Вступ
Але, але, але, одна велика таблиця (OBT) не може впоратися з ієрархіями! Так, я це сказав. Ви ризикуєте спричинити проблеми у вашій системі управління даними. Інші теж так говорять. Моделювання Кімболла мертве, OBT революціонізує сучасний стек даних. Статті на Medium все більше і більше говорять про це. Як може всіх так помиляти OBT, а водночас бути таким правильним?
Давайте почнемо з короткої історії. Я нещодавно написав відповідь на статтю, в якій тверджувалася домінантність OBT в сучасних системах управління даними. Невдовзі після публікації мені підкинули проект, в якому OBT було обов’язковим вимогам. Цікаво, як це працює. Немає проблем. Я люблю виклики, тому я глибше вник у проектування OBT. Я шукав в Google, переглядав Reddit, публікував на Reddit, публікував на LinkedIn, і все поверталося тим же. Немає канонічного визначення OBT, і практично у кожного є свої власні ідеї про те, що таке OBT.
Ми часто сперечаємося щодо OBT, не розуміючи, що інша сторона говорить про щось абсолютно різне. Єдине спільне – це у нас є одна велика таблиця, і ми хочемо полегшити опитування для кінцевих споживачів. Так що давайте перестанемо сперечатися щодо OBT і розглянемо загальні реалізації та випадки використання. Сконцентруємося на чомусь корисному.
Подивимося на деякі дані
Уявіть кабінет консультування. У нього є клієнти та три відмінні процеси для відстеження: введення в роботу, візити та оплата. Є ієрархія процесів, які всі підпадають під клієнтів. У цьому випадку є простою ситуацією, з лише двома рівнями ієрархії, але принципи, які ми розглядаємо, не зміняться через кількість рівнів.
Примітка: Якщо ви не дивилися “Сучасну сім’ю”, будь ласка, знайте, що ці адреси електронної пошти є відповідними та смішними (принаймні для мене).
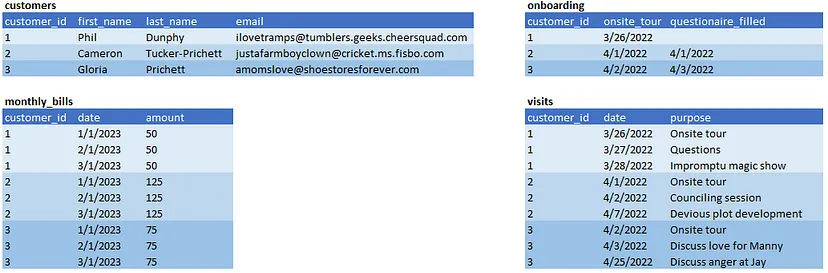
Це виглядає як загальний спосіб зберігання даних.
Визначення типів OBT
Без канонічних визначень для OBT корисно визначити загальні типи та прогресії дизайну. Нижче ми побачимо реалізації, які ростуть у корисності та складності. Подумайте про випадки використання, які вирішували б кожен тип для ваших споживачів. Чи допомагали вони? Або чи вони спричиняли більше плутанини?
Тип 0 — Кілька денормалізованих факт-таблиць (багато OBT)
Цей спосіб простий. Візьміть факт-таблицю одного зерна та замініть зовнішні ключі стовпцями розмірності. Це найбільш поширений тип OBT, і він зменшує потребу в приєднанні до таблиць розмірності.
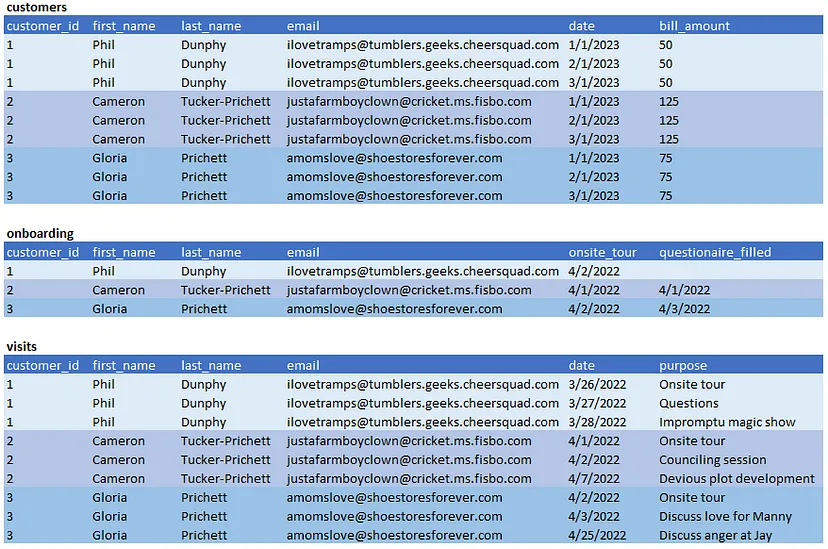
Що це дає нам
- Легко запитуйте факти з включеними розмірними атрибутами.
Проблеми?
- Насправді жодних. Мабуть, більшість з нас робить це десь на рівні звітності.
Тип 1 — Ієрархічний OBT
Тип 1 показує загальний підхід до побудови єдиної OBT з кількома зернами. Ми робимо це за допомогою ієрархії, яка представляє сутності та бізнес-процеси. Поглянувши на результати, стає зрозуміло декілька правил.
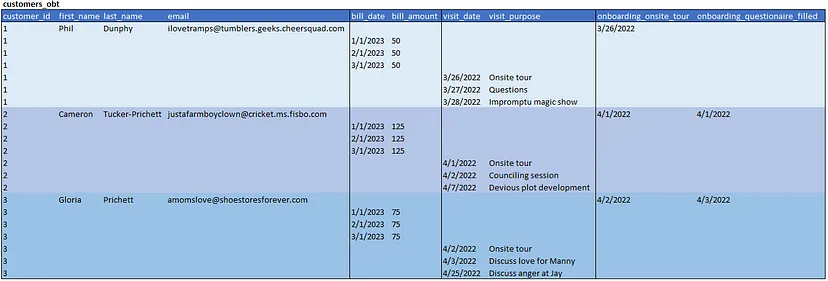
- 1-до-1 відносини додають стовпці, але не рядки (див. onboarding).
- 1-до-* відносини додають стовпці та рядки (див. billing та visits).
- Кожен рядок заповнює лише свій батьківський ідентифікатор та стовпці, необхідні для
- конкретного зерна рядка. Це створює таблицю з розрідженим заповненням.
- Рядки, що представляють верхівку ієрархії, обробляються як розмірність SCD типу 1. Ми
- показуємо поточне значення ім’я, прізвище та електронна пошта.
- Кожен інший рядок розглядається як факт. Ймовірно, він тільки додається.
Що це нам дає?
Що це нам дає?
Це мій найменший улюблений рівень OBT. Ми отримуємо всю інформацію про клієнта в одній таблиці. Молодці! В той же час ми ускладнюємо запити порівняно з оригінальними розмірними моделями. Тим не менш, ми можемо:
- Запитуйте інформацію про оплату, введення та візити за customer_id.
- Легко сумувати або підраховувати різні факти, групуючи їх за customer_id.
- Легко створити цю модель.
- Легко відзаповнювати. Оскільки у нас немає багато логіки, відзаповнення просте.
- Я думаю. Я думаю, … Я думаю, це все.
Проблеми?
- Необхідний DISTINCT, просто щоб знайти кількість клієнтів.
- Потрібні самоз’єднання або віконні функції для включення розмірних полів, таких як електронна адреса, у запитах, що стосуються оплати або візитів.
- Відсутність відстеження змін. Що відбувається, якщо Камерон змінює своє прізвище? Ми будемо знати поточне ім’я, але не будемо знати, яким воно було раніше. Це може становити проблему для споживачів вниз по ланцюжку.
Type 2 — Рівні ієрархії
Рівень 2 – це те, де ієрархічний OBT починає бути корисним. Він включає всі особливості рівня 0, але додає рівні ієрархії. Кожен рівень ієрархії представляє, де в бізнес-ієрархії вписується рядок. Це може значно спростити запити.
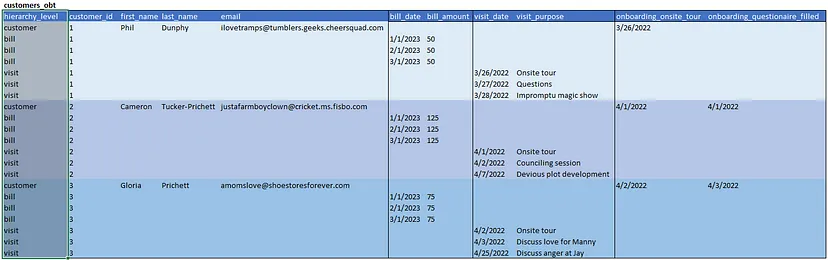
Що ми отримуємо
- Все, що в Type 1
- Здатність легко запитувати на рівні клієнта.
- Здатність легко запитувати на рівні оплати і візитів. (Простий where clause замість полювання на нульові значення.)
Проблеми
Distinct потрібний, щоб знайти кількість клієнтів.- Потрібні self join або віконні функції для включення розмірних полів, таких як електронна пошта, в запити, які стосуються рахунків або візитів.
- Відсутність відстеження змін для розмірних атрибутів. Що відбудеться, якщо Камерон змінить своє прізвище? Ми будемо знати поточне ім’я, але не будемо знати, яким воно було раніше. Це може бути проблемою для підсистеми, що використовує ці дані.
Тип 2 — Додані показники
Тип 2 дійсно стає корисним. Щоб уникнути потреби в складних SQL-запитах для агрегацій, ми додаємо загальні агрегації на рівень клієнта в ієрархії. На зображенні нижче ми додали загальну суму оплат і візитів. Уявіть, що ми додаємо показники для речей таких, як місяць, минулі тридцять днів, останні дев’яносто днів, з початку року тощо. Якщо це є загальними запитаннями, ми можемо розрахувати їх один раз на день і спростити завдання для споживачів даних.
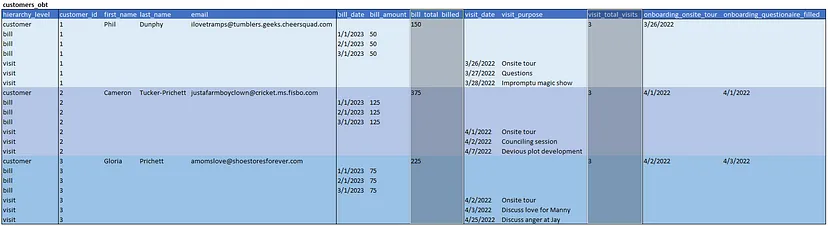
Що ми отримуємо
- Все, що в Type 1
- Загальні агрегаційні запити з простим where-виразом (вибрати email, bill_total_billed з customers_obt, де customer_id = 1)
Проблеми
- DISTINCT потрібно використовувати лише для знаходження кількості клієнтів. (Вирішено для загальних агрегацій, таких як total, L7, L30, YTD і т. д.)
- Потрібно використовувати self join або віконні функції, щоб включити розмірівські поля, такі як електронна пошта, в запити, які стосуються оплати чи візитів. (Вирішено для загальних агрегацій, таких як total, L7, L30, YTD і т. д.)
- Відсутність відстеження змін для розмірівських атрибутів. Що станеться, якщо Камерон змінить своє прізвище? Ми будемо знати поточне ім’я, але не будемо знати, яким воно було раніше. Це може бути проблемою для консолідованих додатків.
Тип 3 — Каскад
З типом 3 ми каскадно передаємо всі розмірівські атрибути від батьківської ієрархії до всіх рівнів ієрархії. Це робить багато запитів набагато простішими. Якщо нам потрібні розмірівські атрибути, такі як ім’я чи електронна пошта на рівні візитів, ми маємо це. Хоча це може здаватися очевидним, це додає багато складності при обслуговуванні таблиці. Ми можемо вирішити передавати також міри.
Тут потрібно прийняти два основні рішення. По-перше, чи оновлюємо розмірівські атрибути на дочірніх рядках, коли змінюються значення на батьківському рядку? Якщо так, ми втрачаємо відстеження змін. Допустимо, Кем Такер-Прічетт змінив своє прізвище на Такер. Як це сприйматимуть консолідовані додатки при перегляді візитів?
По-друге, передавати міри, такі як загальна кількість візитів і всього оплачено? Це полегшить отримання всіх щомісячних рахунків для клієнтів з більше ніж десятьма візитами. Складність обох питань полягає в необхідності обробляти кожен рядок в таблиці, як тип 1 SCD. Це компроміс між складністю інженерії та зручністю використання для споживача.
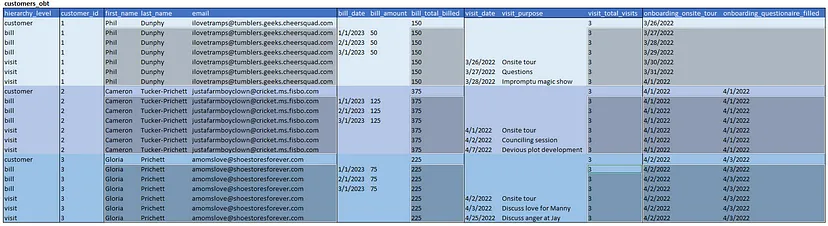
Що ми отримуємо
- Все, що є в типі 2
- Легко робити запити вздовж фактів. (Отримати історію розрахунків для всіх клієнтів, які відвідали більше 10 разів. Отримати ім’я, електронну пошту та дату останнього візиту для всіх клієнтів, які ще не завершили введення в експлуатацію.)
Проблеми ?
Потрібно визначити, лише щоб знайти кількість клієнтів.Функції самостійного входу чи вікон потрібно включити вимірювальні поля, такі як електронна пошта, у запитаннях, що включають рахунковий облік або візити. (Вирішено для загальних агрегацій, таких як загальна, L7, L30, YTD тощо.), щоб знайти кількість клієнтів.Немає необхідності змінювати відслідковування для вимірювальних атрибутів. Що станеться, якщо Камерон змінить своє прізвище в останнє? Ми будемо знати поточне ім’я, але не будемо знати, що воно використовувалося раніше.Це може бути проблемою в нижченаведених застосунках, якщо ми не оновлюємо дочірні рядки, коли змінюється батьківський рядок.- Складність обслуговування таблиці може зростати експоненційно. У деяких сценаріях всі рядки ведуть себе як записи типу-1 для міток часу.
- Назаднє заповнення може бути значно більш складним. (Див. вище.)
Завершуючи
Спростовування OBT нікуди нас не приведе. Замість цього давайте сконцентруємося на визначенні шаблонів і рішень, щоб отримати максимум від них. Ми обговорювали чотири типи OBT разом з їхніми перевагами та недоліками. Для того, щоб домовитися про канонічні визначення для типів 1–3, ще потрібно виконати деяку роботу, але ми можемо це зробити. Наразі давайте погодимося, що OBT – це один великий стіл.
Додаток 1
Якщо ви хочете знати, куди направляються мої замутнені думки, кожного разу, коли я чую “One Big Table”, ось вам це.
Додаток 2
Мене дуже цікавить співпраця з нашою спільнотою для створення канонічних визначень для OBT. Крім того, ми повинні вигадати найкращі методи та шаблони для обслуговування архітектури OBT. Будь ласка, залишайте свої думки у коментарях, або, краще ще, поділіться власними статтями.
ОРИГІНАЛ СТАТТІ:Designing One Big Table (OBT)
АВТОР СТАТІ:Leo Godin
Долучайтесь до нашої спільноти Telegram
* Data Life UA
* Data Analysis UA
* DATA ENGINEERING UA
Долучайтесь до нашої спільноти FaceBook
* Data-Life-UA


