
Десятиліттями архітектурний підхід для побудови платформ обробки даних у підприємствах були склади даних. Однак із появою технологій, таких як хмарні рішення, BigData та Hadoop, еволюція сучасних платформ обробки даних прискорилася, що призвело до появи різноманітних варіантів, таких як data lake (озеро даних) та data lakehouse (озеро-склад даних).
Згідно з публікаціями провідних постачальників хмарних послуг, data lakehouse представляє собою нове покоління платформ обробки даних. Проте запитання, яке кожен архітектор платформи даних повинен собі ставити, таке: чи є data lakehouse ідеальною архітектурою для мого конкретного використання? А може, мені краще вибрати data lake або склад даних?
Архітектура Складу Даних (DWH)
Архітектура Складу Даних (DW, DWH), також відома як Підприємницький Склад Даних (EDW), була домінуючим архітектурним підходом протягом десятиліть. Склад даних виступає як центральний сховище для структурованих даних підприємства, що дозволяє організаціям отримувати цінні уявлення. Перед записом даних в склад даних важливо визначити схему. Зазвичай склад даних заповнюється через пакетну обробку і використовується BI і запитами за потребою. Дизайн складу даних спеціально оптимізований для обробки запитів BI, але він не може опрацьовувати дані без структури. Він складається з таблиць, обмежень(constraints), ключів і індексів, які підтримують послідовність даних та покращують продуктивність аналітичних запитів. Таблиці часто розділяються на розмірні та фактичні таблиці для подальшого покращення продуктивності та корисності.
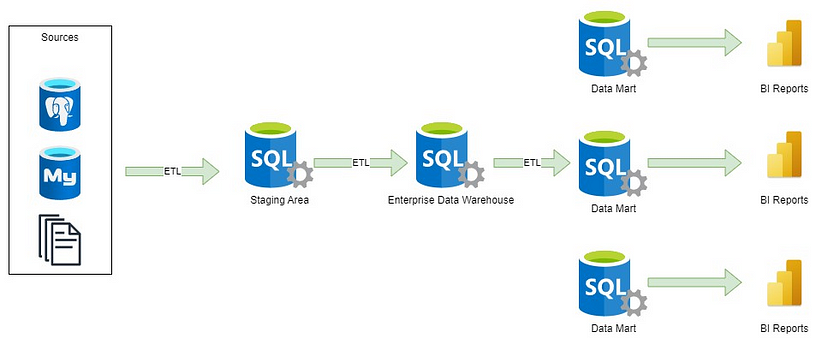
Загальний дизайн складів даних включає область стедж(stage), де сирі дані отримуються з різних джерел за допомогою ETL-інструментів, таких як Informatica PowerCenter, SSIS, Data Stage, Talend та інших. Отримані дані потім перетворюються в модель даних у межах складу даних, або за допомогою ETL-інструмента, або за допомогою SQL-запитів. Існують кілька архітектурних підходів до дизайну складу даних, включаючи методології Inmon, Kimball та Data Vault.
Шаблони дизайну для складу даних
Тепер давайте розглянемо різні шаблони реалізації складу даних. Існують кілька архітектурних підходів до проектування складу даних. У цьому пості ми надамо короткий огляд цих архітектур.
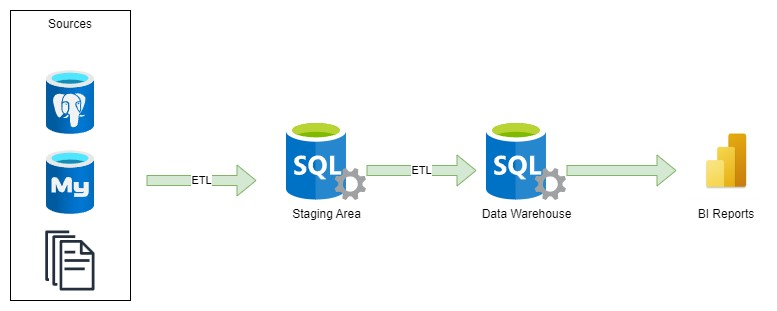
В контексті корпоративного складу даних, де різні відділи мають відмінні вимоги до звітності, реалізація окремого DataMart стає необхідною. Окремий DataMart, згідно з визначенням, є моделлю даних, спеціально оптимізованою для задоволення унікальних потреб певних бізнес-галузей або відділів. Наприклад, вимоги до звітності відділу маркетингу суттєво відрізняються від вимог відділу обліку.
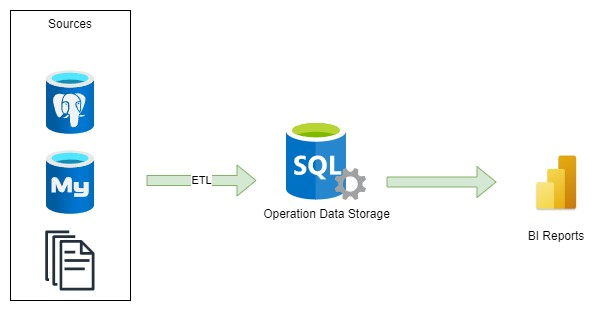
Ще однією важливою складовою інформаційної платформи є Сховище даних операцій (Operation Data Storage), спеціально призначене для зберігання найновіших даних із транзакційної системи. Його основна відмінність від Центрального сховища даних полягає в відсутності історичних даних. Сховище даних операцій призначене для полегшення більш частого імпорту даних із вихідних систем.
Сучасне сховище даних
Чи потрібен традиційне сховище даних в сучасній платформі обробки даних? Відповідь залежить від конкретної ситуації.
Якщо ми розробляємо платформу для банку або страхової компанії, де важливо дотримуватися вимог регулювальників або використовувати BI-інструменти, то традиційне центральне сховище даних залишається оптимальним підходом. Воно забезпечує структурування, підготовку та оптимізацію даних саме для цих цілей.
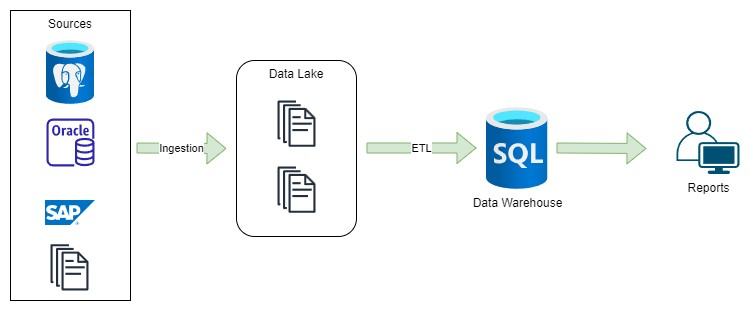
Технології, такі як Azure Synapse, Redshift, BigQuery та Snowflake, дозволяють створити стандартну модель даних, яку можна використовувати як центральне сховище даних. Інтеграція з популярними BI-інструментами, такими як Power BI, Tableau або Qlik, дозволяє генерувати необхідні звіти або видобувати дані у форматах, таких як XLSX, XML або JSON-файли. Щоб уникнути необхідності використання обширних інструментів ETL, може бути встановлений процес ELT (Export, Load, Transform) для використання даних, які безпосередньо отримано з вихідних систем. Крім того, всі вищезазначені бази даних підтримують зовнішні таблиці (External Tables), які спрощують імпорт даних з озера даних в центральне сховище даних. Створюється дворівнева архітектура.
Більше деталей про цей підхід я розгляну в подальшій частині статті, але, коротко кажучи, цей підхід дозволяє створити центральне сховище даних за допомогою платформ, таких як BigQuery, Redshift або Snowflake, використовуючи знайомий SQL та інструменти, такі як DBT (інструмент для обробки даних Data Build Tool) та фреймворк GCP Dataform для створення процесів ETL, які задовольняють вимоги звітності вашої організації.
Проте важливо враховувати, що популярні системи машинного навчання (ML), такі як TensorFlow, PyTorch, XGBoost та scikit-learn, не взаємодіють з центральним сховищем даних безперервно. Крім того, часто є потреба аналізувати дані, які можуть бути не включені в існуючу модель даних.
Дворівневе центральне сховище даних: переваги та недоліки
Переваги:
- Дані структуровані, спроектовані, очищені та підготовлені.
- Легкий доступ до даних.
- Оптимізовано для цілей звітності.
- Безпека на рівні стовпців і рядків, маскування даних.
- Підтримка транзакцій на рівні ACID.
Недоліки:
- Складність та затрати часу на внесення змін в імплементації моделі даних та процесу ETL.
- Необхідно визначити схему.
- Витрати на платформу (залежать від бази даних і її типу).
- Залежність від бази даних (складно проводити міграцію, наприклад, з Oracle на SQL Server).
Історія Data Lake
З появою нових поколінь з’явилася практика збору сирих даних, наприклад, у моделі Data Lake.
Data Lake використовували низькопробне сховище з файловим API, побудоване на Apache Hadoop (2006) та його Hadoop Distributed File System (HDFS). Дані зберігалися у різних форматах, включаючи відкриті формати файлів, такі як Avro та Parquet, відомі своїми ефективними стисненнями та продуктивністю запитів. Data Lake пропонував гнучкість завдяки підходу із схемою при читанні.
Запровадження нових технологій Hadoop та MapReduce надало вартісний спосіб (cost-effective solution) аналізу великих обсягів даних. Однак існувала альтернативна опція, що дозволяла завантажити підмножину даних у сховище даних для аналізу за допомогою BI-інструментів.
Використання відкритих форматів зробило Data Lake доступним для широкого спектру інструментів для аналізу, включаючи машинне навчання та штучний інтелект. Однак це призвело до нових викликів, таких як якість даних, управління даними та складність завдань (jobs) MapReduce для аналітиків даних. Для вирішення цих завдань було введено Apache Hive (2010), що надав доступ до даних через SQL. Відкритий характер платформи для обробки великих даних і Data Lake сприяв розробці численних інструментів. Однак ця платформа, незважаючи на свою гнучкість, також призвела до складності через різноманітність використовуваних інструментів. В результаті можна знайти вікторину під назвою “Це Pokemon чи дані Bing?” за цим посиланням, де користувачі можуть перевірити свої знання платформи.
Наступним етапом в розвитку Data Lake було введення хмарних середовищ та сховищ даних, таких як S3, ADLS та GCS, які поступово замінили HDFS. Ці нові сховища даних були безсерверними та пропонували вигоди вартості, а також додаткові функції, такі як архівування. Постачальники хмар ввели нові типи сховищ даних, включаючи Redshift (2012), Azure Data Warehouse, BigQuery (2011) та Snowflake (2014). Це сприяло впровадженню дворівневої архітектури, що поєднує Data Lake та сховище даних. Ще одним значущим досягненням став Apache Spark, який дозволяв обробку даних великих обсягів та підтримував популярні мови програмування, такі як Python, SQL та Scala.
Архітектури Data Lake
Медальйон (Medalion)
Я натрапив на кілька дизайнів дата-озера, і найпопулярнішим на сьогодні є архітектура “Медальйон”. Але, залежно від конкретного випадку використання, можуть зустрічатися і інші шаблони.
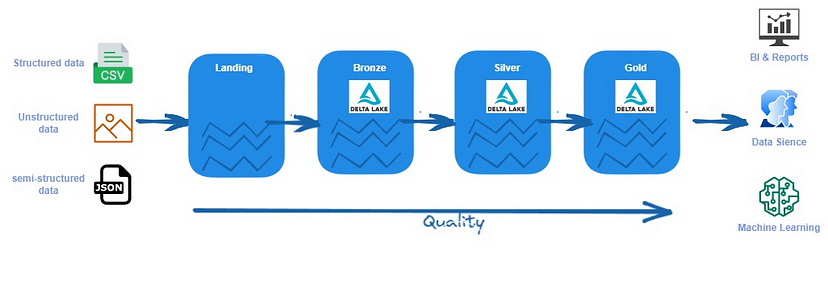
У архітектурі “Медальйон” бронзовий рівень відповідає за приймання сирих даних з джерел та їх перетворення в срібний рівень, де вони зберігаються у спільному форматі даних, наприклад, Parquet. Завершується процес агрегацією даних та їх зберіганням на золотому рівні.

Зона “Бронза/Сирий” зберігає дані у їхньому вихідному форматі (такому як JSON, CSV, XML і т. д.). Ми зберігаємо дані так, як ми їх отримуємо від джерел. Ці дані є незмінними, файли в цьому рівні доступні тільки для читання. Файли тут повинні бути організовані в папку для кожної джерела даних. Ми повинні запобігати доступу користувачів до цього рівня.
Зона “Срібло/Очищена” зберігає дані, які можуть бути збагачені, очищені та перетворені у загальні формати, такі як Parquet, Avro та Delta (ці формати забезпечують хороший стиснутий обсяг та продуктивність читання). Ми можемо валідувати дані тут, стандартизувати та гармонізувати. Ми також визначили типи даних та схему. До цього рівня мають доступ data scientists та інші користувачі.
Зона “Золото/Удосконалена” – це шар споживання, оптимізований для аналітики, а не для прийому або обробки даних. Тут дані можуть бути агрегованими або організованими у розмірній моделі даних (dimensional data model). Ви можете використовувати Spark для отримання цих даних або віртуалізації даних. У цьому випадку продуктивність може бути проблемою. Ви також можете імпортувати дані в інструменти BI для поліпшення користувацького досвіду з панелями інформації (dashboards).
Розвиток озера даних поєднується з дата-складом у вигляді дворівневої архітектури.
Альтернативою “Медальйону” може бути дворівневий дата-склад, про який я вже згадував вище, і ось я детальніше розгляну цей підхід. У цьому підході у нас є “бронза” і “срібло” у дата-складі, а потім ми завантажуємо дані в дата-склад для аналітичних цілей. Для завантаження даних ми можемо використовувати команди Bulk (пачкою) завантаження або зовнішні таблиці. BigQuery, Redshift, Snowflake та Synapse мають таку функцію, яка читає дані з файлів дата-складу та трансформує їх за допомогою процесу ELT. Цей спосіб роботи поліпшує інтеграцію, особливо коли ми використовуємо файли Parquet з визначеною схемою та хорошою продуктивністю читання.

Ми також можемо створити архівний рівень, наприклад, в окремому сховищі, щоб зменшити витрати на зберігання даних (ми можемо змінити тип зберігання, щоб зменшити витрати).
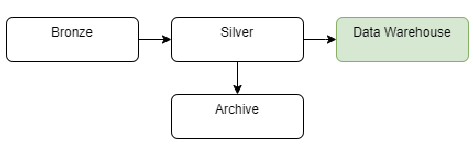
Додатково, ми можемо створити зону продукту, яка підтримуватиме інженерів даних та аналітиків у створенні власних структур і обчислень для аналітичних та машинного навчання / штучного інтелекту.
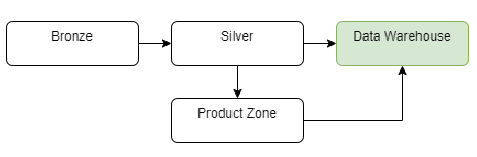
Архівна зона може бути використана для архівування старих даних для майбутніх аналізів з метою зменшення витрат на зберігання. Постачальники хмарних послуг пропонують різні типи сховищ, які мають різні часи доступу і витрати. Це гарний спосіб оптимізувати витрати на архівацію даних.
Зона продукту / робочої зони. Це шар, де відбуваються дослідження та експерименти. Тут дані вчені(data-science), інженери та аналітики можуть вільно створювати прототипи та інновації, поєднуючи свої набори даних із виробничими наборами даних. Ця зона не є заміною для тестового (test) або розробницького (dev) середовища.
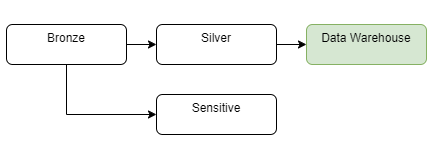
Чутлива зона – це ще один дизайн для озера даних, де потрібно мати справу з чутливими даними. Зазвичай до цього шару мають доступ лише певні користувачі, і доступ до нього більше обмежений, ніж до інших частин озера даних.
Організація папок в озері даних
Щоб уникнути утворення “болота даних”, важливо встановити просту і самоописову структуру папок в озері даних. Потрібно реалізувати правильну ієрархічну структуру, забезпечуючи, щоб папки були читабельними для людини, легко зрозумілими і самооб’яснювальними. Надзвичайно важливо визначити конвенції найменувань перед початком розробки озера даних. Ці заходи сприятимуть належному використанню озера даних та полегшать управління доступом. Крім того, важливо розуміти, як будувати структуру папок, щоб поліпшити розуміння двигуном запитів даних. Рекомендований підхід – організувати дані так, як показано в бронзовому і срібному шарах.
-Source
-Entity
-year-month-date
-files
Впровадження цієї ієрархічної структури дозволить ефективно керувати розбитими даними для запитового двигуна (query engine). Організовуючи дані в структуровану ієрархію, запитовий двигун (query engine) може ефективно навігувати та отримувати доступ до конкретних розділів, що призведе до оптимізації продуктивності та покращення можливостей отримання даних.
-SAS
-CTAS
-2023–07–07
ctas.parquet
-Source
-Entity
-files
При використанні стратегії повного завантаження для певної таблиці можливо створити структуру папок без розділення на розділи. У таких випадках, коли вся таблиця завантажується повністю, розділення (partitioned) може бути непотрібним, оскільки дані не сегментуються на основі конкретних критеріїв. Замість цього може бути встановлена проста структура папок для організації та зберігання повного набору даних.
-Salesforce
-accounts
accounts.parquet
Під час розгляду золотого шару корисно встановити структуру, орієнтовану на галузь. Цей підхід полегшує контроль доступу та покращує використання озера даних. Організовуючи дані в межах конкретних галузей, таких як клієнт, продукт або продажі, користувачі можуть легко навігувати та використовувати відповідні дані для своїх конкретних бізнес-потреб.
-Sales
-accounts
-accounts.parquet
-Finance
-time_registraion
-time.parquet
Зусилля, спрямовані на створення Lakehouse.
Коли я вперше зіткнувся із терміном “Lakehouse”, я розглядав його відмінності від традиційного підходу до даних у вигляді озера. Тоді AWS представила можливості, такі як Athena та зовнішні таблиці Redshift, і каталог Glue сприяв безперешкодному обміну метаданими між різними службами AWS. Цей розвиток дозволив створити модель даних у золотому шарі, що дозволяє запитувати дані, схожі на ті, що знаходяться в складі складу даних. Наявність SQL-двигунів, таких як Spark SQL, Presto, Hive, і зовнішні таблиці, впроваджені великими провайдерами, сприяла полегшеню запитів до озера даних. Проте залишалися виклики в таких областях, як управління даними, підтримка транзакцій ACID та досягнення ефективної продуктивності за допомогою індексів.
Data Lakehouse
Архітектура Data Lakehouse, реалізована Databricks, представляє друге покоління озер даних і пропонує унікальний підхід до розробки платформ даних шляхом поєднання сильних сторін Data Lake і Data Warehouse. Він служить єдиною уніфікованою платформою для розміщення як сховища даних, так і озера даних. Архітектура Data Lakehouse не тільки підтримує транзакції ACID, як традиційне сховище даних, але також забезпечує економічну ефективність і масштабованість сховища в озері даних. Ця архітектура забезпечує прямий доступ до всіх рівнів озера даних і включає підтримку схем для ефективного керування даними. Крім того, Data Lakehouse представляє такі функції, як індекси, кешування даних і подорожі в часі для підвищення продуктивності та функціональності. Він продовжує підтримувати як структуровані, так і неструктуровані типи даних, дані зберігаються у форматах файлів.
Для впровадження архітектури Lakehouse Databricks розробила новий тип файлу під назвою Delta (детальніші відомості про формати файлів будуть наведені пізніше в цій статті). Однак, як альтернативи Delta, можуть використовуватися інші формати файлів, такі як Iceberg та Apache Hudi, що пропонують подібні можливості. Ці нові формати файлів дозволяють Spark використовувати нові команди маніпулювання даними, що покращують стратегії завантаження даних. У Data Lakehouse оновлення рядків у таблиці можуть виконуватися без необхідності повного перезавантаження всього набору даних в таблиці.
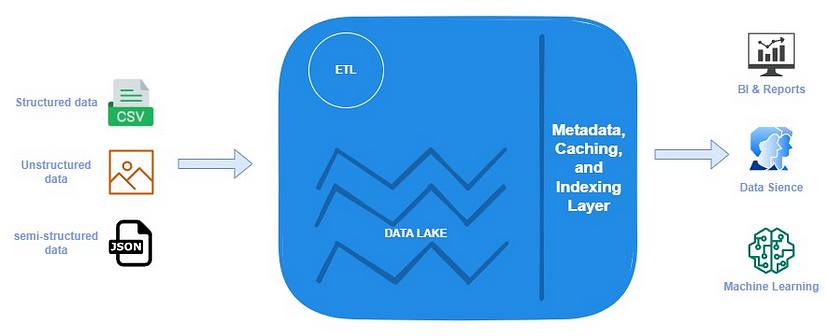
Архітектура Data Lakehouse
Архітектура Data Lakehouse організовує дані в основному за допомогою архітектури «медалі». Як я вже зазначив, у нас є три шари Data Lakehouse: Бронза, Срібло та Золото. Основна різниця у разі використання Data Lakehouse буде полягати в форматі файлу. Ми використовуємо формат Delta для зберігання даних. За альтернативу Delta можна використовувати формати Iceberg або Apache Hudi, які пропонують схожі можливості. Ці нові формати файлів дозволяють Spark використовувати нові команди обробки даних, які покращують стратегії завантаження даних. В архітектурі Data Lakehouse можна виконувати оновлення рядків у таблиці без необхідності повного перезавантаження всього набору даних у таблиці.
Бронзовий шар використовується для введення даних з джерел «як є» (as-is). Дані вирівнюються з джерелами та організовуються у сховищі. Якщо ми імпортуємо дані з джерел, ми зберігаємо їх у форматі Delta. Дані можна вводити за допомогою інструментів інєкцій (ingest tools) та зберігати у вихідному форматі, якщо вони не підтримують Delta або коли джерела системи вивантажують дані безпосередньо в сховище.
Срібло зберігає дані, які були очищені, уніфіковані, перевірені та збагачені довідковими даними або даними майстра. Бажаний формат – Delta. Таблиці все ще відповідають джерелам системи. Цей шар можуть використовувати вчені з обробки даних (Data Science), ad-hoc звіти, розширена аналітика та машинне навчання.
Золотий шар містить модель даних, яка використовуватиметься бізнес-користувачами, BI-інструментами та звітами. Ми використовуємо формат Delta. Цей шар містить бізнес-логіку, яка включає обчислення та збагачення. Ми можемо мати лише конкретний набір даних зі срібла або лише агреговані дані. Структура таблиць в цьому шарі спрямована на предмети дослідження.
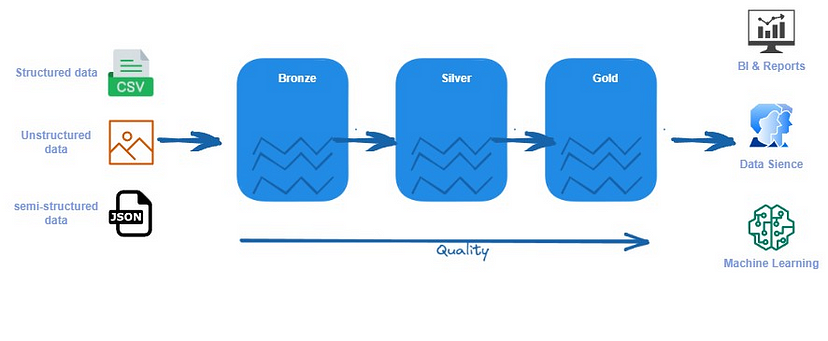
Data Vault з Lakehouse
Інший підхід до організації Lakehouse – використовувати методологію Data Vault. Цей метод особливо підходить для організацій, які мають справу з великою кількістю даних, багатьма джерелами даних і частими змінами інтеграції. Паттерн Data Vault схожий, але включає важливі зміни в моделюванні та організації даних.
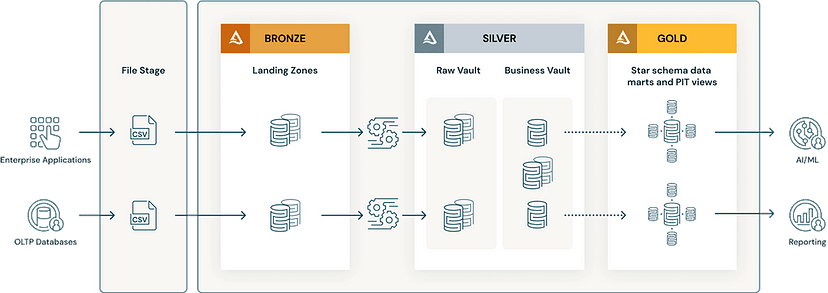
Бронзовий рівень відповідає за прийом даних з джерел систем та зберігання їх у первинній структурі “як є”. Додаткові стовпці з метаданими, такі як час завантаження та ідентифікатор пакету, можуть бути додані. Цей рівень зберігає історичні дані, дельта-завантаження та зміну захоплення даних. При імпорті даних з джерел систем рекомендується зберігати їх у форматі Delta для підвищення продуктивності. У випадках, коли дані надходять у різних форматах, використання зони приземлення (landing) та зони підготовки (stage zone) або додаткового приземленого рівня може полегшити приймання даних з джерел систем. В таких сценаріях дані зберігаються у їх первинному форматі, а потім перетворюються у формат Delta в зоні Бронзи/підготовки. Інструмент AutoLoader від Databricks може бути використаний для оптимізації процесу перетворення в зоні Бронзи/підготовки.
Срібний рівень, який часто називають корпоративним сховищем, містить очищені, об’єднані та перетворені дані з бронзового рівня. Ці дані можуть бути легко використані користувачами для підтримки їхніх процесів звітності, продвинутої аналітики та машинного навчання. З точки зору моделювання даних, цей рівень використовує третю нормальну форму і використовує принципи методології Data Vault для адаптації до швидких змін. Зазвичай модель Data Vault охоплює три типи сутностей:
- Hubs представляють основну бізнес-сутність, таку як клієнти, продукти, замовлення тощо. Аналітики використовуватимуть природні/бізнес-ключі, щоб отримати інформацію про Hub. Первинний ключ таблиць Hub, як правило, походить від комбінації бізнес-концепції ID, дати завантаження та іншої метаданих, яку можна отримати за допомогою функцій Hash, MD5 та SHA.
- Links представляють відношення між сутностями Hub. Вони мають лише ключі для об’єднання. Це схоже на таблицю Factless Fact в концепції структурованої моделі. Відсутність атрибутів — лише ключі для об’єднання.
- Таблиці Satellite містять атрибути сутностей в Hub або Links. Вони містять описову інформацію про основні бізнес-сутності. Це схоже на нормалізовану версію таблиці Dimension. Наприклад, Hub продукту може мати багато таблиць Satellite з атрибутами типу, вартостями тощо.
Таблиці організовані за областями, такими як Клієнти, Продукти або Продажі.
Золотий Шар слугує основою для моделей складу даних або окремих складів даних. Дотримуючись підходу розмірної моделі, такого як методологія Кімбол, цей шар акцентується на звітності. Користувачі можуть використовувати BI-засоби для використання даних з цього шару або для виконання ад-гок звітності. Також можуть бути створені окремі склади даних в Золотому Шарі, щоб відповідати конкретним потребам в моделюванні даних для різних відділів. Організація даних за проектами або сценаріями використання, такими як C360, маркетинг або продажі, сприяє зручності споживання даних за допомогою структур “зоряної схеми”.
Дельта – це формат для зберігання даних з відкритим кодом, який був представлений компанією Databricks і спрямований на надійну та високопродуктивну обробку даних. Він пропонує можливості транзакцій ACID, контроль версій, еволюцію схеми та ефективні операції зі внесення даних та запитів. Дельта часто використовується в середовищі Apache Spark та підтримує як пакетні, так і потокові завантаження даних. Він надає можливості, такі як компактизація даних, пропускання даних та запити з можливістю подорожі в часі, що дозволяє ефективно керувати та аналізувати дані.
Iceberg – це формат таблиць з відкритим кодом, розроблений компанією Netflix, спеціально призначений для великих озер даних. Його основний акцент зроблено на забезпеченні відповідності ACID, можливості подорожі в часі та еволюції схеми, забезпечуючи при цьому відмінну продуктивність та масштабованість. Iceberg працює добре з популярними рушіями запитів, такими як Apache Spark та Presto. Він надає можливості ефективної маніпуляції даними, статистики на рівні стовпців та управління метаданими. Iceberg дозволяє користувачам виконувати швидкі, послідовні та надійні аналітичні операції над великими наборами даних.
Apache Hudi – це відкритий програмний продукт від компанії Uber, який був розроблений для підтримки приростових оновлень в форматах даних, які зберігають дані у вигляді стовпців. Він підтримує завантаження даних з різних джерел, в основному Apache Spark та Apache Flink. Також надається засіб на основі Apache Spark для читання зовнішніх джерел, таких як Apache Kafka. Підтримується читання даних з Apache Hive, Apache Impala та PrestoDB. Також існує окремий інструмент для синхронізації схеми таблиці Hudi в Hive Metastore.
UniForm
У майбутньому Delta Lake 3.0 прагне надати універсальний формат (UniForm) для всіх трьох форматів. Мета полягає в тому, щоб таблиці Delta Lake були доступні як таблиці Hudi або Iceberg. UniForm наразі перебуває в режимі попереднього доступу, і є обмеження.
Data Lake та Data Warehouse або Lakehouse
Чи Lakehouse – найкращий підхід для впровадження? Як завжди, відповідь – “це залежить від ситуації”.
Існують різні фактори, які слід враховувати при виборі архітектури. Наприклад, якщо ваша мета – працювати з BigQuery, Snowflake, Synapse або Redshift, використання дворівневої архітектури залишається гідним вибором. Це дозволяє вам використовувати переваги Data Lake, при цьому розміщаючи свій дата-модель в базі даних DBMS. Важливо враховувати, що концепція Lakehouse все ще відносно нова і не така зріла, як інші архітектурні парадигми. Використовуючи як Data Lake, так і Data Warehouse, ви можете використовувати сильні сторони кожної платформи і користуватися різними навичками у своїх командах. Наприклад, ваша команда інженерів даних може використовувати Python і Spark, тоді як команди, спрямовані виключно на Data Warehouse, можуть використовувати SQL.
Важливо провести ретельний аналіз при виборі механізму Data Warehouse, оскільки кожен варіант має свій набір обставин, таких як конкурентоспроможність, автомасштабування, відокремлення обчислень від зберігання, інтеграція з форматами файлів, такими як Delta, Iceberg і Hudi, обмежена сумісність з неінтегрованими хмарними постачальниками, клонування без копіювання, налаштування продуктивності, витрати, підтримка географічно-інформаційних систем і зусилля з обслуговування. Data Warehouse пропонує міцні можливості щодо дотримання консистентності даних та управління даними. Вони обладнані вбудованими механізмами для перевірки даних на предмет якості, валідації даних та виконання політик управління даними. Такі можливості дуже важливі для організацій із суворими вимогами до управління даними та відповідності.
Дворівнева архітектура є відповідним вибором при роботі зі складними процесами ETL та коли не потрібна потужність для відображення даних. У таких випадках використання Data Lake разом із Spark для обробки даних, поєднане з відкритою базою даних, такою як PostgreSQL, для обслуговування даних, може бути ефективним підходом.
Якщо у вас виникли питання або ви хочете подетальніше обговорити архітектуру платформи даних, не соромтеся зв’язатися зі мною на LinkedIn.
АВТОРИ СТАТІ: Mariusz Kujawski
ОРИГІНАЛ СТАТІ:Data Lakehouse vs Data Warehouse vs Data Lake – Comparison of data platforms
Долучайтесь до нашої спільноти Telegram
* Data Life UA
* Data Analysis UA
* DATA ENGINEERING UA
Долучайтесь до нашої спільноти FaceBook
* Data-Life-UA


