[ЧАСТИНА 1] → [Початковий — Середній рівень]
##Питання 1.
Різниця між Truncate, Drop, Delete.
Команда DROP може використовуватися для видалення будь-яких об’єктів бази даних, таких як таблиці, views, функції, процедури, тригери і т. д.
Delete є оператором DML, тому нам потрібно закомітити транзакцію, щоб зберегти зміни в базі даних. Тоді як truncate і drop – це оператори DDL, тому коміт не потрібен.
Наприклад: Нижче наведений оператор видалить лише записи з таблиці співробітників, де ім’я – «Таня»
DELETE FROM employee WHERE name = 'Tanya';
COMMIT;
Нижче наведений оператор видалить всі записи з таблиці співробітників.DELETE FROM employee;
COMMIT;
Нижче наведений оператор також видалить всі записи з таблиці співробітників. Тут коміт не потрібен.
TRUNCATE TABLE employee;
##Питання 2.
Різниця між віконними функціями RANK, DENSE_RANK і ROW_NUMBER.
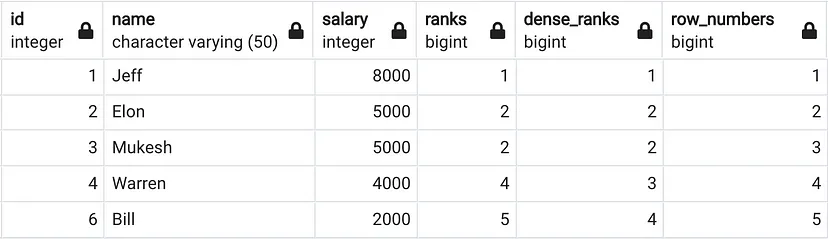
Функція RANK() присвоює ранг кожному рядку у кожному розділеному наборі результатів. Якщо кілька рядків мають однакове значення, то кожен з цих рядків отримає однаковий ранг. Однак ранг наступних рядків буде пропущено. Це означає, що для кожного дубльованого рядка одне значення рангу буде пропущено.
Функція DENSE_RANK() присвоює ранг кожному рядку у кожному розділеному наборі результатів. Якщо кілька рядків мають однакове значення, то кожен з цих рядків отримає однаковий ранг. Однак у dense_rank наступних рядків НЕ буде пропущено. Це єдине відмінностя між rank та dense_rank. Функція RANK() пропускає ранг, якщо є дубльовані рядки, тоді як функція DENSE_RANK() ніколи не пропускає ранг.
Функція ROW_NUMBER() присвоює унікальний номер рядку кожному рядку у кожному розділеному наборі результатів. Не має значення, чи є рядки дубльованими чи ні.
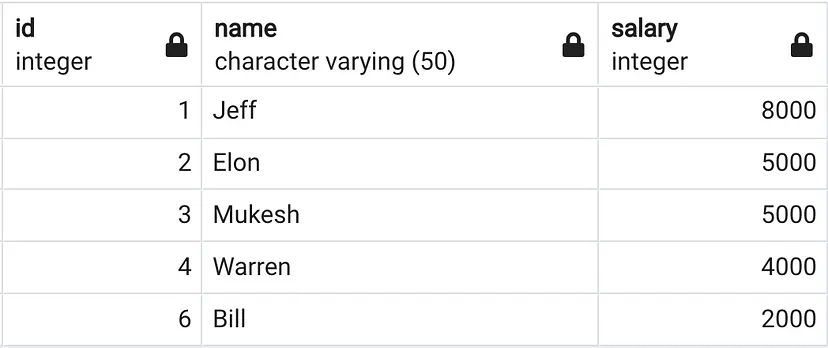
Використовуючи таблицю менеджерів, давайте напишемо запит, щоб отримати ранг, щільний ранг і номер рядка для кожного менеджера на основі їх зарплати.
SELECT *
, RANK() OVER(ORDER BY salary DESC) AS ranks
, DENSE_RANK() OVER(ORDER BY salary DESC) AS dense_ranks
, ROW_NUMBER() OVER(ORDER BY salary DESC) AS row_numbers
FROM managers;
Назва таблиці: MANAGERS
Містить деталі про зарплату 5 різних менеджерів.
##Питання 3.
Різниця між Унікальними, первинними та зовнішніми ключами.
Первинний ключ, унікальний ключ та зовнішній ключ — це обмеження, які ми можемо створювати для таблиці.
Коли ви встановлюєте стовпець у таблиці як первинний ключ, цей стовпець завжди буде містити унікальні значення. Дублікати та значення NULL не допускаються у стовпці з первинним ключем. У таблиці може бути тільки один первинний ключ. Первинний ключ може бути створений або на одному стовпці, або на групі стовпців.
Коли ви встановлюєте стовпець у таблиці як унікальний ключ, цей стовпець завжди буде містити унікальні значення. Дублікати значень не допускаються. Однак значення NULL дозволено в стовпці, який має обмеження унікального ключа. Це основна різниця між первинним та унікальним ключем.
Зовнішній ключ використовується для створення головного дочірнього зв’язку між двома таблицями. Коли ми робимо стовпець у таблиці зовнішнім ключем, на цей стовпець потрібно буде посилатися з іншого стовпця в іншій таблиці.
##Питання 4.
Різниця між клаузами”WHERE” і “HAVING”.
“WHERE” використовується для фільтрації записів з таблиці. Ми також можемо вказати умови об’єднання між двома таблицями у кляузі “WHERE”. Якщо SQL-запит має як клаузули “WHERE”, так і “GROUP BY”, то записи спочатку фільтруються на основі умов, вказаних у “WHERE”, перед тим як дані групуються відповідно до “GROUP BY”. Умови, вказані у “WHERE”, застосовуються до окремих рядків у таблиці.
У той час як “HAVING” використовується для фільтрації записів, які повертаються після “GROUP BY”. Таким чином, якщо SQL-запит має клаузули “WHERE”, “GROUP BY” і “HAVING”, то спочатку дані фільтруються на основі умов “WHERE”, і лише після цього відбувається групування даних. Нарешті, на основі умов у “HAVING” знову фільтруються груповані дані.
Умови, вказані у “HAVING”, застосовуються до агрегованих значень, а не до окремих рядків.
##Питання 5.
Різниця між PARTITION BY і GROUP BY.
- Клауза GROUP BY використовується разом з агрегатними функціями для групування рядків за одним або декількома стовпцями.
- Зазвичай вона використовується в запитах, де ви хочете виконати агрегатні обчислення (такі як SUM, COUNT, AVG і т. д.) для груп рядків, які мають спільні значення у вказаних стовпцях.
- Клауза GROUP BY застосовується перед клаузою SELECT у виконанні запиту.
-- Using GROUP BY
SELECT department, AVG(salary) AS avg_department_salary
FROM employees
GROUP BY department;Вихідні дані:
| department | avg_department_salary |
|------------|-----------------------|
| HR | 52500.00 |
| IT | 65000.00 |- Клауза PARTITION BY використовується з віконними функціями, які є набором функцій, що виконують обчислення по певному діапазону рядків, пов’язаних з поточним рядком у вихідному наборі.
- PARTITION BY розділяє вихідний набір на розділи, до яких окремо застосовується віконна функція. Він не групує рядки так само, як GROUP BY.
- Клауза PARTITION BY застосовується після виконання віконної функції в запиті.
-- Using PARTITION BY
SELECT employee_id, department, salary,
AVG(salary) OVER (PARTITION BY department) AS avg_department_salary
FROM employees;Вихідні дані:
| employee_id | department | salary | avg_department_salary |
|-------------|------------|----------|-----------------------|
| 1 | HR | 50000.00 | 52500.00 |
| 2 | HR | 55000.00 | 52500.00 |
| 3 | IT | 60000.00 | 65000.00 |
| 4 | IT | 65000.00 | 65000.00 |
| 5 | IT | 70000.00 | 65000.00 |##Питання 6.
Уявіть, що в таблиці є стовпчик FULL_NAME, який містить значення, такі як “Елон Маск”, “Білл Гейтс”, “Джефф Безос” і т.д. Таким чином, кожне повне ім’я має ім’я, пробіл і прізвище. Які функції ви використовуватимете, щоб витягнути лише ім’я з цього стовпчика FULL_NAME? Наведіть приклад.
SELECT
SUBSTR(full_name, 1, POSITION(' ' IN full_name) - 1) as first_name
FROM
your_table_name;- SUBSTR(full_name, 1, POSITION(' ' IN full_name) - 1): Ця частина запиту використовує функцію SUBSTR для витягування підрядка зі стовпця full_name. Аргументи такі:
- full_name: Вихідний рядок, з якого витягується підрядок.
- 1: Початкова позиція підрядка (у цьому випадку, від початку full_name).
- POSITION(' ' IN full_name) - 1: Довжина підрядка. Вона обчислює позицію пробілу (‘ ‘) у стовпці full_name за допомогою функції POSITION і віднімає 1, щоб виключити сам пробіл.
- as first_name: Ця частина запиту присвоює витягнутому підрядку псевдонім “first_name” для результату.
##Питання 7.
Як можна конвертувати текст у формат дати? Розглянемо заданий текст як “31–01–2021“.
У SQL часто використовується функція TO_DATE для перетворення текстового представлення дати у фактичний формат дати. Синтаксис функції TO_DATE варіюється у різних системах баз даних, але ви надали приклад, який, здається, призначений для системи, яка використовує формат ‘DD-MM-YYYY’.
Ось пояснення SQL-запиту, який ви надали:
SELECT TO_DATE('31-01-2023', 'DD-MM-YYYY') as date_value;- TO_DATE('31-01-2021', 'DD-MM-YYYY'): Ця частина запиту використовує функцію TO_DATE для перетворення тексту ’31-01-2021′ у формат дати. Перший аргумент (’31-01-2021′) – це текстове представлення дати, а другий аргумент (‘DD-MM-YYYY’) – це формат дати у вхідному тексті.
- as date_value: Ця частина запиту надає псевдонім ‘date_value’ результату, який є перетвореною датою.
##Питання 8.
Чому ми використовуємо оператор CASE в SQL? Наведіть приклад.
Оператор CASE схожий на оператор IF ELSE з інших мов програмування. Ми можемо використовувати його, щоб отримати або показати певне значення на основі певної умови.
Оператор CASE в SQL використовується для виконання умовної логіки в межах запиту.
Ось простий приклад використання оператора CASE в запиті SELECT:
SELECT
employee_name,
salary,
CASE
WHEN salary > 50000 THEN 'High Salary'
WHEN salary > 30000 THEN 'Medium Salary'
ELSE 'Low Salary'
END AS salary_category
FROM
employees;У цьому прикладі оператор CASE використовується для класифікації працівників в залежності від їхнього заробітку. Якщо зарплата перевищує 50 000, то категорія – ‘Висока зарплата.’ Якщо зарплата знаходиться у діапазоні від 30 000 до 50 000, то категорія – ‘Середня зарплата.’ В іншому випадку категорія – ‘Низька зарплата.’
##Питання 9.
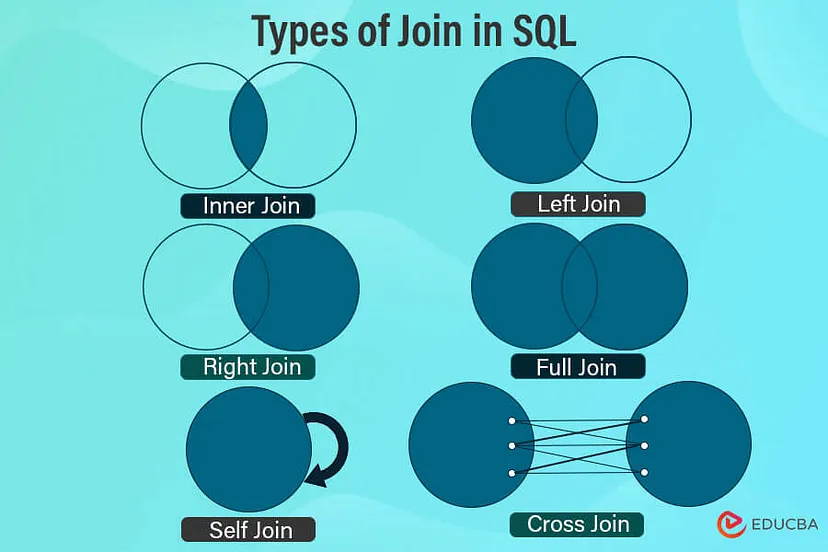
Ліва зовнішня, права зовнішня, повна зовнішня з’єднання та внутрішнє з’єднання: яка їх відмінність?
Для кращого розуміння цього, давайте розглянемо дві таблиці CONTINENTS (КОНТИНЕНТИ) і COUNTRIES (КРАЇНИ), як показано нижче. Я покажу приклади запитів, враховуючи ці дві таблиці.

Назва таблиці: КОНТИНЕНТИ
Містить дані про 6 континентів. Зверніть увагу, що континент “Антарктида” у цій таблиці навмисно відсутній.

Назва таблиці: КРАЇНИ
Містить дані про одну країну з кожного континенту. Зверніть увагу, що я навмисно не додав країну з Європи до цієї таблиці.
INNER JOIN вибере лише ті записи, які присутні в обох об’єднаних таблицях. Відповідність записів базується лише на стовпцях, використаних для об’єднання цих двох таблиць. INNER JOIN також може бути представлений як JOIN у вашому запиті SELECT.

Запит з INNER JOINSELECT cr.country_name, ct.continent_name
FROM continents ct
INNER JOIN countries cr
ON ct.continent_code = cr.continent_code;
LEFT JOIN вибере всі записи з лівої таблиці (таблиця, розташована зліва під час об’єднання), навіть якщо ці записи відсутні в правій таблиці (таблиця, розташована справа під час об’єднання). Якщо ваш SELECT має стовпець з правої таблиці, то для записів, які відсутні в правій таблиці (але присутні в лівій таблиці), SQL поверне значення NULL. LEFT JOIN також може бути представлений як LEFT OUTER JOIN у вашому запиті SELECT.

RIGHT JOIN запитSELECT cr.country_name, ct.continent_name
FROM continents ct
RIGHT JOIN countries cr
ON ct.continent_code = cr.continent_code;
RIGHT JOIN вибере всі записи з правої таблиці (таблиця, розташована справа під час об’єднання), навіть якщо ці записи відсутні в лівій таблиці (таблиця, розташована зліва під час об’єднання). Якщо ваш SELECT має стовпець з лівої таблиці, то для записів, які відсутні в лівій таблиці (але присутні в правій таблиці), SQL поверне значення NULL. RIGHT JOIN також може бути представлений як RIGHT OUTER JOIN у вашому запиті SELECT.
*Примітка: LEFT та RIGHT JOIN залежить від того, чи розташована таблиця зліва від JOIN чи справа від JOIN.

FULL JOIN запитSELECT cr.country_name, ct.continent_name
FROM continents ct
FULL JOIN countries cr
ON ct.continent_code = cr.continent_code;
FULL JOIN вибере всі записи з обох лівої та правої таблиці. Це свого роду комбінація INNER, LEFT та RIGHT join. Означає, що FULL JOIN вибере всі відповідні записи у лівій та правій таблицях + всі записи з лівої таблиці (навіть якщо ці записи відсутні в правій таблиці) + всі записи з правої таблиці (навіть якщо ці записи відсутні в лівій таблиці). FULL JOIN також може бути представлений як FULL OUTER JOIN у вашому запиті SELECT.
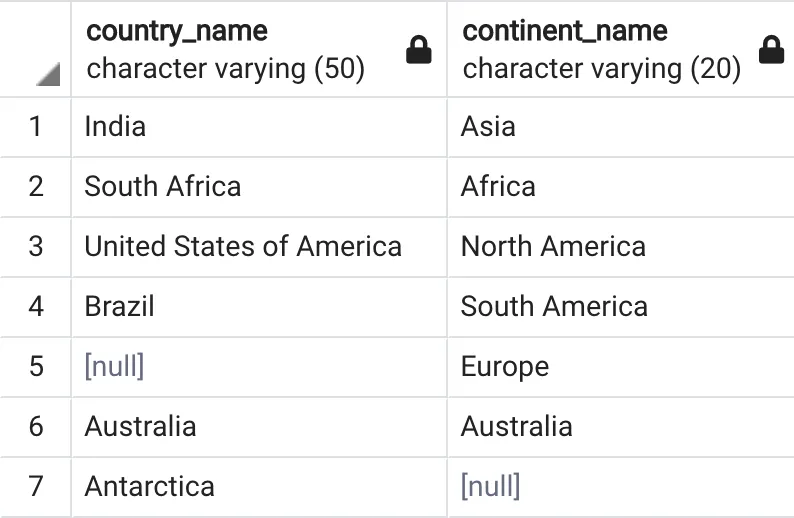
FULL OUTER JOIN запитSELECT cr.country_name, ct.continent_name
FROM continents ct
FULL OUTER JOIN countries cr
ON ct.continent_code = cr.continent_code;
Також перевірте, що таке SELF join, NATURAL join та CROSS join?
SELF JOIN – це коли ви приєднуєте таблицю до самої себе. Для цього типу з’єднання немає ключового слова, такого як SELF. Ми просто використовуємо звичайний INNER join для виконання SELF join. Просто замість виконання inner join з двома різними таблицями, ми виконуємо inner join тієї ж самої таблиці з собою. При цьому таблиці повинні мати різні псевдоніми. Окрім цього, SELF join працює аналогічно INNER join.
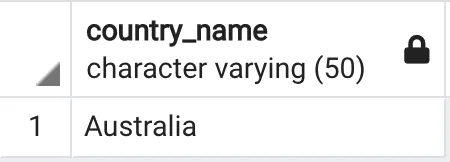
SELF JOIN QuerySELECT cr1.country_name
FROM countries cr1
JOIN countries cr2ON cr1.country_code = cr2.continent_code;
З’єднання NATURAL JOIN схоже на INNER JOIN, але під час з’єднання нам не потрібно використовувати ON. Це означає, що при використанні NATURAL JOIN ми просто вказуємо таблиці. Ми не вказуємо стовпці, за якими має працювати це з’єднання. За замовчуванням, коли ми використовуємо NATURAL JOIN, SQL з’єднує дві таблиці на основі спільного імені стовпця в цих двох таблицях. Таким чином, під час виконання natural join обидві таблиці повинні мати стовпці з однаковою назвою, і ці стовпці повинні мати однаковий тип даних.

Запит NATURAL JOINSELECT cr.country_name, ct.continent_name
FROM continents ct
NATURAL JOIN countries cr;
З’єднання CROSS JOIN з’єднує всі записи з лівої таблиці з усіма записами з правої таблиці. Це означає, що з’єднання CROSS JOIN не базується на відповідності будь-якого стовпця. Незалежно від того, чи є відповідність, з’єднання CROSS JOIN поверне записи, що в основному є кількістю записів у лівій таблиці, помноженими на кількість записів у правій таблиці. Іншими словами, CROSS JOIN повертає декартовий добуток.
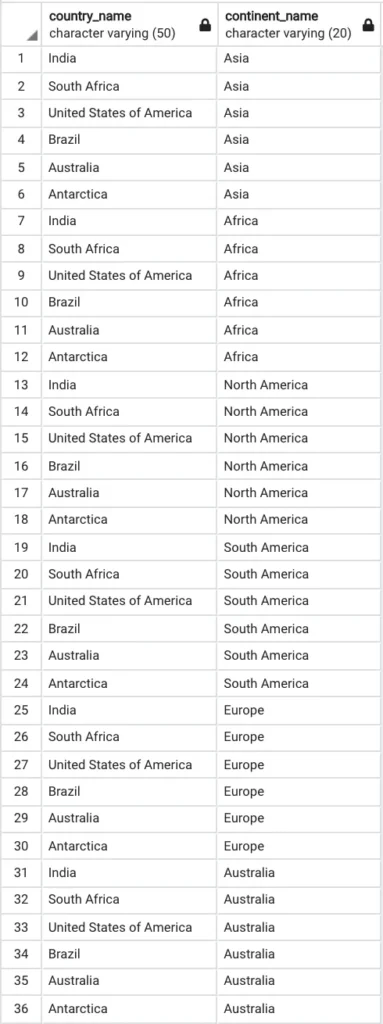
Запит CROSS JOINSELECT cr.country_name, ct.continent_name
FROM continents ct
CROSS JOIN countries cr;
##Питання 10.
Чи можемо ми використовувати агрегатну функцію як віконну функцію? Якщо так, то як це зробити?
Так, ми можемо використовувати агрегатну функцію як віконну функцію, використовуючи клаузу OVER. Агрегатна функція зменшить кількість рядків або записів, оскільки вона виконує обчислення набору значень рядків, щоб повернути одне значення. У той час, як віконна функція не зменшує кількість записів.
Тепер давайте використаємо функцію SUM як віконну функцію для обчислення накопиченої суми заробітної плати в межах кожного відділу на основі порядку зарплати:
SELECT
employee_id,
employee_name,
department,
salary,
SUM(salary) OVER (PARTITION BY department ORDER BY salary) AS running_total_salary
FROM
employees;Вивід:
| employee_id | employee_name | department | salary | running_total_salary |
|-------------|---------------|------------|----------|-----------------------|
| 1 | John | HR | 50000.00 | 50000.00 |
| 3 | Bob | HR | 55000.00 | 105000.00 |
| 2 | Jane | IT | 60000.00 | 60000.00 |
| 4 | Alice | IT | 70000.00 | 130000.00 У цьому прикладі стовпець running_total_salary представляє суму накопиченої зарплати в межах кожного відділу, розраховану на підставі зростання зарплати. Клауза PARTITION BY використовується для розділення результуючого набору за відділом. Клауза ORDER BY визначає порядок рядків в межах кожної партіції на підставі стовпця зарплати. Функція SUM застосовується як віконна функція, і вона розраховує суму накопиченої зарплати для кожного рядка всередині його відділу.
ОРИГІНАЛ СТАТТІ:Most asked SQL Interview Questions
АВТОР СТАТІ:Tanya Agarwal
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


