогнозування майбутніх покупок вимагає статистичного моделювання, якого бракує багатьом сучасним формулам LTV.
Цей посібник показує, як розрахувати прогнозну LTV для неконтрактного бізнесу за допомогою SQL та Excel. Даний аналітичний підхід дозволить вам точно оцінити ваших найцінніших клієнтів, а також спрогнозувати розмір їхніх майбутніх покупок, що допоможе сфокусувати ваші маркетингові зусилля.
Посібник передбачає, що ви використовуєте схему відстеження, описану в розділі Як впровадити план відстеження електронної комерції, і зберігаєте дані в сховищі сегментів.
Поговоріть з фахівцем з продукту, щоб дізнатися, як такі компанії, як Warby Parker і Crate & Barrel, використовують сховище даних для підвищення залученості та продажів.
Розрахунок LTV: Купуй, поки не помреш
У бездоговірному середовищі ви не можете використовувати простий коефіцієнт утримання, щоб визначити, коли клієнти припиняють свої стосунки. Це пов’язано з тим, що коефіцієнт утримання є лінійною моделлю, яка не може точно передбачити, чи закінчив клієнт свої відносини з компанією, чи просто перебуває в розпалі тривалої перерви між транзакціями.
Найточніша позадоговірна модель LTV під назвою “Купуй, поки не помреш” (BTYD – Buy Till You Die) зосереджена на розрахунку дисконтованої оцінки майбутніх покупок на основі давності останньої покупки, частоти покупок і середньої вартості покупки. Ця модель використовує нелінійне моделювання для прогнозування того, чи є користувач “живим” або “мертвим”, враховуючи історичні транзакції для прогнозування майбутньої ймовірності та розміру покупок.
Оскільки LTV є критично важливим показником для компаній електронної комерції, важливо, щоб для його розрахунку використовувалася саме ця модель, а не простіша лінійна формула, яка базується на коефіцієнті утримання.
За допомогою SQL створіть необхідну таблицю, яка буде експортована у форматі CSV і відкрита в Google Таблицях. Потім використовуйте Solver для оцінки параметрів прогнозної моделі, яка в кінцевому підсумку розраховує майбутні покупки кожного клієнта. Нарешті, розрахунок LTV – це просто чиста теперішня вартість майбутніх покупок кожного клієнта. Проранжуйте їх за LTV, а потім знайдіть поведінкові патерни для 10 або 50 найбільших клієнтів, щоб зрозуміти, як найкраще таргетувати або утримувати цю когорту.
Недавність, частота та середній розмір
Як аналітику з питань зростання у вигаданій компанії Toastmates, що займається кустарними тостами на замовлення, важливо знати, які клієнти є більш цінними для бізнесу, ніж інші. Найголовніше, ви повинні розуміти, які спільні риси мають всі ці клієнти, щоб допомогти маркетинговій команді спрямувати свої зусилля.
Першим кроком у створенні моделі BTYD є отримання історичних даних про покупки щонайменше за місяць. У своєму аналізі ви можете використовувати дані за останні шість місяців. Дані повинні містити стовпці userId (email також підійде), кількість покупок за вказаний проміжок часу, кількість днів з моменту останньої покупки та кількість днів з моменту першої покупки.
Потім використовуйте цей аркуш Google, який забезпечує всі складні розрахунки для оцінки параметрів моделі, а також прогнозування майбутніх продажів кожного покупця. Цей аркуш доступний лише для перегляду, тому обов’язково скопіюйте його повністю, щоб мати змогу ним користуватися.
Щоб отримати таблицю з потрібними для аналізу стовпчиками, скористайтеся наступним SQL-запитом:
with
first_transaction as (
select u.email,
datediff('day', min(oc.received_at)::date, current_date) as first
from toastmates.order_completed oc
left join toastmates.users u
on oc.user_id = u.email
where oc.received_at > dateadd('month', -6, current_date)
group by 1
),
frequency as (
select u.email,
count(distinct oc.checkout_id) as frequency
from toastmates.order_completed oc
left join toastmates.users u
on oc.user_id = u.email
where oc.received_at > dateadd('month', -6, current_date)
group by 1
),
last_transaction as (
select u.email,
datediff('day', max(oc.received_at)::date, current_date) as last
from toastmates.order_completed oc
left join toastmates.users u
on oc.user_id = u.email
where oc.received_at > dateadd('month', -6, current_date)
group by 1
),
average_transaction_size as (
select u.email,
avg(oc.total) as avg
from toastmates.order_completed oc
left join toastmates.users u
on oc.user_id = u.email
where oc.received_at > dateadd('month', -6, current_date)
group by 1
order by 2 desc
)
select distinct
u.email,
nvl(f.frequency, 0) as frequency,
nvl(z.last, 0) as days_since_last_transaction,
nvl(a.first, 0) as days_since_first_transaction,
t.avg as average_transaction_size
from toastmates.users u
left join first_transaction a
on u.email = a.email
left join frequency f
on u.email = f.email
left join last_transaction z
on u.email = z.email
left join average_transaction_size t
on u.email = t.email
order by 2 descВін повертає таблицю, де кожен рядок – це унікальний користувач, а стовпці – електронна пошта, кількість покупок у часовому вікні, кількість дискретних одиниць часу з моменту останньої покупки та середнє замовлення на покупку.

Ось скріншот перших дванадцяти рядків, отриманих в результаті запиту в Mode Analytics.
Експортуйте ці дані у формат CSV, а потім скопіюйте і вставте їх на перший аркуш Google Таблиці, де на скріншоті нижче вказано синій тип:
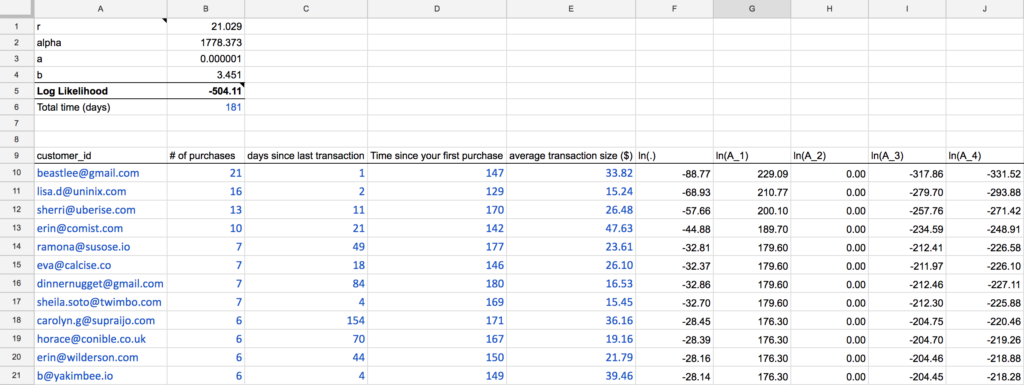
Також не забудьте додати загальний час у днях у комірку B6. Це важливо, оскільки на другому аркуші ця тривалість часу використовується для розрахунку чистої теперішньої вартості майбутніх платежів.
Як користуватися електронною таблицею Google
Після того, як ви вставили CSV-файл з таблиці на першу вкладку аркуша, наступним кроком є оцінка параметрів моделі (змінні у верхньому лівому куті аркуша). Для цього нам потрібно скористатися функцією Microsoft Excel, яка називається “Розв’язувач”.
Ви можете експортувати свій Google Таблиця як документ Excel. Потім, використовуйте Excel Solver, щоб мінімізувати число лог-правдоподібності в комірці B5, зберігаючи параметри з B1:B4 більшими за 0,0001.
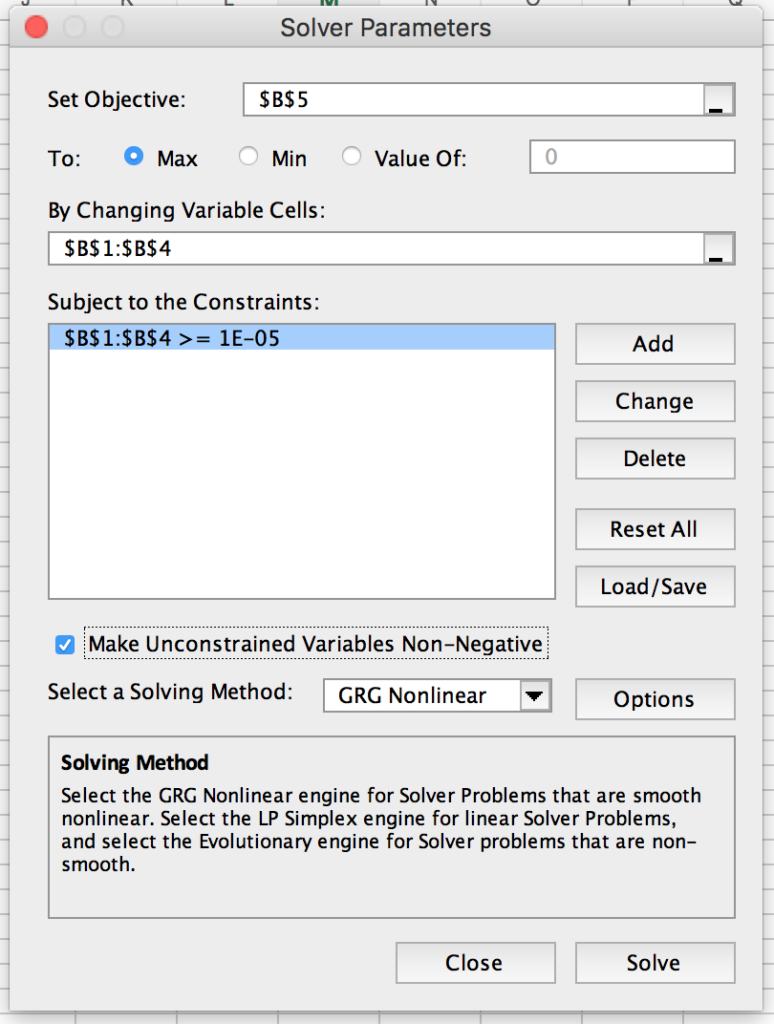
Після запуску Solver клітинки B1:B4 будуть оновлені, щоб представити оцінки моделі. Тепер ви можете вставити їх назад у таблицю в Google Таблицях. На наступному аркуші на основі цих модельних оцінок обчислюються очікувані покупки для кожного клієнта.
Моделюйте та прогнозуйте майбутні покупки клієнтів
Модель вимагає чотири елементи інформації про минулу історію покупок кожного клієнта: “недавність” (скільки “одиниць часу” минуло з моменту останньої транзакції), “частота” (скільки транзакцій вона здійснила за вказаний період часу), тривалість періоду, протягом якого ми спостерігали за її купівельною поведінкою, та середній розмір транзакції.
У прикладі ви маєте дані про купівельну поведінку протягом шести місяців, кожна одиниця часу – один день.
Ви можете застосувати як бета-геометричний, так і негативний біноміальний розподіл (“BG/NBD”) до цих вхідних даних, а потім використати Excel для оцінки параметрів моделі (альтернативою може бути модель Парето/NBD). Ці розподіли ймовірностей використовуються тому, що вони точно відображають основні припущення щодо сукупності реалістичної індивідуальної купівельної поведінки. (Дізнайтеся більше про ці моделі).
Оцінивши параметри моделі, ви можете спрогнозувати умовні очікувані транзакції конкретного клієнта, застосувавши ті ж самі історичні дані про покупки до теореми Байєса, яка описує ймовірність події на основі попереднього знання умов, пов’язаних з цією подією.
Оцінка параметрів моделі
У верхній лівій частині першого аркуша наведено параметри моделі BG/NBD, які потрібно підігнати до історичних даних, які ви вставите. Ці чотири параметри (r, alpha, a і b) матимуть “початкові значення” 1.0, оскільки ви будете використовувати Excel Solver для визначення їх фактичних значень.
Значення в стовпчиках з F по J представляють змінні в моделі BG/NBD. Стовпчик F, зокрема, визначає внесок одного клієнта у загальну функцію, для визначення параметрів якої ми будемо використовувати Розв’язувач. У статистиці ця функція називається функцією правдоподібності, яка є функцією параметрів статистичної моделі.
У цьому конкретному випадку це функція логарифмічної правдоподібності, тобто B5, яка обчислюється як сума всіх клітинок у стовпчику F. З логарифмічними функціями легше працювати, оскільки вони досягають максимального значення в тих самих точках, що й сама функція. За допомогою Розв’язувача знайдіть максимальне значення B5 за параметрами у комірках B1:B4.
За допомогою нових оцінок параметрів ви можете прогнозувати майбутні покупки клієнта.
Прогнозування майбутніх покупок клієнта
На наступному аркуші ви можете застосувати теорему Байєса до історичної інформації про закупівлі, щоб спрогнозувати кількість транзакцій у наступному періоді. Помножте очікувану кількість на середній розмір транзакції, щоб розрахувати очікуваний дохід за цей період, який можна екстраполювати у вигляді ануїтету, з якого можна знайти теперішню дисконтовану вартість (припускаючи, що ставка дисконтування становить 10%).
Центральним елементом формули теореми Байєса є гіпергеометрична функція Гаусса, яка визначається як “2F1” у стовпчику M. Оцініть гіпергеометричну функцію, як якщо б вона була усіченим рядом: додаючи члени до ряду, доки кожен член не стане достатньо малим, щоб стати тривіальним. В електронній таблиці ми підсумовуємо ряд до 50-го члена.
Решта змінних у теоремі Байєса знаходиться у стовпчиках з I по L, в яких використовуються вхідні дані з історичної інформації про покупки клієнта, а також оцінки параметрів моделі, визначені за допомогою Solver (клітинки B1:B4).
Очікувана кількість покупок у наступному часовому періоді розраховується у колонці H.
Нарешті, помножте це на середній розмір транзакції і ви отримаєте очікуваний дохід на наступний період часу.
Оцініть своїх клієнтів
Ця вправа дозволяє вам ранжувати ваших клієнтів від найбільш цінних до найменш цінних, впорядковуючи стовпчик F у порядку спадання. Ви можете взяти userId кількох перших покупців і проаналізувати їхній досвід покупок, щоб виявити спільні для них шаблони і зрозуміти, яка поведінка є провідним індикатором того, що вони стають цінними покупцями.
Нижче наведено простий запит для отримання таблиці дій користувача в рядках. Просто замініть user_id відповідним користувачем.
with anonymous_ids as (
select anonymous_id from toastmates.tracks
where user_id = '46X8VF96G6'
group by 1
),
page_views as (
select *
from toastmates.pages p
where p.user_id = '46X8VF96G6'
or anonymous_id in (select anonymous_id from anonymous_ids)
order by p.received_at desc
),
track_events as (
select *
from toastmates.tracks t
where t.user_id = '46X8VF96G6'
or anonymous_id in (select anonymous_id from anonymous_ids)
order by t.received_at desc
)
select url,
received_at
from page_views
union
select event_text,
received_at
from track_events
order by received_at descНаведений вище запит для користувача з user_id "46X8VF96G6" повертає наступну таблицю:

У Toastmates більшість клієнтів з найвищим очікуваним LTV мають одну спільну рису: в середньому вони роблять два замовлення на місяць із середнім розміром покупки в $20.
Маючи це на увазі, ви можете визначити поведінкову когорту в нашому інструменті для email-розсилок Customer.io, а також створити тригерний робочий процес, щоб ми могли надіслати цим клієнтам пропозицію електронною поштою.
Винагороджуйте своїх найкращих клієнтів
Ця вправа корисна не лише як перспективна модель прогнозування LTV клієнта, але й як система ранжування якості, що дозволяє побачити, які клієнти є більш цінними для вашого бізнесу. У поєднанні з можливістю проаналізувати весь досвід покупок певного клієнта, ви можете виявити загальні закономірності або конкретні дії, які можуть бути раннім сигналом для високоцінного покупця. Розпізнати таких цінних покупців означає бути активним у їхньому вихованні, винагородженні та утриманні.
І це лише початок. Маючи багатий набір необроблених даних про клієнтів, ви можете створити точні прогнозні моделі для LTV, щоб знати не тільки, скільки ви можете витратити на їхнє залучення, але й як ранжувати клієнтів за їхньою цінністю. Зрештою, ці знання допоможуть вам ухвалювати правильні рішення, які сприятимуть створенню привабливого купівельного досвіду та збільшенню продажів.
Поговоріть з фахівцем з продукту, щоб дізнатися, як такі компанії, як Warby Parker і Crate & Barrel, використовують сховище даних для підвищення залученості та продажів.
ОРИГІНАЛ СТАТТІ:Forecasting LTV with SQL and Excel for E-Commerce
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook: