Організація, яка прагне поліпшити використання даних та штучного інтелекту, повинна налагодити свою архітектуру даних. Припускаючи, що ви збираєтеся побудувати свою платформу даних у хмарі, ви стикаєтеся з вибором між такими рішеннями, як Snowflake, Databricks, BigQuery, Dataproc, Redshift, EMR, Synapse та інші. Все це – розумний вибір для побудови платформи даних. Кожен постачальник стверджує, що він найкращий, а POC та бенчмарки можуть бути небезпечними. У таких ситуаціях я пропоную скористатися кількома керівними принципами, щоб вибрати платформу, яка підходить саме вам.
Мої упередження
Попередження: Ця стаття містить високий рівень суб’єктивності. Отже, дозвольте мені відразу висловити свої упередження:
- Я колись працював у Google Cloud і досі маю симпатію до нього — я вважаю, що в області даних та штучного інтелекту він пропонує найбільш інтуїтивну, інноваційну та добре інтегровану екосистему. Крім того, я написав книгу про BigQuery та науку про дані на GCP.
- У мене багато друзів, які зараз працюють у Snowflake, і я вважаю, що це платформа для даних, яку найлегше експлуатувати для бізнес-користувачів.
- Багато друзів і кілька менторів зараз працюють у Databricks, і я вважаю, що це платформа для даних, яка забезпечує найкращу рівновагу між гнучкістю та простотою використання для програмістів.
- Я упереджений проти Redshift (занадто багато налаштувань), EMR (звичайна ваніль) та Synapse (багато відсутніх можливостей).
- DuckDB дивовижний, і MotherDuck (яка забезпечує високопродуктивну, вартісну та об’єднану хмарну складську систему/озеро даних) — це майбутнє. Засновники MotherDuck — мої друзі, але вона ще не готова для використання в реальних умовах.
Хоча ці упередження базуються на досвіді, такі речі, як “інноваційний”, “найлегший”, “рівновага”, “не готовий”, і т. д., є суб’єктивними. Майте на увазі мої упередження, читаючи поради нижче.
Вибір архітектури
Замість того, щоб слухати рекламні пропозиції постачальників послуг та намагатися вибрати між Snowflake і Databricks на основі частково правдивих тверджень та дефектних пілотних проектів, я рекомендую виходити з декількох визначальних принципів. Існують чотири потенційні архітектури для вашої платформи обробки даних, і вам слід спочатку вирішити, яка з них найбільш підходить для вашого бізнесу. Якщо ви оберете архітектуру, яка найкраще підходить для вашого бізнесу, вибір продукту для побудови вашої платформи обробки даних стане набагато простішим.
Оберіть архітектуру на основі навичок користувачів та характеру вашого навантаження:
- Сховище даних (data warehouse) – це архітектура даних, орієнтована на SQL, яка працює з даними, збереженими у форматі, специфічному для сховище. Оберіть це, якщо більшість ваших користувачів – це аналітики, а не програмісти, тобто вони можуть писати SQL або використовувати інструменти для створення дашбордів (наприклад, Tableau, PowerBI або Looker), які будуть генерувати SQL. Його можна використовувати для структурованих даних та напівструктурованих даних, тобто для табличних та JSON-даних, але не можна використовувати для зображень/відео/документів, окрім зберігання метаданих про них. Головна перевага сховищ даних полягає в тому, що вони дозволяють користувачам бізнесу проводити самообслуговування та ad-hoc запити.
- Озеро даних – це архітектура даних, орієнтована на код, в якій данні зберігаються на хмарних сховищах (S3, GCS, ABS), а потім читається відповідними обчислювальними кластерами для конкретних завдань або постійними кластерами. Найбільш поширеним мовою/фреймворком програмування є Python/Spark, хоча також часто використовують Java і Scala. Оберіть це, якщо більшість користувачів є програмістами, які здійснюють багато операцій з обробки даних у коді, наприклад, для написання конвеєрів ETL та тренування моделей машинного навчання. Він підтримує неструктуровані дані, такі як зображення та відео. Для структурованих та напівструктурованих даних він, як правило, менш ефективний, ніж Data Warehouse. Основна перевага Data Lake полягає в можливості гнучкої обробки даних програмістами.
- Lakehouse – це гібридна архітектура, яка дозволяє обслуговувати як бізнес-користувачів, так і програмістів. Вона підтримує як інтерактивні запити, так і гнучку обробку даних. Її можна побудувати одним з двох способів. Ви можете зробити так, щоб Data Warehouse виконував SQL на даних, збережених у хмарних сховищах у форматах, таких як Parquet. Альтернативно, ви можете використовувати фреймворк, такий як SparkSQL, для виконання SQL на сховищі Data Lake. Обидва ці варіанти – компроміси. Data Warehouse, який працює з хмарним сховищем, втрачає багато оптимізацій, які роблять його інтерактивним і придатним для адаптивних запитів. Data Lake, який працює з SQL, втрачає можливість обробки даних без схеми, що робить Data Lake настільки гнучким. Тому обирайте форму гібридної архітектури на основі того, який тип користувача і робоче навантаження ви хочете підтримувати дуже добре, а який ви хочете підтримувати компромісно. (Так, я знаю про бенчмарк, який нібито показує, що SQL озера даних перевершує сховища даних, і про тематичні дослідження, які нібито доводять, що реалізації сховища даних Spark є абсолютно гнучкими. Достатньо сказати, що вони мають свої недоліки).
- Data Mesh – це децентралізована платформа для обробки даних, яка дозволяє кожному підрозділу у вашій компанії керувати власними даними, але все ж дозволяє обмін даними без їх переміщення. Якщо всі підрозділи можуть домовитися про одне та саме хранилище даних, можливо побудувати Data Mesh на базі цього сховища даних. В іншому випадку вам доведеться побудувати її навколо Data Lake. У останньому випадку, оскільки кожний бізнес-підрозділ ймовірно матиме різний набір навичок користувачів (SQL та Python) і різний мікс потреб у робочому навантаженні (інтерактивна та гнучка обробка даних), кожен бізнес-підрозділ може обрати різну реалізацію Lakehouse.
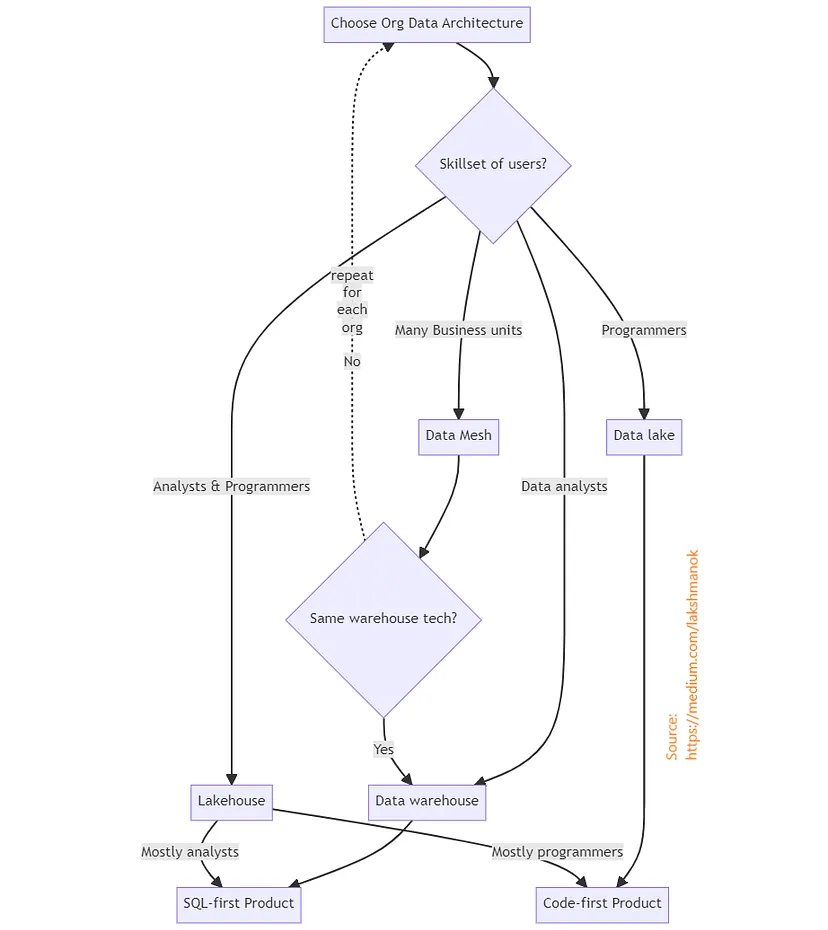
На цьому етапі ви вже визначили архітектуру даних. І в процесі вибору архітектури даних (див. вище), ви також вирішили, чи вам потрібна технологія перш за все на основі SQL для складу даних (Snowflake, BigQuery, Redshift, Synapse), чи перш за все на основі Python для озера даних (Databricks, Dataproc, EMR). Наступне рішення – вибір конкретного продукту, який працює за принципом перш за все на основі SQL або перш за все на основі Python.
Вибір продукту: малі організації
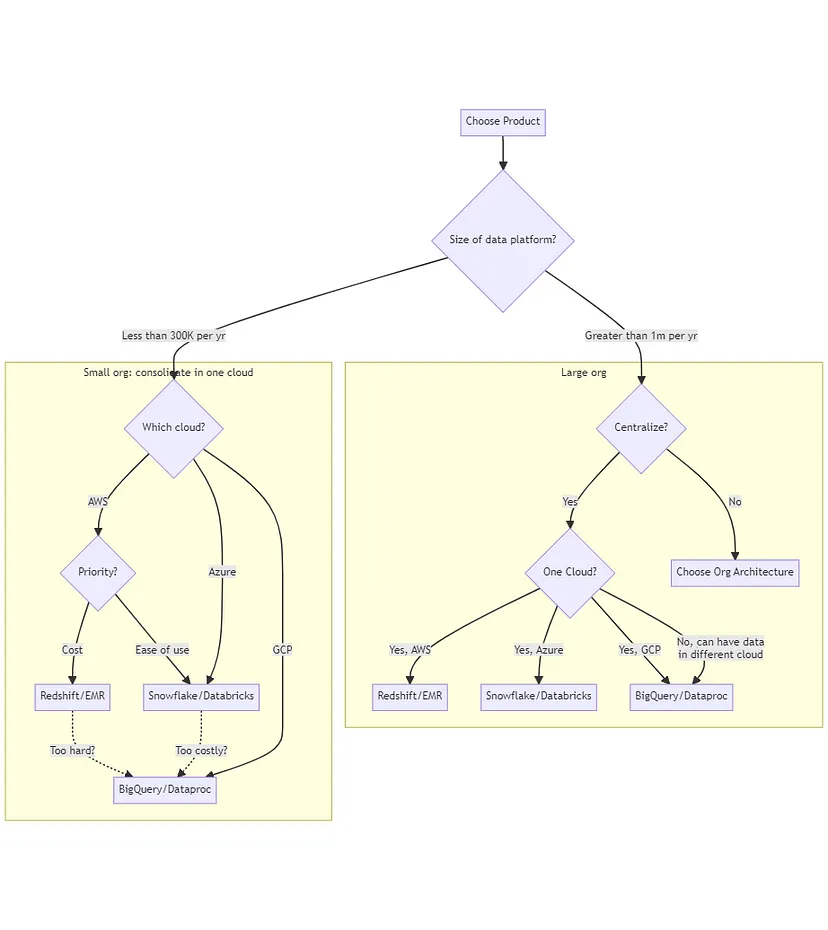
Чим менша ваша організація, тим більше сенсу приділяти увагу простоті. Наскільки малою є ваша організація? Якщо ваша хмарна платформа для даних коштуватиме менше 300 000 доларів на рік, ви малі. Якщо ваша платформа для даних буде коштувати більше 1 мільйона доларів на рік, ви великі. У проміжку цих значень, все залежить від вас – ви повинні вирішити, чи є ваша організація малою чи великою, в залежності від вашої інженерної складності.
Якщо ви представляєте невелику організацію, настійно рекомендую мати всі ваші активи в одному хмарному провайдері. Робота з двома хмарами означатиме, що вам потрібно буде підтримувати міжхмарне управління даними, укладати декілька хмарних контрактів і т. д. Вартість цього значно переважатиме будь-яку додаткову ефективність, яку може принести друга хмара. Отже, ваш вибір продукту залежить від того, на якій хмарі ви знаходитеся:
- На AWS, якщо вам важлива вартість, краще залишатися при нативному хмарному продукті – Redshift або EMR. Використання нативного хмарного продукту дешевше, ніж використання Snowflake або Databricks. Ці постачальники мають дуже напористих продажників, які часто приховують інформацію, тому тут допоможе мислення з перших принципів. Коли ви використовуєте Snowflake на AWS, ви оплачуєте маржу прибутку як AWS (~60%), так і Snowflake (~80%). Поки нативний хмарний продукт не є активно поганим, ви зекономите багато грошей, використовуючи його замість додаткової технології. Для того, щоб оптимізувати це, запити Snowflake повинні використовувати наполовину менше ресурсів, ніж Redshift. Snowflake кращий за Redshift, але не настільки багато.
- На AWS, якщо важлива простота використання, використовуйте Snowflake/Databricks. Дуже часто це може переважати над збільшеними витратами на експлуатацію. Експлуатація Redshift потребує одного інженера на повний робочий день, щоб правильно налаштувати IAM та тюнінг. Отже, якщо ваш обсяг запитів досить низький, Snowflake може бути вигідним варіантом. Розрахуйте ціну з рівнем підтримки Enterprise в Snowflake. Якщо для тюнінгу Redshift вам потрібно більше одного інженера, обсяги вашого запиту достатньо великі, щоб ви вважалися великою організацією (див. нижче).
- На Google Cloud немає причин вибирати щось інше, окрім нативного продукту хмарного середовища. Використовуйте BigQuery або Dataproc.
- На платформі Azure використовуйте Snowflake або Databricks. Synapse або HDInsight можуть виникнути проблеми з вартістю або надійністю. Немає безкоштовного обіду — враховуйте збільшення вартості платформи обробки даних як ціну, яку ви платите за використання кредитів Azure.
- Спробуйте не бути залежними від шляху. Якщо ви бачите, що GCP або Snowflake або Databricks краще підходить для вас, перейдіть до нього. Так, було б краще почати з найкращого продукту, але це не причина продовжувати жертвувати гроші та продуктивність. Виробник цільового продукту, ймовірно, навіть заплатить за ваш перехід. Так що, вже переходьте!
Вибір продукту: великі організації
Для організацій з великим обсягом аналітики/машинного навчання потрібно прийняти рішення про те, чи децентралізувати, чи стандартизувати на платформі обробки даних. Чим більш гнучка ваша організація і чим ймовірніше здійснення операцій мерджерів та придбання компаній у вашому бізнесі, тим більше сенсу вибирати децентралізоване рішення платформи. Також перегляньте, чи різні бізнес-підрозділи в вашій компанії матимуть різну комбінацію навичок користувачів (SQL проти Python) та різну потребу в роботі з навантаженням (інтерактивна проти гнучкої обробки даних). У таких випадках дозвольте кожному бізнес-підрозділу вибрати реалізацію платформи обробки даних, яка буде раціональною для нього. З іншого боку, якщо ви більш централізована організація, вибір однієї платформи дозволяє отримати більші знижки на хмарні послуги та більшу послідовність, але ціною є менша гнучкість в бізнес-підрозділах.
- Якщо ви плануєте стандартизувати, то стандартизуйте на власних хмарних продуктах. Використання власних хмарних продуктів буде дешевше, ніж використання Snowflake або Databricks (один рівень прибутку, а не два). Якщо обсяги вашого запиту стають достатньо великими, ви можете навіть обґрунтувати витрати на оптимізаційну команду та вийти вперед. Це справедливо лише для AWS та GCP.
- Якщо ви збираєтеся децентралізувати, деякі бізнес-одиниці та функції можуть надавати перевагу зручності використання, гнучкості і т. д. над вартістю. Зокрема, якщо ви на AWS або Azure, команди бізнес-аналітиків можуть обрати Snowflake, а традиційні команди даних (не машинне навчання) вибирають Databricks. На GCP, знову, немає багато причин дивитися за межі власних продуктів.
- Вибір іншого хмарного сервісу для аналітики та наукових досліджень (DS), ніж для ваших додатків, є абсолютно обґрунтованим. Витрати на вибігання даних, які нараховують публічні хмарні провайдери, та витрати на експлуатацію другого хмару можуть бути виправлені збільшеним виходом на інвестиції через кращу платформу для даних. Якщо ви вирішили стандартизувати платформу для даних в одній хмарі, щільна інтеграція між продуктами для даних Google Cloud робить його сильним кандидатом на вибір. Управління та деталізована безпека є єдиною для всіх ваших даних, чи вони знаходяться в озері даних або в складі дата-складу, а зв’язки між Spark, SQL, реальним часом та транзакційними даними безшовні. Цей вид тісної інтеграції значно прискорить ваш розвиток та допоможе утримувати витрати під контролем.
- Ваше керівництво може зворушити вас використовувати кілька хмар, щоб уникнути великої залежності від одного постачальника. Розподіл хмар за функціями (замість розподілу додатків між хмарами) може бути способом досягнення цієї мети та отримання кращої платформи для даних в нагороду.
Зверніть увагу, що блокування не є чинником, що потребує уваги. Ви будете заблоковані своєю платформою обробки даних — чи то до хмарної платформи (AWS, Azure, GCP), чи до постачальника (Snowflake, Databricks). На щастя, Spark є відкритим джерелом, і діалекти SQL різних складських даних можуть бути легко конвертовані з одного продукту до іншого за допомогою інструментів, таких як SQLglot. Тому, якщо вам дійсно потрібно мігрувати з одного на інший, це не є складним завданням. Кілька консалтингових компаній готові зробити це за кілька тижнів.
Підсумок
- Обирайте архітектуру даних головним чином на основі навичок ваших користувачів, а також на те, чи вам більше потрібна взаємодія чи гнучкість. Вибір архітектури даних також обмежує ваш вибір між продуктом, який спочатку працює з SQL, або продуктом, який спочатку працює з Python.
- Якщо ви є невеликою організацією, використовуйте власний продукт хмарного обчислення на платформі GCP та Snowflake/Databricks на Azure. На AWS обирайте між Redshift/EMR та Snowflake/Databricks, залежно від того, що є важливіше, вартість чи зручність використання.
- Якщо ви є великою організацією, вирішіть, чи централізувати чи децентралізувати. Якщо централізуєте, розгляньте використання GCP як вашої власної хмарної платформи для даних та машинного навчання. В іншому випадку скористайтеся власними хмарними продуктами на AWS. На Azure для великих організацій немає гарної відповіді. Якщо децентралізуєте, кожний бізнес-юніт приймає своє рішення на основі вартості чи зручності використання, аналогічно малій організації.
Ця стаття передусім про вибір платформи для обробки даних. Вибір платформи для машинного навчання залежить від того, хто саме в вашій компанії займається машинним навчанням — вибір між платформами без коду, з низьким рівнем коду та платформами для розробки на коді залежить від відповіді на це питання. Також важливо забезпечити спільне розташування ваших можливостей з обробки даних та машинного навчання.
ОРИГІНАЛ СТАТТІ:Snowflake or Databricks? BigQuery or Dataproc? Redshift or EMR?
АВТОР СТАТІ:Lak Lakshmanan
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


