
Ця стаття містить огляд внутрішнього технологічного стеку, який ми використовуємо щодня як інженери даних в Meta. Ідея полягає в тому, щоб пролити світло на роботу, яку ми виконуємо, і на те, як інструменти та фреймворки допомагають зробити нашу повсякденну роботу з інженерії даних більш ефективною, а також поділитися деякими дизайнерськими рішеннями та технічними компромісами, які ми прийняли на цьому шляху.
Сховище даних
Те, що ми називаємо сховищем даних, є основним сховищем даних Meta, яке використовується для аналітики. Воно відрізняється від живої “бази даних графів” (TAO), яка використовується для надання контенту користувачам у реальному часі. Це колекція мільйонів таблиць Hive, які фізично зберігаються за допомогою внутрішнього форку ORC (про який ви можете прочитати більше тут). Наше ексабайтне сховище даних (один ексабайт дорівнює 1 000 000 терабайт) настільки велике, що фізично не може зберігатися в одному дата-центрі. Натомість дані розподілені по різних географічних точках.
Оскільки сховище фізично не розташоване в одному регіоні, воно розділене на “простори імен”. Простори імен відповідають як фізичному (географічному), так і логічному поділу сховища: таблиці, які відповідають схожій “темі”, згруповані разом в одному просторі імен, щоб їх можна було ефективно використовувати в одних і тих же запитах без необхідності передавати дані між локаціями.
Якщо в запиті потрібно використовувати таблиці з двох різних просторів імен (наприклад, таблицю 1 в просторі імен A і таблицю 2 в просторі імен B), нам потрібно реплікувати дані: або ми можемо вибрати реплікацію таблиці 2 в простір імен A, або реплікацію таблиці 1 в простір імен B. Після цього ми можемо запустити наш запит в тому просторі імен, де існують обидві таблиці. Інженери даних можуть створити ці перехресні репліки просторів імен за кілька хвилин за допомогою веб-інструменту, і вони будуть автоматично синхронізовані.
Хоча простори імен розділяють все сховище, таблиці також розділені між собою. Майже всі таблиці у сховищі мають стовпець розділу ds (ds для позначки дати у форматі YYYY-MM-DD), яка, як правило, є датою створення даних. Таблиці також можуть мати додаткові стовпці розділів для підвищення ефективності, і кожен окремий розділ зберігається в окремому файлі для швидкого індексування.
Дані зберігаються в системах Мета лише протягом періоду часу, необхідного для виконання мети, для якої вони були зібрані. Таблиці у сховищі майже завжди мають обмежений термін зберігання, а це означає, що розділи, які перевищують термін зберігання таблиці (наприклад, 90 днів), автоматично архівуються (анонімізуються та переміщуються до служби холодного зберігання) або видаляються.
Всі таблиці пов’язані з групою виклику, яка визначає, яка команда володіє цими даними, і до кого користувачі повинні звертатися, якщо вони зіткнуться з проблемою або мають питання щодо даних у цій таблиці.
Як дані записуються до сховища?
Існує три найпоширеніші способи запису даних до сховища:
- Робочі процеси(Workflow) та конвеєри даних, наприклад, дані, які вставляються за допомогою конвеєра Dataswarm (докладніше про це нижче), зазвичай отримуються шляхом запитів до інших таблиць у сховищі,
- Журнали, наприклад, дані, отримані від серверних або клієнтських фреймворків для ведення журналів.
- Щоденні знімки сутностей у базі даних виробничого графіка.
Виявлення даних, каталог даних
Коли маєш справу з таким величезним сховищем, пошук даних, необхідних для аналізу, може здатися спробою знайти голку в копиці сіна. На щастя, інженери компанії Meta розробили веб-інструмент під назвою iData, в якому користувачі можуть просто шукати за ключовим словом. iData знайде і відобразить найбільш релевантні таблиці для цього ключового слова. Це пошукова система для сховища даних: iData впорядковує результати пошуку в інтелектуальний спосіб, який, як правило, знаходить таблицю, яку ви шукали, в перших результатах.
Щоб показати найкращі результати, вона враховує кілька характеристик кожної таблиці: свіжість даних, документацію, кількість подальших використань (у спеціальних запитах, інших конвеєрах або інформаційних панелях – як правило, таблиця, яка використовується в багатьох місцях, вважається більш надійною), кількість згадок у внутрішніх повідомленнях на робочому місці, кількість завдань, пов’язаних з нею, тощо.
Вона також може використовуватися для розширеного пошуку, наприклад, для пошуку таблиць, які містять певні стовпці, які призначені певній групі викликів тощо.
iData можна використовувати для пошуку інших типів інформаційних ресурсів на додаток до таблиць (наприклад, інформаційних панелей), а також включає в себе лінійні інструменти для дослідження висхідних і низхідних залежностей будь-якого ресурсу. Це дає змогу швидко визначити, які трубопроводи використовуються для отримання даних для інформаційних панелей високого рівня і які таблиці реєстрації знаходяться вище за течією від них.
Presto та Spark: Запит до складу (warehouse)
До сховища можна звертатися з багатьох різних точок входу, але інженери даних у Meta зазвичай використовують Presto та Spark. Хоча обидва мають відкритий вихідний код (Presto спочатку розроблявся в Meta і був відкритий у 2019 році), Meta використовує і підтримує власні внутрішні форки, але часто відновлює бази з репозиторію з відкритим вихідним кодом, щоб ми були в курсі подій, і додає функції назад у проекти з відкритим вихідним кодом.
Оскільки ми зосереджені в першу чергу на впливи на бізнес, дизайні та оптимізації, більшість наших конвеєрів і запитів написані на мові SQL в одному з двох діалектів (Spark SQL або Presto SQL). Хоча ми також використовуємо API Spark для Java, Scala та Python для створення та управління складними перетвореннями для більшої гнучкості. Такий підхід забезпечує послідовне розуміння даних та бізнес-логіки і дозволяє будь-якому інженеру з даних, науковцю з даних або інженеру-програмісту, який впевнено працює з SQL, розуміти всі наші пайплайни і навіть писати власні запити. Що ще важливіше, розуміння даних та їхнього походження допомагає нам дотримуватися безлічі правил конфіденційності.
Вибір Presto чи Spark здебільшого залежить від робочого навантаження: Presto, як правило, більш ефективний і використовується для більшості запитів, тоді як Spark використовується для великих робочих навантажень, які вимагають більшого обсягу пам’яті або дорогих об’єднань. Кластери Presto мають такий розмір, що більшість щоденних спеціальних запитів (які сканують, як правило, кілька мільярдів рядків, що вважається легким запитом за шкалою Meta) дають результати за кілька секунд (або хвилин, якщо йдеться про складні об’єднання або агрегації).
Scuba: Аналітика в реальному часі
Scuba – це фреймворк для аналізу даних у реальному часі від Meta. Його часто використовують інженери з обробки даних та інженери-програмісти для аналізу тенденцій на даних каротажу в реальному часі. Він також широко використовується для налагодження програмними та виробничими інженерами.
Таблиці Scuba можна запитувати або через веб-інтерфейс Scuba (який можна порівняти з такими інструментами, як Kibana), або через діалект SQL. У веб-інтерфейсі Scuba інженери можуть швидко візуалізувати тенденції в таблиці журналу без необхідності писати запити, використовуючи дані, які були згенеровані за останні кілька хвилин.
Дані, які зберігаються в Scuba, часто надходять безпосередньо з журналів на стороні клієнта або сервера, але Scuba також можна використовувати для запитів до результатів конвеєрів даних, систем обробки потоків в реальному часі або інших систем. Кожне джерело можна налаштувати так, щоб воно зберігало певний відсоток даних у Scuba. Логери зазвичай налаштовані на запис 100% своїх рядків до Hive, але меншого відсотка до Scuba, оскільки отримання і зберігання даних коштує дорожче.
Daiquery & Bento: Блокноти для запитів та аналізу
Daiquery – це один з інструментів, який інженери даних використовують щодня в Meta. Це веб-блокнот, який діє як єдина точка входу для запитів до будь-якого джерела даних: сховища (або через Presto, або через Spark), Scuba та багатьох інших. Він включає в себе інтерфейс блокнота з декількома комірками для запитів, і користувачі можуть швидко запускати і повторювати запити до нашого сховища даних. За замовчуванням результати відображаються у вигляді таблиць, але вбудовані інструменти візуалізації дозволяють створювати багато різних типів графіків.
Daiquery оптимізований для швидкої розробки запитів, але не підтримує більш складний аналіз після виконання запиту. Для цього користувачі можуть просувати свої блокноти Daiquery в блокноти Bento. Bento є внутрішньою реалізацією керованих блокнотів Jupyter від Meta, і на додаток до запитів також дозволяє писати код на python або R (з низкою кастомних ядер для різних сценаріїв використання) та отримувати доступ до широкого спектру бібліотек візуалізації. Окрім інженерів з обробки даних, Bento також широко використовується науковцями з аналізу даних для аналітики та інженерами з машинного навчання для проведення експериментів та управління робочими процесами.
Unidash: Dashboarding
Unidash – це назва внутрішнього інструменту, який інженери даних використовують для створення дашбордів (подібно до Apache Superset або Tableau). Він інтегрується з Daiquery (і багатьма іншими інструментами): наприклад, інженери можуть написати свій запит в Daiquery, створити там свій графік, а потім експортувати його в новий або існуючий дашборд Unidash.
Наші дашборди зазвичай показують високоагреговане представлення основних даних. Запуск запиту для агрегування основних даних при кожному завантаженні дашборду часто є надто дорогим. У багатьох випадках інженери даних можуть обійти цю проблему, написавши конвеєри для попереднього агрегування даних до відповідного рівня для дашборду, але в деяких випадках це неможливо через складність самого дашборду. Щоб допомогти в таких випадках, наша внутрішня реалізація Presto включає розширення під назвою RaptorX, яке кешує часто використовувані дані і може забезпечити до 10-кратного прискорення для критично важливих за часом запитів.
Більшість дашбордів Unidash створюються за допомогою веб-інтерфейсу, що забезпечує швидку ітерацію та інтерактивну розробку. Дашборди Unidash також можна створювати за допомогою API python, що дозволяє легше масштабувати дашборди до більш високих рівнів складності та полегшує перегляд змін у дашборді (за рахунок більш складного початкового налаштування).
Розробка програмного забезпечення
Інженери даних розробляють конвеєри для створення критично важливих наборів даних для прийняття рішень за допомогою таких інструментів, як Daiquery та Unidash, а також пишуть код для визначення конвеєрів даних, взаємодії з внутрішніми системами, створення інструментів для конкретних команд, участі у створенні інструментів інфраструктури даних для всієї компанії тощо.
Більшість інженерів в Meta використовують висококастомізовану версію Visual Studio Code як IDE для роботи над нашими конвеєрами. Вона включає в себе безліч кастомних плагінів, розроблених і підтримуваних внутрішніми командами. Ми використовуємо внутрішній форк Mercurial для контролю вихідного коду (нещодавно відкритий як Sapling), а також структуру, близьку до монорепо – всі конвеєри даних і більшість внутрішніх інструментів Meta знаходяться в одному репозиторії, а визначення логерів і конфігураційні об’єкти – в двох інших репозиторіях.
Написання конвеєрів
Конвеєри даних здебільшого написані на SQL (для бізнес-логіки), обгорнуті в код на Python (для оркестрування та планування).
Бібліотека Python, яку ми використовуємо для оркестрування та планування конвеєрів, має внутрішню назву Dataswarm. Це попередник Airflow, який розробляється і підтримується всередині компанії. Якщо ви хочете дізнатися більше про внутрішню роботу Dataswarm, один з інженерів-програмістів, який працював над Dataswarm, зробив чудову презентацію про нього в 2014 році, яка доступна на YouTube. Хоча з того часу фреймворк еволюціонував, базові принципи, викладені в тій презентації, актуальні й донині.
Pipelines будуються на блоках, які називаються “операторами”. Пайплайн – це орієнтований ациклічний граф (DAG), а кожен оператор – це вузол в DAG.
У Dataswarm доступно багато операторів, їх можна розділити на кілька основних категорій:
- Оператори WaitFor, тип оператора, який чекає, поки щось станеться (як правило, розділ у певній таблиці вищого рівня буде висаджений на склад),
- Оператори запитів, для запуску запиту на движку (зазвичай це Presto або Spark для запитів до сховища),
- Оператори якості даних для виконання автоматизованих перевірок даних, що вставляються в таблицю,
- Оператори передачі даних для передачі даних між системами,
- Різні оператори (наприклад, надсилання електронного листа, пінг когось через чат, виклик API, виконання скрипту…)
Код для визначення простого конвеєра виглядає приблизно так:


Наші внутрішні розширення VSCode обробляють визначення конвеєра при збереженні та обчислюють DAG:
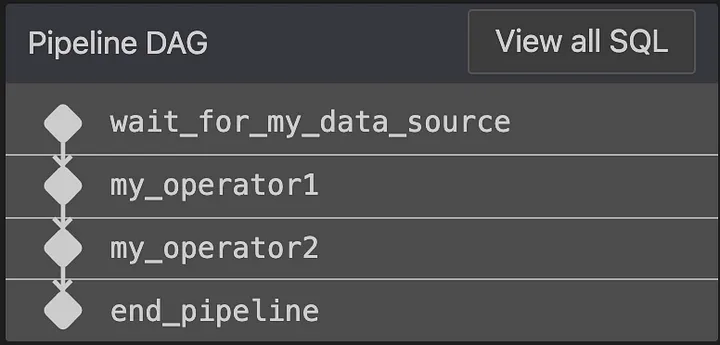
Якщо в якомусь із SQL-запитів є помилка, користувацький лінтер видасть попередження ще до того, як ви спробуєте запустити конвеєр. Ці ж розширення також дозволяють інженерам даних запланувати тестовий запуск нової версії з використанням реальних вхідних даних, записуючи вихідні дані у тимчасову таблицю.
UPM: Розширені функції конвеєра
Якщо ви перечитаєте код вище, ви можете помітити деякі надмірності. У цьому прикладі в першому операторі ми просимо фреймворк дочекатися сьогоднішнього розділу для my_data_source, а в другому операторі ми просимо фреймворк дочекатися my_operator1, тому що нам потрібно, щоб розділ існував в my_staging_table. Але про це можна здогадатися, просто подивившись на SQL-запит: WHERE ds=” означає, що ми залежимо від розділу для цієї таблиці. І, як інженери, ми не любимо повторюватися.
Команда інженерів з Meta вирішила цю проблему і створила фреймворк під назвою Unified Programming Model (UPM), який робить саме це: при використанні в конвеєрі Dataswarm він розбирає SQL-запити в операторах і правильно визначає, на які розділи потрібно чекати кожному оператору. (Зауважте, що це лише одна з можливостей UPM, яка буде більш детально розглянута в серії постів “Майбутнє інженерії даних“). Використовуючи UPM, всі “WaitFor” і залежності можуть бути виведені автоматично. Після цього код конвеєра може бути зведений до його основної бізнес-логіки:

Загалом, інженер з обробки даних, який пише конвеєр, перевірить правильність залежностей, виведених UPM, переглянувши згенеровану DAG.
Бібліотеки аналітики
Окрім спрощення розробки пайплайнів, UPM та інші аналітичні бібліотеки також використовуються для створення певних типів складних пайплайнів (наприклад, для обліку зростання або утримання), які складно створювати вручну. Ці бібліотеки створюють конвеєри за загальними шаблонами з використанням налаштувань, наданих користувачем.
Одним з простих прикладів є створення таблиці в стилі дайджесту (про що ми детально поговоримо в одній з наступних публікацій блогу).

Це створює таблицю з тривимірними стовпчиками (продукт, країна і has_log_session) і двома агрегованими метричними стовпчиками, total_session_time_minutes і total_distinct_users_hll. Останній стовпчик використовує тип HyperLogLog у Presto, який використовується для приблизного підрахунку.
Моніторинг та операції
Моніторинг пайаплайну здійснюється за допомогою веб-інструменту під назвою CDM (Central Data Manager), який можна розглядати як інтерфейс Dataswarm.
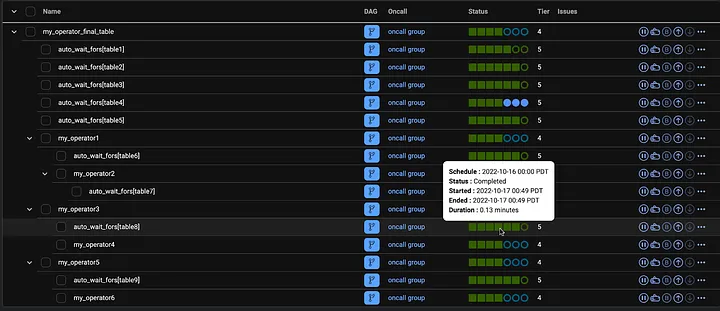
Це подання схоже на деревоподібне подання Airflow, але воно є точкою входу до ширшого інструменту, який дозволяє нам це робити:
- Швидко визначайте невдалі завдання та знаходьте відповідні журнали
- Визначте та виконайте зворотну засипку
- Перехід до висхідних залежностей (наприклад, для waitfor він перейде до конвеєра, який згенерував висхідну таблицю, на яку ми очікуємо)
- Виявлення блокувальників на висхідному потоці (CDM пройде через рекурсивні залежності на висхідному потоці і автоматично знайде першопричину застрягання трубопроводу)
- Увімкніть сповіщення та ескалацію, якщо розділи не висаджуються відповідно до налаштованого SLA
- Налаштуйте та контролюйте перевірку якості даних
- Відстежуйте польотні завдання та історичні показники
Висновок
У цій статті наведено огляд інструментів і систем, які найчастіше використовують інженери даних, але в різних компаніях вони дуже різняться. Деякі інженери даних зосереджуються переважно на розробці конвеєрів та створенні дашбордів, а інші – на веденні журналів, розробці нових аналітичних інструментів або повністю зосереджуються на управлінні робочими навантаженнями ML.
Ця стаття не включає кілька важливих інструментів і систем, які заслуговують на більш детальний розгляд і будуть висвітлені в наступних публікаціях блогу:
- Інструменти для управління метриками та експериментами
- Наша експериментальна платформа для тестування
- Інструменти для управління експериментами та розгортанням
- Інструменти конфіденційності
- Спеціалізовані інструменти для управління робочими навантаженнями з ВК
- Оперативний інструментарій для розуміння метричних рухів
Наше сховище даних і системи зростали і змінювалися відповідно до потреб компанії, а тому постійно розвиваються, щоб задовольняти нові потреби. Ми постійно працюємо над розширенням нашої інфраструктури з урахуванням конфіденційності, зменшенням вартості запитів і обсягу даних, які ми зберігаємо, а також над тим, щоб полегшити інженерам з обробки даних роботу з великими наборами конвеєрів. Загалом ці зміни допомагають зменшити кількість повторюваної роботи, яку виконують інженери даних, що дозволяє їм витрачати більше часу на потреби продукту.
Автор: Алекс М.
ОРИГІНАЛ СТАТТІ:Data engineering at Meta: High-Level Overview of the internal tech stack
АВТОР СТАТІ:Analytics at Meta
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X: