
В Інтернеті так багато блогів і відео, в яких можна знайти відповіді на запитання LeetCode. Але це здебільшого з точки зору респондента, а не з точки зору інтерв’юера.
Протягом моїх 25 років у Big Tech компаніях я провів понад тисячу співбесід (вісімсот у Amazon як Bar Raiser, кілька сотень у Microsoft та менше ста у Google).

У великих технологічних компаніях є три типи співбесід для інженерів-програмістів:
[1] Кодування,
[2] Проектування систем,
[3] Лідерство, soft skills, культура, тощо.
Цикли співбесід, як правило, поєднують ці функції. Наприклад, SDE-I може мати 3 функції кодування, 1 проектування, 1 керівництво, тоді як головний інженер може мати 1 функцію кодування, 2 проектування, 3 керівництва. Особисто я віддаю перевагу більш відкритим співбесідам на лідерські позиції, оскільки вважаю, що таким чином я дізнаюся більше про кандидатів. Але співбесіди з кодування – це необхідне зло.
Зазначення: всі питання на співбесідах з кодування — це жахливі, включаючи мої власні. У вас є 45 хвилин, щоб рекомендувати прийняття кандидата, що може змінити чиєсь життя. Люди ніколи не є собою: вони стресуються, вони втомлені, і є штучний обмежений час. Питання умовні, щоб вписатися у відведений час та отримати конкретні сигнали. Я схиляюся до вибору простіших питань, що спонукають до високоякісної розмови, де я можу дізнатися про спосіб мислення кандидата. Розмова для мене набагато важливіша, ніж фактичні рядки коду, які мій кандидат пише на дошці. Які тут існують компроміси? Як ви збалансовуєте їх? Як інтерв’юер, це не МЕНІ знати, як допомогти моєму кандидату мати хороший досвід, коли керувати, коли досліджувати, і як калібрувати мої очікування для штучного середовища.
Під час інтерв’ю з кодування я часто ставив варіації наведеної нижче проблеми, які ґрунтувалися на тому, що мені доводилося робити в реальному житті. Оскільки я вирішив відкласти це питання на потім, сьогодні я розберу його. Що я шукав? Що я бачив, як роблять кандидати?
Припустимо, у нас є веб-сайт, і ми відстежуємо, які сторінки переглядають клієнти, для таких речей, як бізнес-метрики.
Кожного разу, коли хтось відвідує веб-сайт, ми записуємо запис у журнальний файл, який складається з мітки часу, ідентифікатора сторінки та ідентифікатора клієнта. В кінці дня у нас є великий журнальний файл з багатьма записами в цьому форматі. І для кожного дня у нас є новий файл.
Тепер, маючи два лог-файли (лог-файл за день 1 і лог-файл за день 2), ми хочемо створити список “лояльних клієнтів”, які відповідають наступним критеріям: (а) вони заходили в обидва дні, і (б) вони відвідали щонайменше дві унікальні сторінки.
Це питання не особливо складне, але воно вимагає трохи міркувань і знання складності коду та структур даних. Ви легко можете отримати клієнтів, які прийшли в обидва дні, ви легко можете отримати клієнтів, які відвідали принаймні дві унікальні сторінки, але отримати перетин цих двох множин ефективно потребує трохи більше роботи.
Я, ймовірно, задавав це питання 500 разів, що дозволило мені досить добре його налаштувати. Я виявив, що рішення про найм, отримане з цього питання, відповідає остаточному рішенню про найм кандидата приблизно у 95% випадків. Я також можу використовувати його для висококваліфікованих кандидатів, що робить його досить універсальним, і є багато підказок, які я можу дати кандидатам, які мають труднощі по ходу вирішення завдання.
Задавайте уточнюючі питання
Відмінні кандидати повинні задавати уточнюючі питання перед тим, як приступати до написання коду. Я сподіваюся побачити деяку інтуїцію від моїх кандидатів, оскільки я фактично сформулював проблему в неоднозначний спосіб.
Чи я мав на увазі 2 унікальні сторінки на день чи загалом?
Це значно впливає на рішення. Я маю на увазі “2 унікальні сторінки загалом”, оскільки це набагато цікавіше завдання. Приблизно половина кандидатів відразу переходить до написання коду без уточнення цього, і з цих половина неправильно припускає, що я мав на увазі “2 унікальні сторінки на день”. Якщо це кандидат меншого рівня, я намагатимусь натякнути, перш ніж вони розпочнуть кодування. Якщо це більш досвідчений кандидат, я зачекаю трохи, щоб побачити, чи це виникне, оскільки вони думають глибше про алгоритм.
У реальному житті інженери постійно мають справу з неоднозначністю, і корінь більшості проблем з програмним забезпеченням можна віднести до погано визначених вимог. Тому я хочу отримати сигнал про те, як виявляти і вирішувати неоднозначності.
Є ще одне уточнююче питання, яке 90% людей пропускають на початку, але воно також має значення: Що з дублікатами? Відвідування однієї сторінки в той же день? Відвідування тієї ж самої сторінки в різні дні? Для цієї проблеми це є дублікати.
Ще одне уточнююче питання, яке має значення, – це про масштаб. Про який масштаб ми говоримо тут? Чи вміщуються дані у пам’ять? Чи можна завантажити вміст одного з цих файлів у пам’ять? Чи можна завантажити вміст обох файлів?
Це питання було натхнене реальною системою, над якою я працював у Amazon, званою Clickstream, яка відповідала за відстеження поведінки користувачів на amazon.com. Ми обробляли петабайти подій від мільйонів одночасних користувачів на великому кластері MapReduce з 10 000 хостів, і у нас була ціла команда інженерів, які підтримували та експлуатували її. Але для цілей 45-хвилинного співбесіди просто уявіть, що дані вміщуються у пам’ять, з набагато меншим обсягом.
Наостанок, ще одне важливе уточнююче питання – це наскільки важливість продуктивності в порівнянні з пам’яттю та збереженістю. Є просте рішення, яке має час роботи O(n²), але використовує лише O(1) пам’яті. Є краще рішення з часом роботи O(n), але використовує O(n) пам’яті. І є проміжне рішення, яке робить попередню обробку в O(n log n) з використанням O(k) пам’яті, після чого основний алгоритм має складність O(n) з використанням O(1) пам’яті. Кожне з них має свої переваги й недоліки. Деякі евристики, які ви можете використовувати для покращення продуктивності або використання пам’яті, можуть зробити код складнішим для читання та розвитку в майбутньому. Від кандидатів більш високого рівня сподіваюся активної дискусії на цю тему.
Спочатку просте рішення
У теорії ви можете написати досить простий SQL-запит, і, звичайно, великі технологічні компанії мають великі склади даних, де можна легко виконувати такі завдання. Проте для обсягу кодувального інтерв’ю вам цього не потрібно. Оскільки це не проблема розподілених систем, і дані поміщаються у пам’ять, чому вводити додаткову складність та залежності від бази даних для чогось, що можна вирішити за допомогою 20 рядків простого коду?
Вихідна точка:
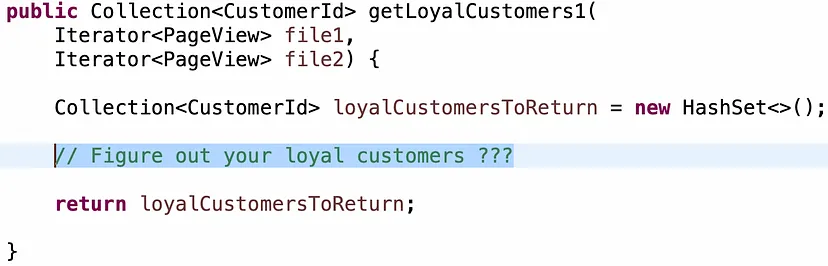
Близько 80% кандидатів спочатку вибирають наївне рішення. Це якийсь варіант “для кожного елемента з файлу 1 виконати цикл для всіх вмісту файлу 2, шукаючи елементи з таким самим ідентифікатором клієнта і відстежуючи сторінки, які вони переглядають”.
Проблема наївного рішення полягає в тому, що його час роботи становить O(n²).
Ми не проти отримувати спочатку наївне рішення, але я дійсно хочу, щоб мій кандидат мав той момент “аха”, що O(n²) ймовірно ніколи не є добрим в будь-якій проблемі. І я хочу, щоб цей момент “аха” настав досить швидко і без натяків. Ніякий великий інженер не повинен вважати за прийнятну алгоритм O(n²), якщо його не обмежує пам’ять або якісь інші незмінні обмеження.
Після того, як кандидат висловив рішення O(n²), я ввічливо посміхаю і чекаю. Я дійсно сподіваюся, що наступні слова, які будуть з їхніх уст, – це “… але складність цього – O(n²), то чи можу я зробити краще?” Якщо ні, я буду досліджувати: “яка часова складність цього рішення?” І в більшості випадків кандидат матиме момент “аха” після цього натяку і перейде до кращого рішення.
Настройка O(n²) на O(n)
На цьому етапі вам потрібно трохи подумати про те, яку структуру даних ви будете використовувати і як ви будете зберігати свої дані.
Слабкі кандидати використовують зв’язні списки або масиви. У них пошук має складність O(n), тому ви врешті-решт повернетеся до алгоритму з складністю O(n²), незалежно від вашого старання. Ви можете використовувати дерево, але оскільки пошук має складність O(log n), це все одно дасть вам загальний найкращий результат O(n log n).
Кращі кандидати мають інтуїцію, що Map надасть необхідний пошук O(1), щоб перетворити алгоритм зі складністю O(n²) на алгоритм зі складністю O(n). Великі кандидати активно вказують на те, що недолік полягає в тому, що ви будете використовувати O(n) пам’яті. Якщо ви хочете бути більш педантичними, ви навіть можете вказати на те, що використання Map має приховану вартість повторного запуску хеш-функції, що може бути дорогим. Загалом, швидший час виконання за рахунок більшої кількості пам’яті – це хороший компроміс, на який варто звернути увагу.
Якщо ви використовуєте Map, то який ключ і яке значення ви обираєте? Я бачив різні відповіді на це питання. Деякі кандидати використовують PageId як ключ, а CustomerId як значення, але це не допоможе. Потім кандидати переключаються, щоб мати CustomerId як ключ, а PageId як значення Map. Але це не особливо чудово, оскільки це не враховує того факту, що у кожного клієнта може бути багато сторінок, а не лише одна. Деякі кандидати мають інтуїцію, що їм потрібна Колекція сторінок як значення Map, але вони вибирають List, що робить мене сумним, оскільки це не враховує того, що можуть бути дублікати. Це хороший момент для дослідження знань про структури даних щодо Lists проти Sets, коли кандидати думають про обробку дублікатів.
Отже, Map> буде працювати. Але ви завантажите вміст обох файлів в одну Map? Або мати дві Maps, одну для кожного файлу? Або ви можете обійтися, просто завантаживши вміст файлу 1 в Map і обробивши файл 2 без зберігання його?
Великі кандидати розуміють, що вони можуть відразу вибрати варіант №3. Це значно менше пам’яті і простіший алгоритм. Добрі кандидати досягають цього, але потребують трохи підказок.
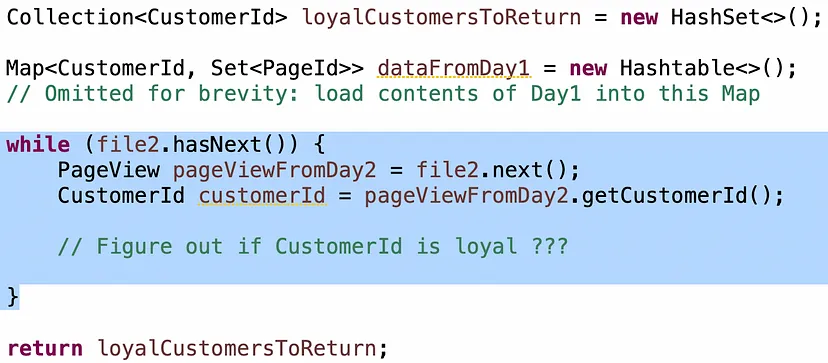
Умова “клієнти, які прийшли обидва дні”, досить проста: коли ви читаєте запис про клієнта з Day2, якщо клієнт є в Map з Day1, то ви знаєте, що він прийшов обидва дні:
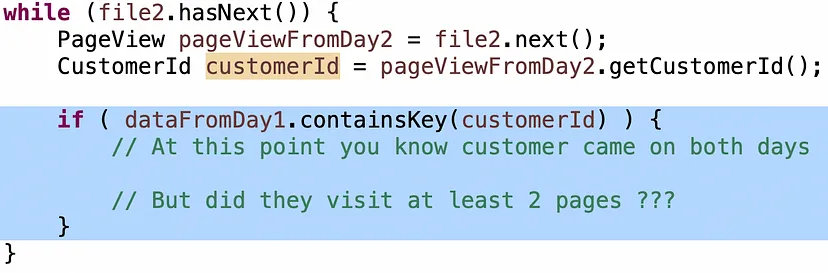
Умова “клієнти, які відвідали принаймні 2 унікальні сторінки” часто виявляється трохи складнішою для кандидатів, тому якщо вони застрягають, я даю невеличкий натяк: у вас є набір сторінок з Day1 і одна сторінка з Day2… як ви можете визначити, що це щонайменше дві унікальні сторінки?
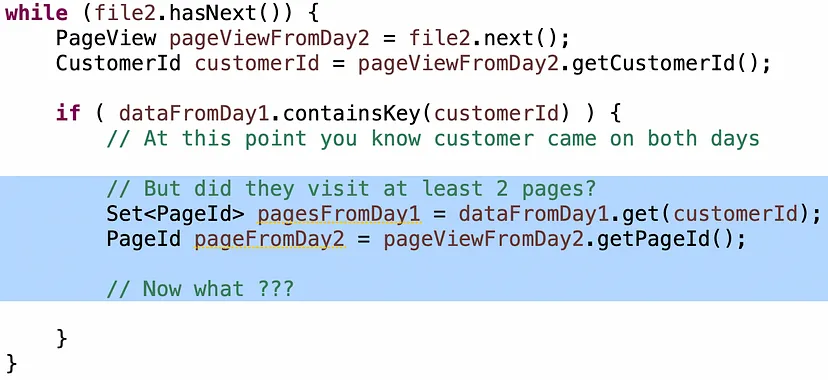
Погані кандидати будуть перебирати елементи у наборі, щоб перевірити, чи є сторінка з Day2 там. Це перетворює ваш алгоритм O(n) в O(n²) знову. Кількість кандидатів, які це зробили, дивує. Кращі кандидати будуть використовувати .contains() на множині, що є операцією O(1) для хеш-множини. Але є ще один момент з логікою.
Інтуїція, щоб це зробити правильно, така: Якщо ви всередині циклу If, і клієнт відвідав принаймні дві сторінки в Day1, і він відвідав будь-яку сторінку в Day2, він є вірним, незалежно від того, яку сторінку він відвідав в Day2. В іншому випадку він відвідав тільки одну сторінку в Day1, тому питання таке: чи це інша сторінка? Якщо так, то він є вірним, інакше це дублікат, і вам не відомо, і ви повинні продовжувати.
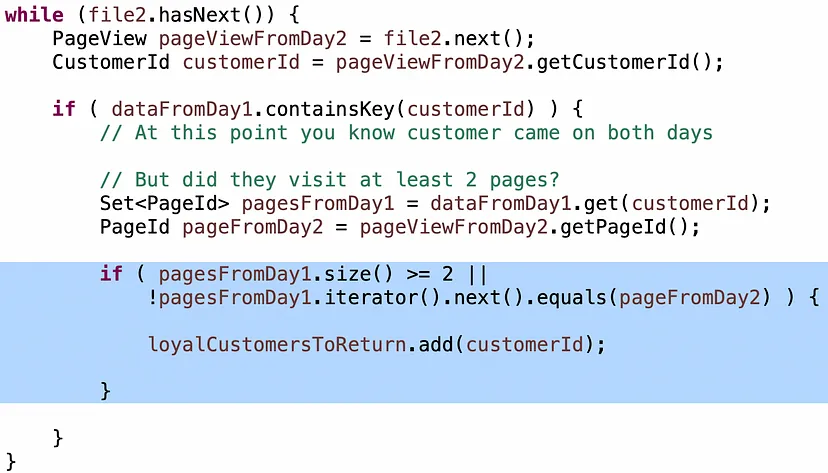
Потрібна уважність до деталей, наприклад, використання “>” замість “>=” або пропущення “!” в другому умові. Я часто бачив це. Я не хвилювався. Відмінні кандидати швидко помічали їх, перевіряючи алгоритм, коли закінчували. Хороші кандидати помічали їх після того як я трішки натякну. Це дало мені хороший сигнал щодо навичок відлагодження.
Оптимізація вашого рішення
Якщо кандидати дійшли до цього етапу і у нас є трохи додаткового часу, то цікаво провести додаткові дослідження щодо оптимізації швидкості або використання пам’яті. Додаткові бали за обговорення компромісу між ними та майбутньою збереженістю.
Наприклад, якщо пам’ять обмежена, то вам не потрібно фактично зберігати кожну окрему сторінку з Дня 1 в мапі, достатньо лише двох, оскільки проблема полягає в “принаймні двох сторінках”, тому множина розміром 2 або навіть масив розміром 2 використовуватиме менше пам’яті, ніж необмежена множина.
Або, якщо ви вже визначили, що клієнт вірний, вам не потрібно витрачати ресурси ЦП на проходження через логіку ще раз, коли ви знову зустрінете цього клієнта в День 2.
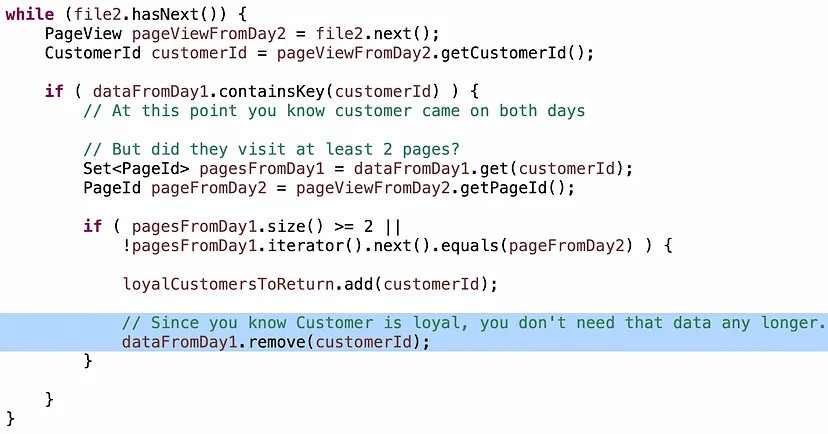
Слово про оптимізацію: можна стверджувати, що ці оптимізації ускладнюють зміну алгоритму, якщо у майбутньому зміняться вимоги. Це розумна позиція. Якщо ви можете провести хорошу розмову про переваги та недоліки, я буду задоволений високоякісною дискусією про те, як ви б збалансували ці рішення. У той же час, можливість оптимізувати алгоритм, коли це необхідно, є ознакою великого інженера, і вам доведеться це робити неодноразово протягом своєї кар’єри.
Інший варіант рішення
Більшість кандидатів вибирають підхід з використанням Map, але іноді у мене є кандидат, який обирає інший шлях. Можливо, це стається не частіше 5% часу.
А що, якщо перед обробкою файлів ви впорядкуєте їх за CustomerId, а потім за PageId?
Попередня обробка є потужним інструментом у вашому арсеналі програміста, особливо якщо ви збираєтеся виконати операцію багато разів. Ви можете витратити час на попередню обробку першого, або зробити це завчасно, що амортизує витрати часу з впливом часу. Впорядкування файлів може бути операцією зі складністю O(n log n) зі сталою кількістю пам’яті.
Якщо файли відсортовані, то проблема стає простішою, і це просто алгоритм з двома вказівниками, який можна виконати за O(n) зі сталою кількістю пам’яті. Ви переміщуєте вказівники для файлу 1 і файлу 2, поки вони обидва не будуть на одному і тому ж CustomerId, що означає, що вони приходили обидва дні. Оскільки другим ключем сортування є PageId, ви використовуєте ще один алгоритм з двома вказівниками, щоб визначити, що є принаймні дві унікальні сторінки. Це досить цікава задача! Я залишу реалізацію як вправу для читача.
В підсумку
Сподіваюся, що цей невеликий огляд однієї задачі на кодування з точки зору інтерв’юера, а також способів, якими великі, хороші та погані кандидати підходять до неї, був корисним для вас. Найкращих успіхів у вашімй наступнімй співбесіді!
ОРИГІНАЛ СТАТТІ:My favorite coding question to give candidates (and why)
АВТОР СТАТІ:Carlos Arguelles
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook: