Відкритий формат таблиці (Open table format) – це формат файлу, який використовується для зберігання табличних даних таким чином, що їх легко можна отримати та взаємодіяти за допомогою різноманітних інструментів обробки даних та аналітики. Зазвичай ці формати мають схему, яка визначає структуру таблиці і може використовуватися для різноманітних завдань, пов’язаних з обробкою даних, а також для зберігання широкого спектру типів даних, включаючи структуровані, напівструктуровані та неструктуровані дані.

Існує безліч відкритих форматів таблиць, і вони зазвичай розроблені з урахуванням ефективності, масштабованості та підтримки передових функцій, таких як версіювання, індексація та транзакції ACID. У результаті є ряд безпечних варіантів вибору, але ті, хто дійсно хоче максимально використовувати свій конвеєр даних (data pipeline) для досягнення пікової продуктивності, знають, що навіть невеликі різниці можуть накопичуватися. Таким чином, дозвольте мені звернути вашу увагу на три видатних відкритих формати таблиць та відкритих файлових формати, які точно варто розглянути: Delta Lake від Databricks, Apache Iceberg від Netflix і Apache Hudi від Uber. Незважаючи на відродження двох останніх у специфічних для галузей витоками, всі ці формати широко використовуються в різних секторах, включаючи фінанси, охорону здоров’я, роздрібну торгівлю та технології, для забезпечення ефективної та масштабованої обробки та аналітики даних. Давайте подивимося, як вони працюють кожен окремо та порівняємо їх між собою.
Давайте познайомемось з нашими форматами
Delta Lake – це рівень зберігання даних з відкритим вихідним кодом (open-source storage layer), яке розташоване поверх існуючої інфраструктури озера даних, побудованої, в свою чергу, поверх об’єктних сховищ, таких як Amazon S3. Воно забезпечує транзакції ACID та версіонність для даних, збережених в цих системах, що дозволяє інженерам (data engineer) даних та вченим з даних (data scientists) створювати надійні конвеєри (data pipelines) та озера даних (DataLake), які є високомасштабованими та надійними.

Об’єкти, збережені в прикладі таблиці Delta (клацніть для джерела)
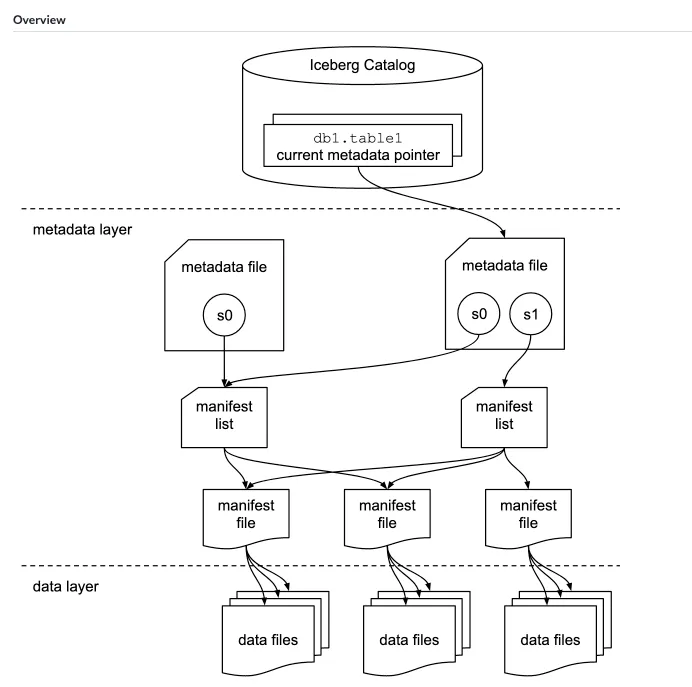
Iceberg – це ще один рівень зберігання даних з відкритим вихідним кодом, який розроблено для забезпечення ефективного та масштабованого доступу до великих наборів даних в озерах даних. Він надає схему таблиці, яка призначена для сумісності з існуючими інструментами обробки даних, такими як Apache Spark, та підтримує транзакції ACID, версіонність та еволюцію даних.
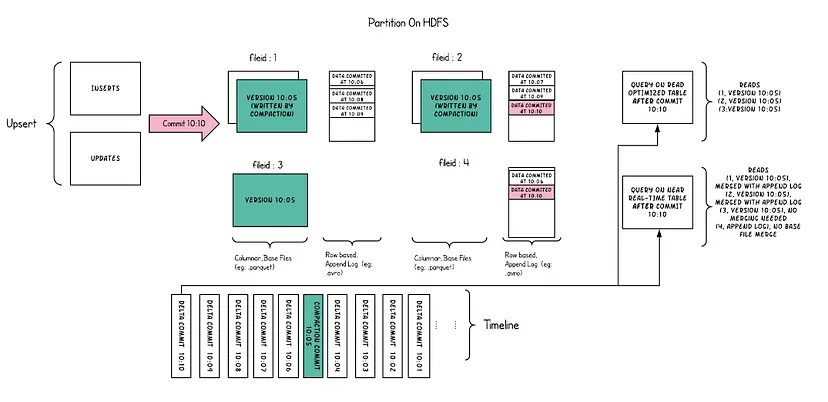
Hudi — що означає Hadoop Upserts Deletes and Incrementals — це рівень зберігання даних з відкритим вихідним кодом та фреймворк обробки даних, призначений для забезпечення доступу та аналітики даних в реальному часі. Він підтримує транзакції ACID, інкрементальну (incremental) обробку даних та ефективне індексування даних, роблячи його ідеальним рішенням для використання в таких сценаріях, як обробка потокових (streaming) даних та аналітика в реальному часі (real-time).
Коли використовувати який формат
Щодо функціональних можливостей та випадків використання, кожен з цих відкритих форматів має свої переваги та недоліки. Delta Lake ідеально підходить для озер даних та конвеєрів даних, Iceberg найбільш підходить для data warehousing та аналітики, тоді як Hudi відмінно проявляє себе у випадках використання обробки даних в реальному часі та стрімінгової аналітики.
Щодо продуктивності, кожен формат розроблено для оптимізації швидкості доступу до даних та їх обробки. Delta Lake відомий своєю високою масштабованістю та надійністю, Iceberg оптимізований для швидкої продуктивності запитів, а Hudi розроблений для ефективної прирощеної обробки даних та індексування.
При виборі між Delta Lake, Iceberg та Hudi важливо враховувати конкретні потреби та сценарії використання вашої організації. Ось деякі ключові фактори, які варто враховувати:
- Data Lake проти Data Warehouse: Якщо вам потрібно створити озеро даних, Delta Lake та Hudi можуть бути кращими варіантами, оскільки вони розроблені для роботи з інфраструктурою озера даних, такою як S3 або Azure Storage Account. Якщо вам потрібно створити склад даних, Iceberg може бути кращим вибором, оскільки він оптимізований для ефективної продуктивності запитів.
- Обробка в реальному часі проти пакетної обробки: Хочете оброблювати дані в реальному часі? Погляньте на Hudi: він розроблений саме для реального доступу до даних та аналітики в реальному часі. З іншого боку, якщо вам потрібно обробляти дані пакетами, Delta Lake та Iceberg є більш безпечними варіантами, оскільки вони підтримують пакетну обробку та конвеєри даних.
- ACID-транзакції та версіонність даних: Коли ACID-транзакції та версіонність даних є пріоритетом, всі три формати надають ці функції, але Delta Lake відомий особливо сильною підтримкою ACID-транзакцій та версіонністю.
- Еволюція даних: Коли структура ваших даних еволюціонує з часом, Iceberg – це ваш найкращий вибір завдяки його підтримці еволюції схеми та версіонності.
- Інтеграція з існуючими інструментами: Якщо ви вже використовуєте інструменти, такі як Apache Spark, Python чи Hadoop, у всіх трьох варіантах гарна інтеграція з цими інструментами, але Iceberg розроблений з урахуванням сумісності з існуючими інструментами обробки даних з самого початку.
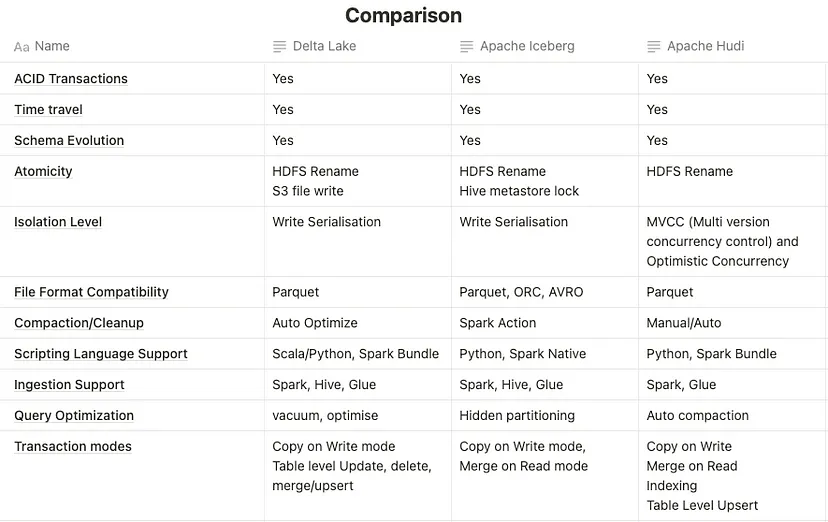
Порівняння функціональних можливостей
На цьому етапі ви, сподіваюсь, вже краще підготовлені для прийняття обгрунтованого рішення щодо того, який із трьох варіантів, представлених вище, найкраще підходить потребам вашої організації. Однак, якщо вам потрібна експертна порада щодо того, який формат найкраще відповідає вашим потребам, ми, команда Starschema, готові використати нашу експертизу в побудові повноцінних конвеєрів даних для компаній Fortune 500 та не тільки, щоб допомогти вам зробити правильний вибір і отримати максимальну цінність від нього. Зв’яжіться з нами — ми з нетерпінням чекаємо на можливість спілкування з вами.
Про автора
Анджан Банерджі – це технічний директор у сфері технологій у компанії Starschema. Він має великий досвід у створенні конвеєрів для оркестрації даних, проектуванні кількох хмарних рішень та вирішенні критичних бізнес-проблем для міжнародних компаній. Анджан застосовує концепцію інфраструктури як коду як засіб для збільшення швидкості, послідовності та точності розгортань у хмарному середовищі. Приєднуйтесь до Анджана на LinkedIn.
ОРИГІНАЛ СТАТТІ:Open Table Formats for Efficient Data Processing: Delta Lake vs Iceberg vs Hudi
АВТОР СТАТІ: Anjan Banerjee
Долучайтесь до нашої спільноти Telegram
* Data Life UA
* Data Analysis UA
* DATA ENGINEERING UA
Долучайтесь до нашої спільноти FaceBook
* Data-Life-UA


