
Провівши понад 5 років в якості інженера даних, Airflow був моїм основним інструментом для організації робочого процесу. Завдяки своїй надійній екосистемі та широкому впровадженню, він часто виділяється як основне рішення для оркестрування для багатьох.
Я розгорнув його локально, за допомогою Google Cloud Composer та на Kubernetes, і все це за допомогою досвідчених інженерів: підтримувати інфраструктуру було складно, а розробка та підтримка кодової бази Python забирала багато часу.
Вибір правильного інструменту оркестрування передбачає глибоку технічну оцінку:
- Скільки часу потрібно для встановлення та налаштування інструменту? Як при розробці, так і при виробництві.
- Скільки часу потрібно для написання пайплайну? Чи легко він масштабується? Скільки часу потрібно для залучення штатних розробників?
- Скільки часу займає виконання завдань? Чи добре воно виконується? Чи масштабується продуктивність?
- Чи може він підтримувати критичні програми, орієнтовані на клієнта?
Тепер, коли я працюю з Kestra, рішенням з особливим підходом, я хотів би порівняти його з Airflow. Багато data-інженерів та розробників запитують мене, чим Kestra відрізняється від Airflow? Які переваги переходу на Kestra?
У цій статті порівнюються Airflow і Kestra, з акцентом на установці, конфігурації, синтаксисі конвеєра і продуктивності.
Тут я намагаюся бути простим: використовуючи сторінки документації для початківців і не вдаючись до специфічних налаштувань конфігурації. Тести було виконано на Airflow версії 2.7 та Kestra версії 0.14.
Бенчмаркінг за своєю суттю є складним через безліч потенційних варіантів, які необхідно розглянути. Показники, наведені в наступному параграфі, можуть дещо відрізнятися в інших середовищах або при поглибленому налаштуванні.
Встановлення та налаштування
Встановлення та налаштування – це, мабуть, найнудніші частини роботи з програмним забезпеченням. Шукаючи новий інструмент, ми завжди шукаємо щось максимально просте в налаштуванні.
Кожен має інфраструктурні та системні обмеження, і ми часто втрачаємо час на переробку конфігурації. Ми всі шукаємо легку доступність і простоту налаштування.
У цій статті ми розглянемо встановлення та налаштування Kestra та Airflow:
З боку Airflow, швидкий старт складається з декількох кроків:
- Встановлення за допомогою інсталятора пакетів Python (pip)
- Відредагуйте деякі конфігураційні змінні
- Запустіть airflow standalone, який запустить екземпляр з базою даних у пам’яті та відкриє користувацький інтерфейс на порту 8080.
Ця інсталяція постачається з послідовним виконавцем SequentialExecutor, який не може запускати завдання паралельно. Для використання іншого Executor нам потрібно налаштувати спеціальний бекенд бази даних, що додає трохи більше конфігурації.
В іншій частині документації згадується інсталяція docker-compose, яка створює кілька сервісів, таких як база даних Redis, база даних Postgres і Celery як виконавчий механізм, що дозволяє паралелізувати завдання.
Як зазначено у документації до Kestra, проста команда docker-compose up -d дозволяє запустити екземпляр Kestra разом з контейнером Postgres. Виставляємо веб-інтерфейс на порт 8080.
З боку конфігурації, налаштування конфігурації основного сервера Airflow можна редагувати за допомогою файлу airflow.cfg. Майже така ж ідея використовується в Kestra, яка робить доступним файл оточення YAML, що розширюється за допомогою специфікації Micronaut (оскільки вона використовується як внутрішній фреймворк Kestra).
Синтаксис коду
Хороша семантика програмування є, мабуть, найважливішим елементом при розробці програмного забезпечення. На практиці це означає, що її легше підтримувати, простіше вводити в курс справи та легше обговорювати. Різні люди з різним досвідом нарешті можуть говорити однією мовою. Це повертає всіх за стіл переговорів.
Простота написання, читабельність і масштабованість – ось три складові, які ми шукаємо. У поєднанні вони розширюють можливості розробників програмного забезпечення та заощаджують значний час на розробку проектів.
Airflow базується на Python та концепції спрямованого ациклічного графа (DAG). Ось базовий привітний світ DAG:
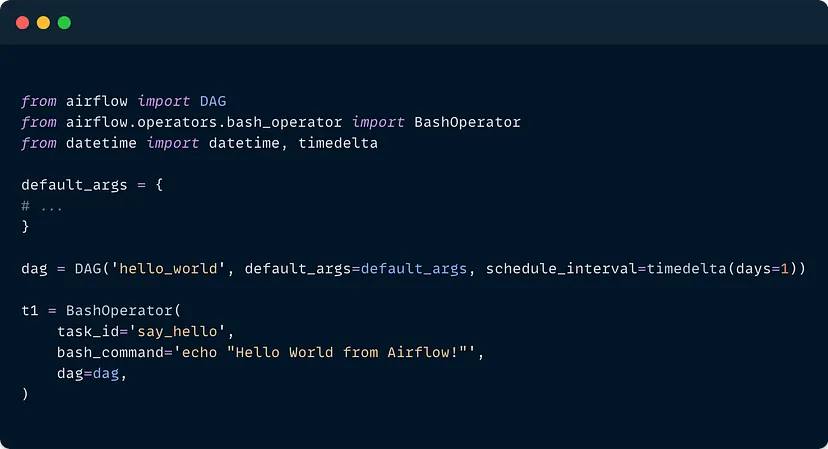
Синтаксис Kestra базується на YAML. Ось базовий потік hello-world:
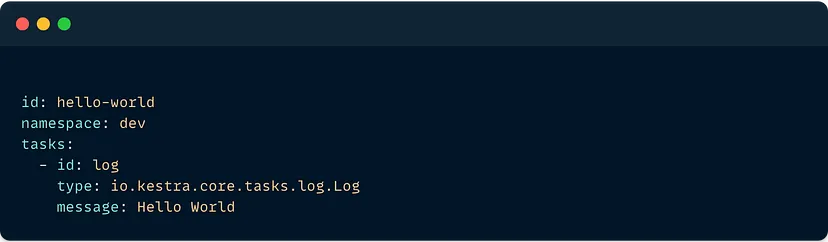
Оскільки Python є імперативною мовою, вона часто менш читабельна і менш зрозуміла, ніж YAML. Але її перевага в тому, що вона дуже легко налаштовується.
З іншого боку, YAML може мати деякі підводні камені. Без належного інструментарію з файлами YAML у сирому форматі може бути складно працювати, включаючи такі проблеми, як:
- Неузгодженість інтерпретації різними парсерами YAML, наприклад, деякі парсери можуть інтерпретувати 0123 як вісімкове число, а інші – як рядок
- Пропуски пробілів спричиняють помилки відступів
- Необхідність пошуку деяких назв властивостей або їх типів
- Невизначеність щодо того, чи є певний об’єкт мапою, чи переліком мап тощо.
Однак варто розглядати ці питання в контексті конкретного інструменту. Kestra вирішила всі поширені проблеми YAML за допомогою механізму на основі API і зробила правильний вибір на користь декларативного визначення логіки оркестрування, побудованого на надійних схемах з належними механізмами перевірки. Ви можете знайти більше інформації у відповідній статті в блозі.
В інших частинах цього блогу я буду використовувати більш складний конвеєр для ефективного оцінювання атрибутів продуктивності двох інструментів, які ми розглядаємо. Це також допоможе краще зрозуміти, наскільки синтаксис може бути складним для сприйняття.
Моя мета – створити початковий конвеєр, призначений для отримання даних з CSV-файлу, та ініціювати кілька запусків подальшого конвеєра. У цьому процесі кожен запуск передбачатиме передачу пакету даних на вхід, а п’ять дочірніх завдань відповідатимуть за роздруківку цих пакетів у журналах.
Використовуючи цей підхід, ми можемо з’ясувати, як працюють оркестрові двіжки, коли вони виконують кілька паралельних завдань одночасно, і зрозуміти їхні загальні можливості.
Ось потоки Кестри для таких вправ:
Це основний потік:
id: for-each-item
namespace: io.kestra.tests
inputs:
- name: file
type: FILE
tasks:
- id: each
type: io.kestra.core.tasks.flows.ForEachItem
items: "{{ inputs.file }}"
batch:
partitions: 1000
namespace: io.kestra.tests
flowId: for-each-item-subflow
wait: true
transmitFailed: true
inputs:
items: "{{ taskrun.items }}"і відповідний дочірній потік викликається головним потоком:
id: for-each-item-subflow
namespace: io.kestra.tests
inputs:
- name: items
type: STRING
tasks:
- id: per-item-1
type: io.kestra.core.tasks.log.Log
message: "{{ inputs.items }}"
- id: per-item-2
type: io.kestra.core.tasks.log.Log
message: "{{ inputs.items }}"
- id: per-item-3
type: io.kestra.core.tasks.log.Log
message: "{{ inputs.items }}"
- id: per-item-4
type: io.kestra.core.tasks.log.Log
message: "{{ inputs.items }}"
- id: per-item-5
type: io.kestra.core.tasks.log.Log
message: "{{ inputs.items }}"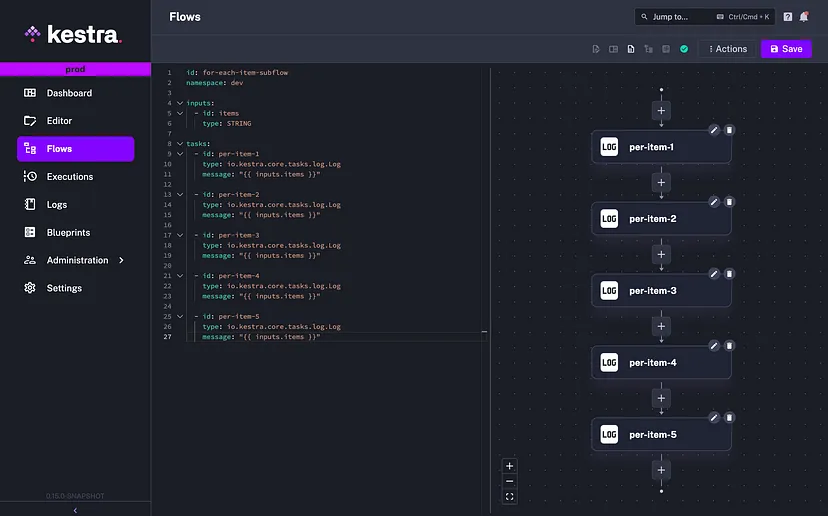
Ось еквівалентні DAG в Airflow:
from datetime import datetime, timedelta
import pandas as pd
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators.dagrun_operator import TriggerDagRunOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 12, 19),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
def process_csv_and_trigger_child_dag(**kwargs):
csv_file = '/opt/airflow/dags/full.csv' # Update with your CSV file path
row_count = 5000
desired_batch_count = 1000
chunk_size = row_count // desired_batch_count
# Read CSV in chunks
for chunk in pd.read_csv(csv_file, chunksize=chunk_size):
# Pass the chunk data as parameters to the child DAG
params = {'csv_data': chunk.to_dict(orient='records')[0]}
# Trigger child DAG for each chunk
trigger = TriggerDagRunOperator(
task_id=f'trigger_child_dag_{chunk.index[0]}',
trigger_dag_id='child_v2_dag',
conf=params,
dag=kwargs['dag'],
)
trigger.execute(context=kwargs)
parent_dag = DAG(
'dynamic_parent_dag_v2',
default_args=default_args,
description='Dynamic DAG to process CSV and trigger child DAG for each batch',
schedule_interval=None, # Set the schedule interval as needed
catchup=False # Set to False if you don't want historical runs to be triggered
)
process_csv_task = PythonOperator(
task_id='process_csv_and_trigger_child_dag',
python_callable=process_csv_and_trigger_child_dag,
provide_context=True,
dag=parent_dag,
)та відповідної підгрупи DAG
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 12, 19),
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
def process_csv_data(**kwargs):
csv_data = kwargs['dag_run'].conf['csv_data'] # Retrieve CSV data from parameters
print(f"{csv_data}")
child_dag = DAG(
'child_v2_dag',
default_args=default_args,
description='Child DAG to process CSV data for each batch',
schedule_interval=None, # Set the schedule interval as needed
catchup=False # Set to False if you don't want historical runs to be triggered
)
for i in range(0, 5):
process_csv_task = PythonOperator(
task_id=f'process_csv_data_{i}',
python_callable=process_csv_data,
provide_context=True,
dag=child_dag,
)Як бачимо, є багато відмінностей у синтаксисі.
У Airflow потрібно знати мову програмування Python і концепції Airflow, щоб зрозуміти, що відбувається. Kestra з її системою ключ-значення на основі YAML не вимагає навичок програмування, щоб бути читабельною.
Перформанси
Як Airflow, так і Kestra мають багато опцій бекенду.
Airflow пропонує два основних налаштування:
- Автономна версія (Швидкий старт): Це простий варіант для початку роботи, але він має обмеження. Він використовує базу даних SQLite в пам’яті і не дозволяє паралельне виконання завдань через вбудований SequentialExecutor. Щоб використовувати паралелізм, вам потрібно вивчити конфігурацію Airflow і вибрати більш підходящий Executor, що може вимагати додаткових кроків встановлення.
- Багатокомпонентна версія: Це забезпечує більшу потужність і масштабованість. Вона використовує окрему базу даних (наприклад, PostgreSQL) і систему черг (наприклад, Redis) для обробки завдань. Крім того, він використовує CeleryExecutor, який забезпечує паралельне виконання завдань у ваших конвеєрах.
Kestra пропонує кілька варіантів розгортання:
- Автономний сервер: Це базовий варіант, який підходить для початку роботи. Для управління робочими процесами потрібна окрема база даних, наприклад, PostgreSQL або MySQL.
- Багатокомпонентна версія: Компоненти Kestra, такі як worker або executor, можна масштабувати горизонтально або вертикально для більш просунутого налаштування – особливо для кращої відмовостійкості та масштабованості.
- Високодоступна версія: Забезпечує підвищену надійність та масштабованість і може використовуватися замість серверної частини PostgresSQL. Вона використовує Kafka, високопродуктивну систему обміну повідомленнями, та Elasticsearch, потужну пошуково-аналітичну систему, для обробки робочих процесів і даних.
Всі тести, встановлення та налаштування були виконані в наступному контексті:
- працює на одній хмарній віртуальній машині з 8 ядрами 32Gb пам’яті та 100Gb місця на жорсткому диску.
- відсутність налаштування конфігурації (налаштування серверів та фреймворку)
- Вхідний файл CSV має розмір близько 800 кб та 5000 рядків.
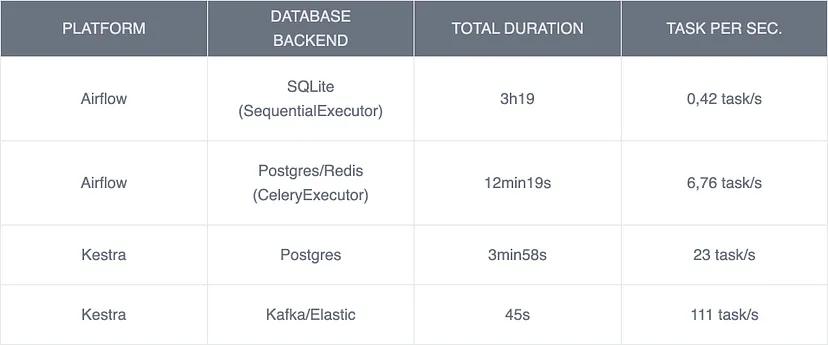
Ключовим моментом використання механізму оркестрування є паралельне виконання, а не лише завдання обробки даних (яке часто від’єднується через інший сервіс).
Kestra, розроблена для високої пропускної здатності, працює краще, ніж Airflow, в мікропакетній обробці. Бекенд Kestra на Java також може сприяти його кращій продуктивності порівняно з основою Airflow на Python.
Висновок: Яка рентабельність інвестицій?
Якщо говорити про рентабельність інвестицій при виборі інструменту для оркестрування, слід врахувати кілька моментів:
- Час встановлення/обслуговування
- Час на написання конвеєра
- Час на виконання (продуктивність)
Виходячи з вищевикладеного, зрозуміло, що Kestra пропонує більш високу рентабельність інвестицій в глобальному масштабі в порівнянні з Airflow:
- Встановити Kestra простіше, ніж Airflow; вона не вимагає залежностей від Python і поставляється з готовим до використання файлом докер-компілятора з використанням невеликої кількості сервісів і без необхідності розуміти, що таке executor для паралельного запуску завдань.
- Створювати конвеєри за допомогою Kestra дуже просто завдяки її синтаксису. Вам не потрібні знання конкретної мови програмування, оскільки Kestra розроблена як агностична система. Декларативний дизайн YAML робить потоки Kestra більш читабельними порівняно з DAG-еквівалентом Airflow, що дозволяє розробникам значно скоротити час розробки.
- У цьому тесті Kestra демонструє кращий час виконання, ніж Airflow при будь-яких налаштуваннях конфігурації.
Якщо ви шукаєте чудові інформаційні ресурси та ідеї, підпишіться на мою розсилку – 👀 From An Engineer Sight.
ОРИГІНАЛ СТАТТІ:Airflow & Kestra: a Simple Benchmark
АВТОР СТАТІ:Benoit Pimpaud
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook: