

Минулого тижня Арно Стефан, колега-інженер з аналітики, попросив допомогти йому з одним складним випадком, який мені видався дуже цікавим. Після того, як я провів кілька годин, допомагаючи йому, я подумав, що це може стати ідеальною темою для статті в блозі, і попросив його дозволу обговорити цю складну реальну проблему публічно і опублікувати пов’язаний з нею код.
Отже, давайте осідлаємо коня і приготуємося до просунутого практичного SQL за допомогою мого улюбленого движка: Google BigQuery!
(Примітка: для збереження анонімності я замінив ідентифікатори та значення на фіктивні).
Про автора:
Я позаштатний інженер-аналітик / інженер платформи даних з більш ніж 12-річним досвідом роботи з SQL та великими даними. Я люблю грати зі складними темами SQL/DataFrame, тому якщо ви застрягли на складних проблемах, які ви не можете вирішити за допомогою SQL, не соромтеся звертатися до мене; можливо, я зможу допомогти.
Проблема
Спершу давайте розглянемо контекст: У нас є дані від продуктового ритейлера, який продає кілька найменувань товарів у кількох магазинах. Для кожного товару в кожному магазині вони відстежують історію цін на ці товари. Відповідні дані містяться в таблиці sell_price_history, яка має такий вигляд:
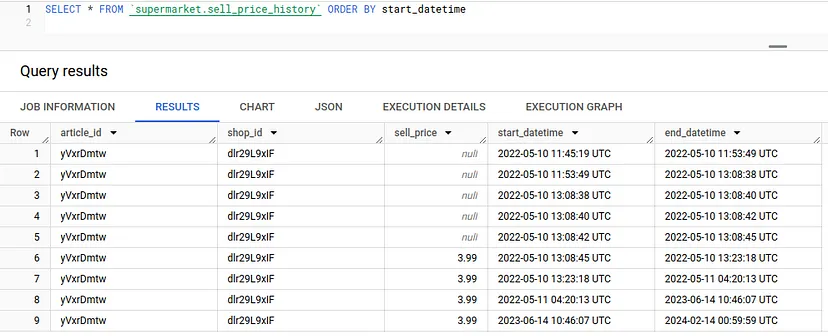
Але кожен магазин також може створювати акції для будь-якого товару, і в цьому випадку значення promotion_value замінить початкову ціну товару. Друга таблиця з назвою promotion_history містить відповідні дані:
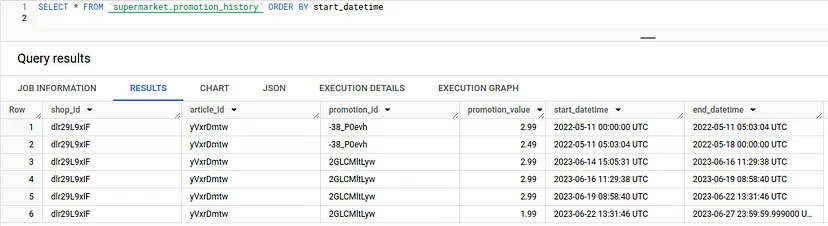
Звідси випливає проблема: Ми хочемо “об’єднати” ці дві таблиці подій в одну єдину таблицю, яка дасть нам для кожного артикулу історію цін, включаючи вплив промо-акцій.
Іншими словами, очікуваний результат, якого ми хочемо, повинен виглядати так:
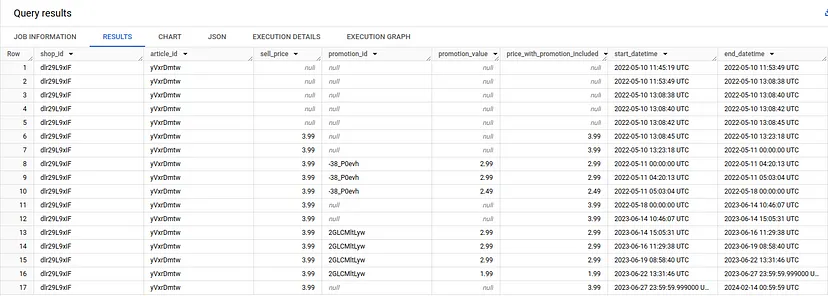
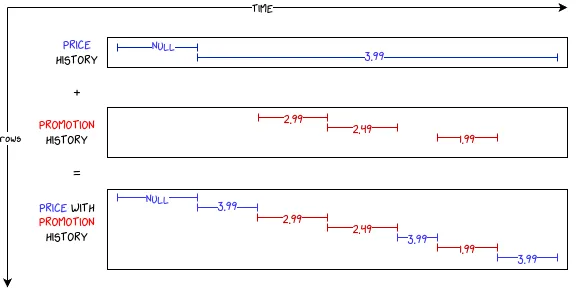
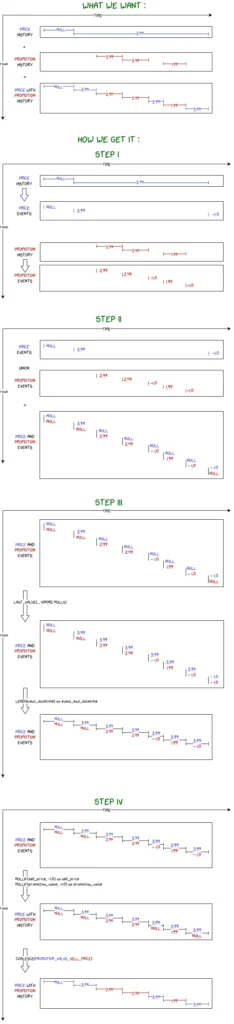
Щоб надати більш наочну ілюстрацію, ми хочемо об’єднати дві таблиці, що описують діапазони подій.
(Неправильне) рішення
Щоб зробити процес трохи жвавішим, я розповім вам, як я вирішив цю проблему. Я приблизно уявляв, що для цього мені потрібно розкласти кожну таблицю на своєрідну “часову шкалу подій”, а потім об’єднати ці дві часові шкали і заповнити прогалини. Наразі це може звучати дещо розмито, але так було, коли я почав вирішувати проблему. Не хвилюйтеся, скоро все стане зрозуміліше.
Крок 1: Спільне розміщення даних
Перше, що я зробив ще до того, як почав думати, як вирішити проблему, – об’єднав обидві таблиці разом і згрупував дані за shop_id та article_id, ось так:
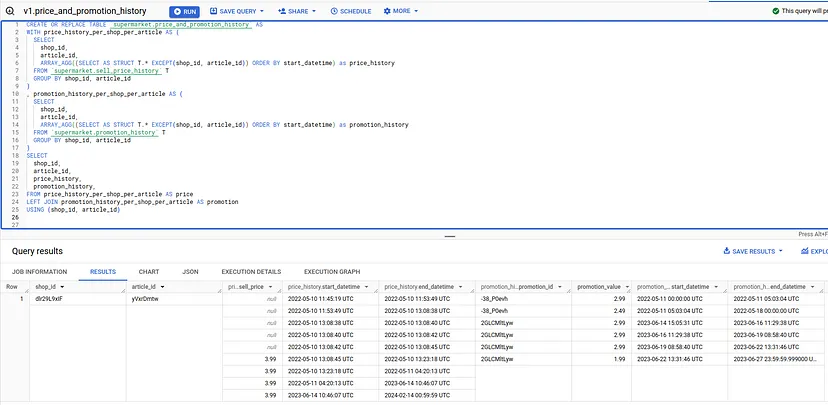
Для тих, хто не знайомий з вкладеними структурами у BigQuery, це може виглядати трохи дивно, тому ось детальне пояснення того, як організовані структури даних:
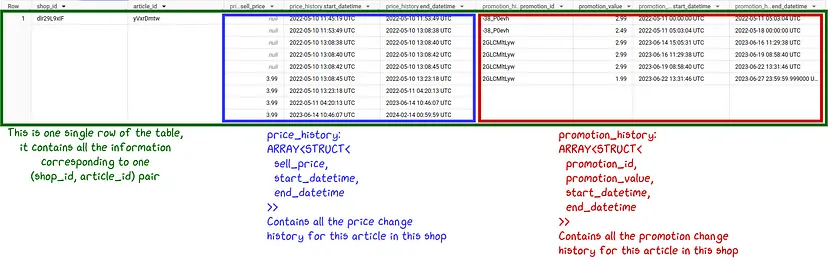
Існує багато причин, чому я віддаю перевагу саме такому способу організації речей:
- Простота: Спільне розташування даних для кожної статті дозволяє мені міркувати на однорядковій основі.
- Продуктивність: Завдяки цьому попередньому групуванню всі обчислення, які я буду виконувати, будуть виконуватися на рівні рядків. Для тих, хто знайомий з MapReduce, будуть тільки кроки Map, ніякого Reduce, і, найголовніше, ніякого Shuffle, який, як правило, є найбільш ресурсоємною частиною.
Це не є “критичним” для BigQuery, оскільки ціна запиту базується лише на кількості прочитаних даних, а не оброблених, але це буде на інших движках, а я люблю оптимізувати свій код. - Ефективність зберігання: Оскільки shop_id та article_id не повторюються в кожному рядку, таке представлення займає менше місця для зберігання тієї ж кількості інформації. Це не має особливого сенсу на такому іграшковому наборі даних, як цей, але для розуміння, загальний розмір двох вхідних таблиць становив 720b, а розмір вихідної таблиці (яка містить ту ж саму інформацію) – лише 412b. Помножте це на мільярди рядків, і ви можете помітити різницю в ціні.
Основні недоліки полягають у тому, що більшість людей не звикли до нього, тому їм може знадобитися певна кількість зусиль, щоб навчитися правильно робити запити, і багато інструментів метаданих (каталоги даних, data diff і т.д.) поки що не дуже добре підтримують вкладені структури.
Але досить відволікатися. Ця тема заслуговує на цілу статтю, тому давайте повернемося до нашого завдання.
Крок 2: Об’єднання двох історій
Далі ми виконуємо об’єднання двох таблиць історії ось так:
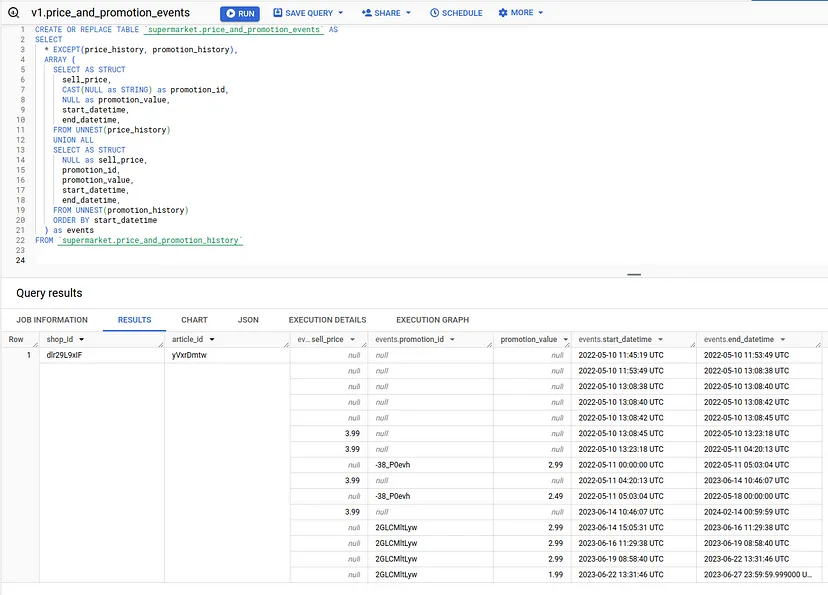
Крок 3: Заповнення пропусків
Нарешті, ми використовуємо віконну функцію last_value для зберігання останнього ненульового значення в ордерах подій, для заповнення пропусків, або, краще сказати, NULLs.
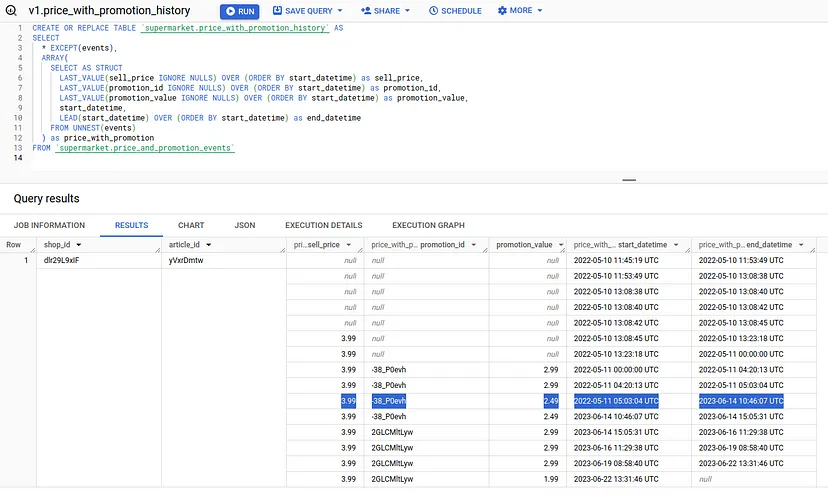
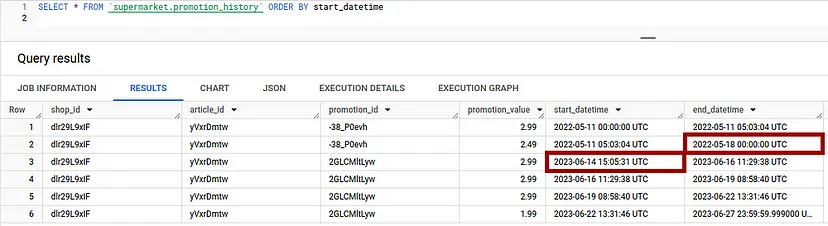
Хоча цей результат і виглядає як результат, якого ми шукаємо, уважні читачі, можливо, вже помітили, що насправді він неправильний.
Чому це не працює:
Це працювало б, якби рекламні акції тривали без перерви, але якщо ми уважніше подивимося на наші вхідні дані, то побачимо, що це не так: Ми маємо перерву між першою та другою рекламними акціями. Цю перерву не видно на попередньому скріншоті, як ми бачимо на лінії, виділеній синім кольором.
(Правильне) рішення
Зараз ми подивимося, як можна виправити попереднє (неправильне) рішення, з більш детальними поясненнями того, що відбувається.
Крок 1: Спільне розміщення даних [Нічого не змінюється]
Крок 1 був лише підготовчим кроком. Ми можемо залишити все як є.
Крок 2: Перетворення діапазонів дат на часові шкали та їх об’єднання
Наша інтуїція щодо об’єднання двох часових шкал була хорошою, але ми не врахували той факт, що діапазони дат можуть бути переривчастими. Щоб виправити це, перший крок, який ми повинні зробити, це перетворити нашу “історію”, яка складається з діапазонів дат (від start_date до end_date), на часову шкалу подій, яка складається лише з подій (лише одна event_date), не втрачаючи жодної інформації.
Схематично це буде виглядати так:
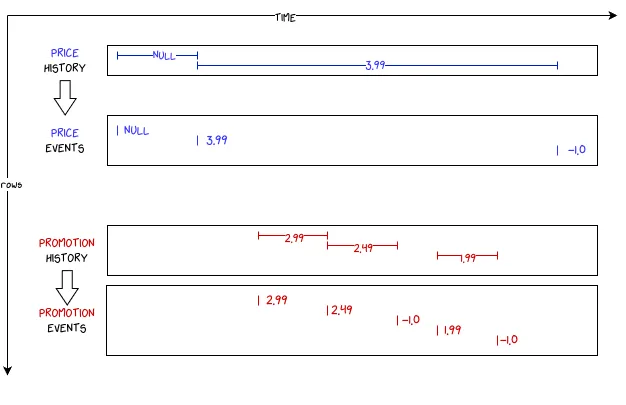
Тут “відсутні” значення були представлені магічним числом -1. Це тому, що на кроці 3 ми не хочемо поводитися з ними так само, як з NULL, коли використовуємо віконну функцію last_value(… ignore nulls). Можливо, це запах коду, але ми залишимо його для спрощення в цій статті.
Після цього ми просто об’єднаємо дві часові шкали за допомогою UNION ось таким чином:
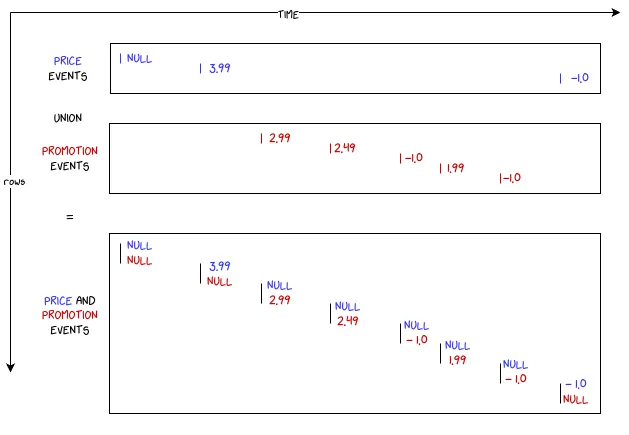
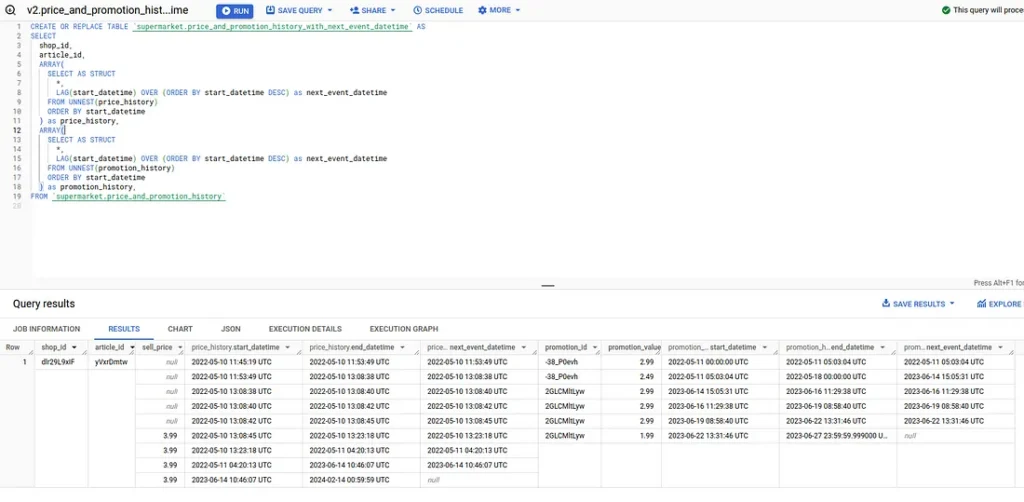
Отже, як виглядає код? Зосередимось поки що лише на акціях. Перший крок – отримати “start_datetime” наступної події; це допоможе нам виявити, коли відбувається переривання:
SELECT
...
ARRAY(
SELECT AS STRUCT
*,
LAG(start_datetime) OVER (ORDER BY start_datetime DESC) as next_event_datetime
FROM UNNEST(promotion_history)
ORDER BY start_datetime
) as promotion_history,
...Другий крок полягає у введенні нових подій щоразу, коли трапляється така перерва, наприклад, як зараз:
SELECT
...
ARRAY (
SELECT AS STRUCT
promotion_value,
start_datetime,
FROM UNNEST(promotion_history)
UNION ALL
SELECT AS STRUCT
-1 as promotion_value,
end_datetime,
FROM UNNEST(promotion_history)
WHERE end_datetime < next_event_datetime OR next_event_datetime IS NULL
) as events
...Друга частина союзу – це те, що повертає раніше відсутні “кінцеві події”:
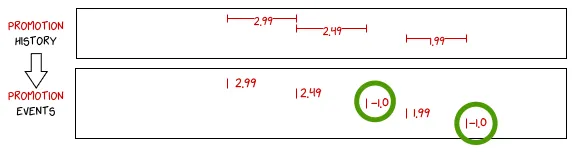
Об’єднавши все разом, ми отримуємо запит, що складається з двох частин:
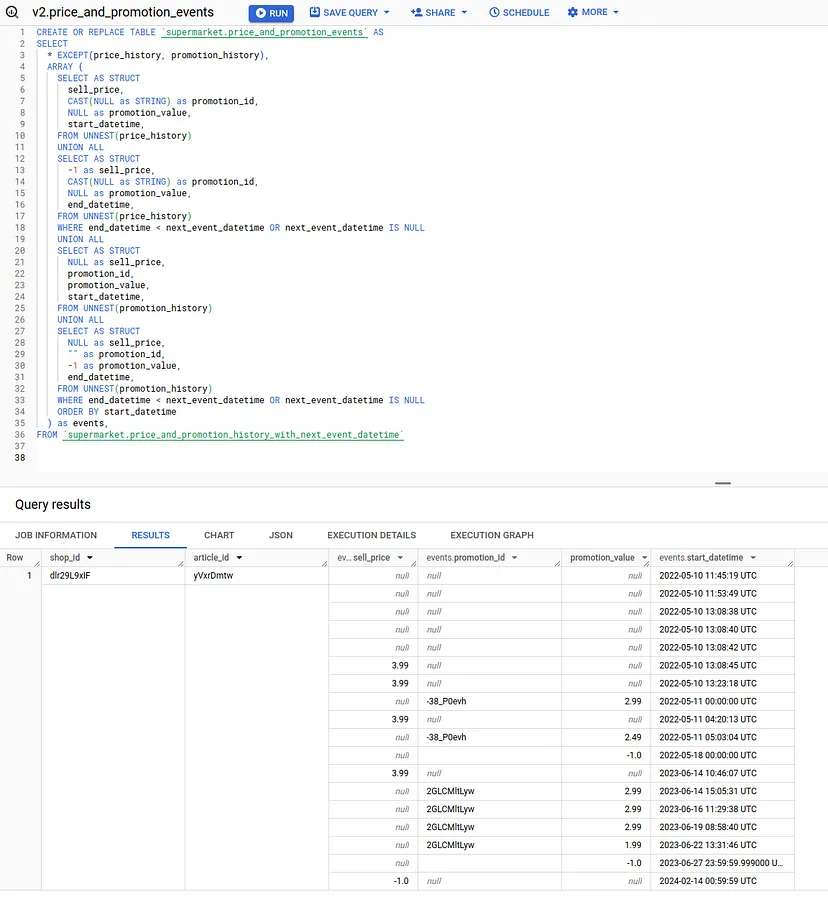
Крок 3: Заповнення прогалин + заміна магічних значень
Тепер, коли це зроблено, попередній запит з кроку 3 дає нам результат, який виглядає майже так, як ми хочемо:
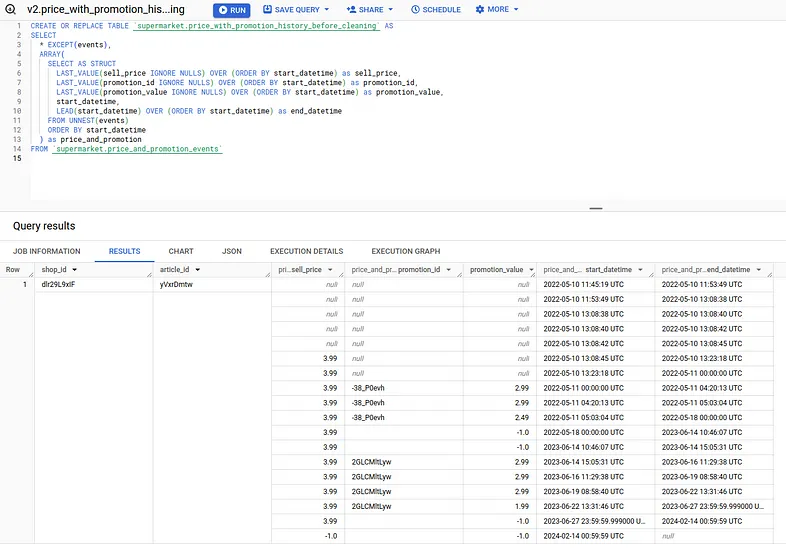
Віконна функція last_value(… ignore nulls) дозволяє нам заповнити пропуски, а віконна функція lead дозволяє нам отримати кінцеві дати, щоб переформувати наші діапазони дат.
Все, що нам потрібно зробити далі, це виконати деяке очищення, щоб видалити магічні значення -1 і “”:
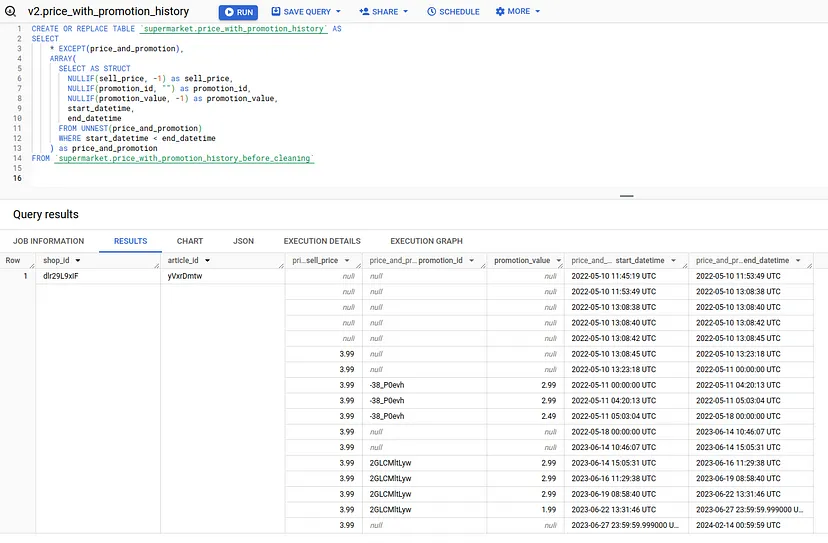
Ми виконуємо один останній запит для обчислення price_with_promotion_included і одне останнє розкриття гнізда, оскільки ми хочемо, щоб остаточні результати були рівними (shop_id і article_id повторюються в кожному рядку).
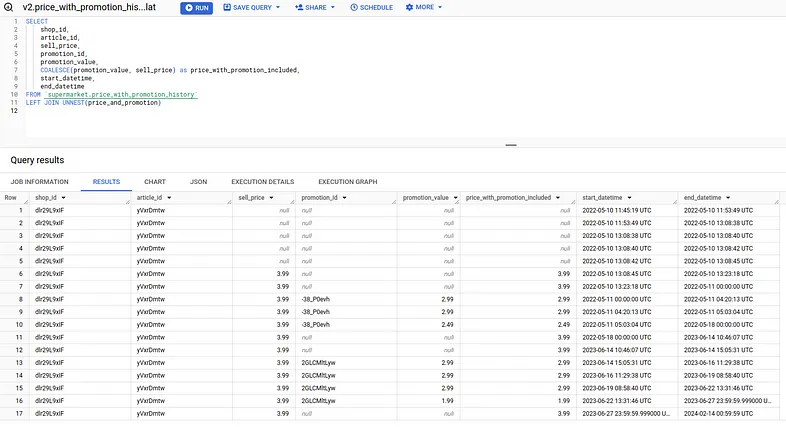
І це все, ми закінчили!
Висновок
Нам вдалося обчислити те, що ми хотіли, за чотири чи п’ять кроків. Я думаю, що ця задача є гарним прикладом того, що виглядає просто на перший погляд, але є досить складним для виконання за допомогою SQL. Це той тип складних перетворень, де я рекомендую розглянути компроміс між написанням логіки на чистому SQL та написанням користувацької функції (UDF) іншою мовою (Python, Scala, Javascript чи іншою), якщо це можливо. Перевага UDF полягає в тому, що вона робить код більш загальним і безпечним (завдяки юніт-тестам). Однак, він має недолік у тому, що загалом менш ефективний і більш дорогий у порівнянні з чистим SQL.
В якості вправи, якщо ви хочете трохи попрактикуватися, я рекомендую спробувати переписати цю вправу самостійно, використовуючи один з наступних варіантів:
- Перепишіть це без використання магічних значень.
(Підказка: додайте стовпець event_status, який може приймати значення “ON” або “OFF”). - Перепишіть це без використання ARRAYS або STRUCT.
(Підказка: це цілком можливо, але для вікон може знадобитися додатковий “PARTITION BY shop_id, article_id”). - Перепишіть його за допомогою вашого улюбленого dbt-подібного інструменту.(Я добровільно не використовував тут dbt, щоб зробити цю публікацію доступною для більшості).
- Намагайтеся писати його повністю узагальненим способом: Запит повинен працювати з будь-якою кількістю стовпців у вхідних таблицях і продовжувати працювати, навіть якщо ми додамо новий стовпець у вхідну таблицю без оновлення запиту.(Підказка: я не впевнений, що це можливо в чистому SQL, тому що коли я спробував, то помітив, що BigQuery, здається, не може автоматично приводити NULL до складних типів при виконанні об’єднання. Це може бути гарним викликом для bigquery-dataframes або bigquery-frames, хоча, можливо, це можна зробити з bigquery-dataframes).
- За допомогою DataFrames, можливо, навіть можна зробити повністю універсальне перетворення, яке буде автоматично працювати з будь-якою кількістю таблиць історії.
Нарешті, якщо ви хочете дізнатися більше про роботу з масивами, ви можете почати з цієї чудової сторінки з документації BigQuery, а якщо ви хочете побачити більше статей на цю тему від мене, будь ласка, залиште коментар, щоб дати мені знати.
На сьогодні це все. Дякую, що прочитали! Сподіваюся, вам сподобалося читати цю статтю так само, як і мені.
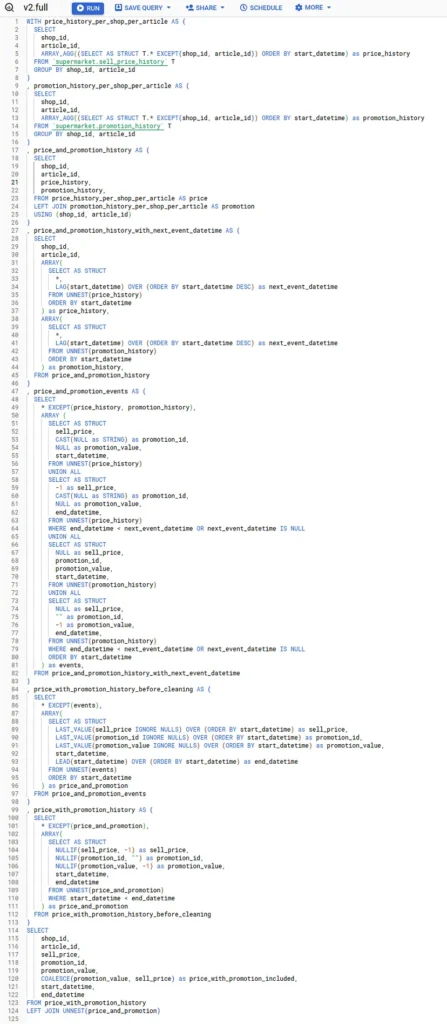
Я залишаю вам повний запит, використаний у цій статті (переписаний за допомогою CTE) і повний графік пояснень. Код і приклади даних доступні тут. Насолоджуйтесь 😉
Посилання
Ось всі посилання, якими ми поділилися в цій статті:
- python-bigquery-dataframes: Офіційний проект Google по створенню DataFrames на основі Python, який працює на BigQuery.
- bigquery-frames: Мій власний проект DataFrames на основі Python, який працює на BigQuery.
- Документація по BigQuery в Google: Робота з масивами.
- Git gist з кодом цієї статті.
ОРИГІНАЛ СТАТТІ:Writing SQL Like a Pro: Advanced Techniques Showcased in a Real-Life Scenario
АВТОР СТАТІ:Furcy Pin
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


