
Як інженер з обробки даних, я працював над численними проектами, де баланс між продуктивністю та вартістю був критично важливим завданням. Сьогодні я з радістю поділюся однією з найвпливовіших міграцій, яку завершила моя команда: перехід з Amazon Redshift на Amazon Athena. Цей перехід не тільки призвів до значного скорочення витрат на управління даними на 90%, але й значно підвищив продуктивність наших запитів. Якщо ви інженер даних, який стикається з подібними проблемами, ця стаття може стати для вас цінним джерелом інформації.
Контекст: Успадкування складної багатокористувацької інфраструктури
Коли наша команда інженерів з обробки даних розширилася, ми успадкували багатокористувацьку інфраструктуру, яка обслуговувала додаток на основі машинного навчання. Існуюча структура використовувала Redshift для зберігання та запиту даних, отриманих за допомогою ML-моделей, що робило їх доступними для програми, яка відповідала за надання даних нашим кінцевим клієнтам. Ці клієнти могли створювати фільтри та діаграми для аналізу своїх даних, що робило продуктивність нашої системи критично важливою для їхнього досвіду.
Існуюче налаштування Redshift спочатку було ефективним, але зі зростанням компанії та обсягів даних клієнтів воно почало давати тріщини під тиском.
Проблема: труднощі з масштабуванням та стрімке зростання витрат
Досліджуючи існуючу інфраструктуру, ми виявили кілька критичних проблем, які можуть здатися багатьом з вас знайомими:
- Погіршення продуктивності: Наш кластер Redshift не встигав за зростаючим обсягом даних. Процеси імпорту, які колись займали хвилини, тепер розтягувалися на години.
- Зростання витрат: Наші рахунки за AWS стрімко зросли, сягнувши $15,000 щомісяця лише за Redshift. Це ставало нестерпним.
- Обмежена гнучкість: Архітектура Redshift ускладнює незалежне масштабування певних операцій, що призводить до неефективного розподілу ресурсів.
- Оптимізація складних запитів: З ускладненням структури даних оптимізація запитів ставала все більш складним завданням, що впливало на швидкість відгуку нашого додатку.
Якщо ви киваєте, то ви не самотні. Це типові проблеми, з якими стикаються додатки, що працюють з великими обсягами даних.
Рішення: Перехід на безсерверні технології з Amazon Athena
Після ретельного аналізу наша команда запропонувала перейти з Redshift на Amazon Athena. AWS Athena стала для нас стратегічним вибором не лише як безсерверне рішення, але й як інструмент, що унікально підходить для вирішення проблем, з якими ми зіткнулися:
- Модель з оплатою за запит: Замість того, щоб платити за простої ресурсів, ми платили лише за запити, що значно скоротило витрати.
- Безсерверна архітектура: Відмова від управління інфраструктурою означала, що ми могли зосередитися на оптимізації продуктивності, а не на обслуговуванні обладнання.
- Прямий запит до S3: Запитуючи дані безпосередньо з S3, ми усунули трудомісткі ETL-процеси, які були основним вузьким місцем.
- Сумісність з SQL: Підтримка ANSI SQL в Athena дозволила нам використовувати існуючі навички нашої команди з мінімальними труднощами.
Міграційний процес: Технічне занурення
Наша міграція була складним процесом, який включав кілька ключових етапів. Ось більш детальний огляд того, що ми зробили:
1. Аналіз та оптимізація даних
Ми почали з ретельного аналізу структури даних, моделей використання та «температури» (частоти доступу). Цей аналіз показав, що значна частина наших даних була «холодною» – до неї нечасто звертаються, але вона необхідна для довгострокового аналізу та дотримання вимог.
Ми оптимізували наші дані для Athena за допомогою:
- Перетворення в стовпчасті формати, такі як Паркет
- Впровадження ефективної стратегії розмежування
- Видалення непотрібних таблиць і надлишкових даних
2. Архітектура Data Lake: Оптимізація для Athena
Наш перехід на Athena вимагав повного перепроектування архітектури нашого озера даних. Ось як ми структурували наше озеро даних в S3 для ефективної роботи з Athena:
Структура папок
Ми впровадили ієрархічну структуру папок, яка відповідає нашій стратегії розбиття на розділи. Ця структура дозволяє Athena ефективно використовувати обрізання розділів, значно зменшуючи обсяг даних, що скануються для кожного запиту, і підтримуючи вимоги до багатокористувацької роботи.
s3://our-data-lake/
├── tenant_id=01/
│ ├── kpis_samples/
│ │ ├── kpi_id=01/
│ │ │ ├── country_id=01/
│ │ │ │ ├── month_id=01/
│ │ │ │ │ ├── data_file_1.parquet
│ │ │ │ │ └── data_file_2.parquet
│ │ │ └── country_id=02/
│ │ └── kpi_id=02/
│ ├── stratum/
├── tenant_id=02/Зауваження Nicola Corda, будь ласка, майте на увазі:
Поганий розділ може призвести до високих витрат на S3 і Athena. Занадто багато об’єктів S3, які сканує Athena, може призвести до низьких витрат на Athena, але високих витрат на S3. Тому, будь ласка, не поспішайте визначати правильний розділ для ваших даних.
Формати файлів
Ми конвертували всі наші дані у формат Apache Parquet, який має низку переваг:
- Сховище зі стовпчиками для ефективних запитів
- Вбудоване стиснення
- Підтримка еволюції схем
Стиснення
Ми використовували стиснення Snappy для наших файлів Parquet, щоб досягти балансу між ступенем стиснення та продуктивністю запитів. Для деяких історичних даних ми використовували сильніше стиснення, наприклад, ZSTD, щоб заощадити на витратах на зберігання.
Перехід на стовпчикові формати, такі як Parquet, і впровадження розумної стратегії розбиття на розділи дозволили нам зменшити витрати на запити і підвищити продуктивність. Привівши структуру папок S3 у відповідність до шаблонів запитів, ми переконалися, що Athena сканує найменший можливий набір даних для кожного запиту, що значно зменшило наші операційні витрати.
3. Переклад схеми та оптимізація запитів
Адаптація наших схем Redshift для Athena була не просто перенесенням – вона вимагала ретельної оптимізації. Ми рефакторингували складні об’єднання та переписали запити, щоб повною мірою скористатися перевагами розподіленої моделі виконання Athena. Це включало в себе
- Переписування складних з’єднань для використання розподіленого виконання запитів в Athena
- Оптимізація використання функцій
Наприклад, нам довелося модифікувати функції дати:
-- Redshift
SELECT GETDATE(), DATEDIFF(day, event_date, GETDATE()) AS days_ago
FROM events;
-- Athena
SELECT current_date, date_diff('day', event_date, current_date) AS days_ago
FROM events;4.Вирішення технічних проблем
Під час міграції ми зіткнулися з кількома технічними проблемами. Модель виконання запитів в Athena вимагала переосмислення нашого підходу, особливо при роботі з великими наборами даних. Ми розробили спеціальні стратегії виконання запитів з використанням пагінації та суворих процесів перевірки даних для забезпечення їхньої цілісності. Кожен з цих викликів став можливістю для навчання, що поглибило наші знання в області безсерверних архітектур даних.
Цілісність даних: Ми впровадили суворі процеси контролю якості для перевірки перенесених і неперенесених даних, забезпечуючи точність протягом усього переходу.
5.Поступова міграція та налаштування продуктивності
Ми застосували поетапний підхід до міграції, переносячи дані поступово, щоб мінімізувати перебої в роботі наших сервісів. Це дозволило нам:
- Протестуйте та перевірте нашу нову систему на базі Athena з підмножиною даних
- Виявляйте та усувайте вузькі місця в роботі на ранній стадії процесу
- Поступово оптимізуємо шаблони запитів для архітектури Athena
- Впровадити сповіщення про моніторинг продуктивності
Результати та отримані уроки
Міграція перевершила наші очікування на всіх фронтах:
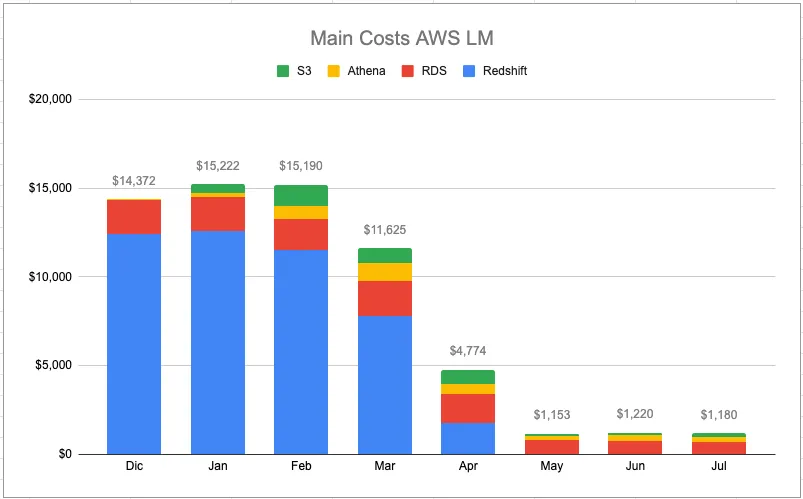
Як показано на Рисунку 1, наші щомісячні витрати на AWS різко зменшилися після міграції. Графік чітко ілюструє, як наша залежність від Redshift (показано синім кольором) значно зменшилася з часом, тоді як витрати на S3 та Athena (зелений та жовтий кольори відповідно) залишилися відносно низькими. Це візуальне представлення підкреслює значну економію коштів, якої ми досягли завдяки переходу на безсерверну архітектуру.
- Зниження витрат на 90%: Наші витрати на управління даними знизилися з $15 000 до приблизно $1 500 на місяць.
- Підвищення продуктивності: Продуктивність запитів, особливо для великих аналітичних навантажень, значно покращилася.
- Масштабованість: Безсерверна природа Athena дозволила нам легко масштабуватися, більше не обмежуючись інфраструктурними обмеженнями.
- Гнучкість та ефективність: Відокремивши сховище від обчислень, ми отримали більший контроль над розподілом ресурсів.
Основні висновки з цього досвіду включають:
- Знати свої дані: Розуміння «температури» ваших даних і моделей доступу до них має вирішальне значення для прийняття економічно ефективних архітектурних рішень.
- Безсерверна система змінює правила гри: Athena виявилася ідеальним рішенням для наших потреб у холодному зберіганні даних та спеціальному аналізі.
- Правильний інструмент для правильної роботи: Хоча Redshift чудово підходить для певних робочих навантажень, Athena виявилася ідеальним рішенням для поєднання холодного зберігання даних і спеціального аналізу.
- Постійна оптимізація: Регулярний перегляд і коригування нашої стратегії роботи з даними є ключовим фактором для підтримки продуктивності та економії коштів.
- Інвестуйте в тестування та моніторинг: Комплексні процедури тестування та моніторинг продуктивності в режимі реального часу мали вирішальне значення для забезпечення плавного переходу та постійної оптимізації.
Чому це важливо для інженерів даних
- Витрати на хмару – це велика проблема: якщо ви не оптимізуєте свою інфраструктуру даних, ви, швидше за все, перевитрачаєте кошти.
- Безсерверні технології набирають обертів: Ознайомлення з безсерверними рішеннями може дати вам значну перевагу на ринку праці.
- Ефективність має вирішальне значення: у сучасному швидкоплинному бізнес-середовищі здатність швидко надавати ідеї може зробити проект успішним або провалити його.
Ключові аспекти на майбутнє
Управління життєвим циклом даних
Одним із важливих кроків, які ми зробили, було впровадження політик життєвого циклу S3. Вони автоматично переносять дані, до яких нечасто звертаються (холодні дані), на більш економічно ефективні рівні зберігання, такі як Amazon S3 Glacier. Налаштувавши ці політики, ми можемо зберігати дані для дотримання нормативних вимог та архівування, не несучи високих витрат на зберігання даних, до яких часто звертаються. Така автоматизація не лише зменшує витрати, але й спрощує управління даними в міру їхнього старіння, забезпечуючи максимальну ефективність на кожному етапі життєвого циклу даних.
Athena не є базою даних
Хоча Athena зробила революцію в тому, як ми керуємо та запитуємо наші дані, швидко з’явилася одна проблема: Athena не є традиційною базою даних. Її безсерверна архітектура означає, що вона чудово справляється із запитами до даних, але не з керуванням постійними структурами, подібними до баз даних. Побачивши покращення продуктивності та економію коштів, багато команд захотіли використовувати Athena як реляційну базу даних. Це призвело до неефективних шаблонів запитів, таких як створення таблиць без належного розбиття і нехтування використанням речень WHERE, що спричинило непотрібне сканування даних і збільшило витрати на запити.
Не забудьте прочитати цю статтю
Щоб уникнути цієї пастки, важливо навчити користувачів найкращим практикам роботи в Athena. Це включає в себе розуміння важливості розбиття на розділи, використання оптимізованих форматів файлів, таких як Parquet, і постійне включення фільтрів для мінімізації обсягу даних, що скануються під час запитів. З мого досвіду, це постійне навчання було найскладнішим аспектом впровадження Athena, але воно має вирішальне значення для збереження довгострокових переваг безсерверної архітектури.
Подолання обмежень Афіни
Хоча Athena значно покращила наші можливості запиту даних, важливо пам’ятати про її обмеження і планувати відповідні дії для пом’якшення потенційних проблем:
- Складність запиту: Athena має обмеження на таймаут запитів у 30 хвилин. Для дуже складних запитів, які можуть наближатися до цього ліміту, ми створили рівень кешу в Postgres для методів попередньої агрегації, щоб оптимізувати продуктивність.
- Обмеження одночасності: За замовчуванням Athena має обмеження в 20 одночасних запитів на мові визначення даних (DDL) і 100 одночасних запитів на мові маніпулювання даними (DML) на один обліковий запис у регіоні (*ці ліміти можуть змінюватися залежно від регіону AWS). Ми впроваджуємо систему черг запитів для управління сценаріями з високим рівнем паралелізму та вивчаємо можливості збільшення лімітів, якщо це необхідно.
Висновок: Прийняття майбутнього інженерії даних
Наш перехід з Redshift на Athena був не просто заходом економії коштів; це був фундаментальний зсув у підході до інженерії даних. Використовуючи безсерверні технології та постійно оптимізуючи нашу інфраструктуру даних, ми не лише зменшили витрати, але й покращили нашу здатність надавати цінність нашим клієнтам завдяки швидшим та гнучкішим можливостям аналізу даних.
Оскільки обсяги даних продовжують зростати, а потреба в економічно ефективних, масштабованих рішеннях збільшується, ми вважаємо, що безсерверна інженерія даних буде відігравати все більш важливу роль у формуванні майбутнього нашої галузі. Цей проект зміцнив пристрасть нашої команди до вирішення складних проблем з даними та пошуку інноваційних рішень, які сприяють як технічній досконалості, так і підвищенню цінності бізнесу.
Якщо ви стикаєтеся з подібними проблемами або просто прагнете бути на крок попереду, ми сподіваємося, що наш досвід надасть вам цінну інформацію для вашої власної подорожі в галузі інженерії даних. Пам’ятайте, що у світі даних стояти на місці – означає рухатися назад. Продовжуйте вчитися, оптимізуйте та не бійтеся кидати виклик статусу кво.
Простою мовою 🚀
Дякуємо, що ви є частиною спільноти In Plain English Перш ніж ви підете:
- Обов’язково плескайте та слідкуйте за автором ️👏
- Слідкуйте за нами: X | LinkedIn | YouTube | Discord | Newsletter
- Відвідайте інші наші платформи: CoFeed | Differ
- Більше інформації за посиланням PlainEnglish.io
ОРИГІНАЛ СТАТТІ:From Redshift to Athena: A Data Engineering Team’s Journey to 90% Cost Reduction and Performance Boost
АВТОР СТАТІ:José David Arévalo
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X:


