В епоху зростаючої складності даних і багатовимірної інформації традиційні бази даних часто не справляються з ефективною обробкою та витяганням сенсу зі складних наборів даних. Увійдіть до векторних баз даних – технологічної інновації, яка з’явилася як відповідь на виклики, пов’язані з постійно зростаючим ландшафтом даних.
Розуміння векторних баз даних
Векторні бази даних здобули значний розголос у різних галузях завдяки їх унікальній здатності ефективно зберігати, індексувати та шукати високо-вимірні дані, часто називані векторами. Ці бази даних призначені для роботи з даними, де кожен запис представлений у вигляді вектора у багатовимірному просторі. Вектори можуть відображати широкий спектр інформації, такий як числові ознаки, вкладення тексту чи зображень, а також складні дані, такі як молекулярні структури.
Давайте представимо векторну базу даних за допомогою двовимірної сітки, де одна вісь відображає колір тварини (коричневий, чорний, білий), а інша вісь відображає розмір (малий, середній, великий).
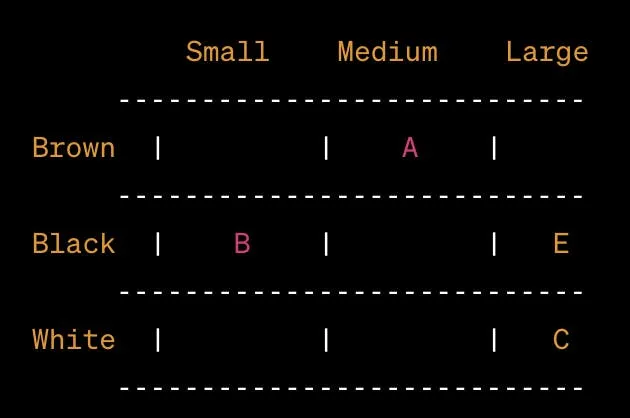
У цьому представленні:
- Зображення A: коричневий колір, середній розмір
- Зображення B: чорний колір, малий розмір
- Зображення C: білий колір, великий розмір
- Зображення E: Чорний колір, великий розмір
Ви можете уявити кожне зображення як точку, розташовану на цій сітці на основі її атрибутів кольору та розміру. Ця спрощена сітка передає сутність того, як може бути візуально представлена векторна база даних, навіть якщо фактичні векторні простори можуть мати набагато більше вимірів і використовувати складні техніки для пошуку та вилучення даних.
Пояснення Векторних Баз Даних для п’ятирічних
Уявіть, що у вас є купа різних фруктів, таких як яблука, апельсини, банани та виноград. Ви любите смак яблук і хочете знайти інші фрукти, які смакують схоже на яблука. Замість того, щоб сортувати фрукти за їх кольорами або розмірами, ви вирішуєте групувати їх за тим, наскільки вони солодкі або кислі.

Отже, ви збираєте всі солодкі фрукти разом, такі як яблука, виноград та дозрілі банани. Кислі фрукти ви класифікуєте в іншу групу, наприклад, апельсини та недозрілі банани. Тепер, коли вам потрібно знайти фрукти, які смакують, як яблука, ви просто дивитеся в групі солодких фруктів, оскільки вони більш ймовірно мають схожий смак.
Але, якщо вам потрібно знайти щось конкретне, наприклад, фрукт, який так само солодкий, як яблуко, але має також кислий смак, як апельсин? Його може бути трохи важко знайти ваших групах, чи не так? Тоді ви запитуєте когось, хто добре розуміє різні фрукти, наприклад, експерта з фруктів. Вони можуть запропонувати фрукт, що відповідає вашому унікальному запиту на смак, оскільки вони знають про смаки багатьох фруктів.
У цьому випадку ця освічена людина діє як “векторна база даних”. Вони мають багато інформації про різні фрукти і можуть допомогти вам знайти той, який підходить вашому спеціальному смаку, навіть якщо це не базується на звичайних речах, таких як кольори або форми.
Так само, векторна база даних схожа на цього корисного експерта для комп’ютерів. Вона призначена для запам’ятовування багатьох деталей про різні речі, наприклад, їжу, у спеціальний спосіб. Таким чином, якщо ви шукаєте їжу, смак якої схожий на те, що ви любите, або їжу з комбінацією смаків, які вам подобаються, ця векторна база даних може швидко знайти для вас правильні варіанти. Це схоже на наявність експерта зі смаком для комп’ютерів, який все знає про смаки і може запропонувати чудові варіанти на основі того, що ви прагнете, саме як та освічена людина з фруктами.
Як векторні бази даних зберігають дані?
Векторні бази даних зберігають дані за допомогою векторних вкладень. Векторні вкладення у векторних базах даних вказують на спосіб представлення об’єктів, таких як елементи, документи або точки даних, у вигляді векторів у багатовимірному просторі. Кожному об’єкту призначається вектор, який зафіксовує різні характеристики або особливості цього об’єкта. Ці вектори розроблені таким чином, що подібні об’єкти мають вектори, які знаходяться ближче один до одного у векторному просторі, тоді як різні об’єкти мають вектори, які знаходяться далеко один від одного.
Подумайте про векторні вставки як про спеціальний код, що описує важливі аспекти об’єкта. Уявіть, що у вас є різні тварини, і ви хочете представити їх таким чином, щоб схожі тварини мали схожі коди. Наприклад, коти і собаки можуть мати досить близькі коди, оскільки вони мають спільні риси, такі як чотириногість і шерсть. З іншого боку, такі тварини, як риби та птахи, матимуть коди, які значно відрізняються один від одного, що відображає їхні відмінності.
У векторній базі даних ці вкладення використовуються для зберігання та організації об’єктів. Коли ви хочете знайти об’єкти, які схожі на заданий запит, база даних дивиться на вкладення і обчислює відстані між вкладенням запиту та вкладеннями інших об’єктів. Це допомагає базі даних швидко визначити об’єкти, найбільш подібні до запиту.
Наприклад, у додатку для стрімінгу музики пісні можуть бути представлені у вигляді векторів за допомогою вкладень, які відображають музичні характеристики, такі як темп, жанр та використані інструменти. Коли ви шукаєте пісні, схожі на вашу улюблену композицію, векторна база даних додатка порівнює вкладення, щоб знайти пісні, які найбільш відповідають вашим уподобанням.
Вкладення векторів – це спосіб перетворення складних об’єктів у числові вектори, які відображають їх характеристики, і векторні бази даних використовують ці вкладення для ефективного пошуку та вибору схожих або відповідних об’єктів на основі їхнього положення у векторному просторі.
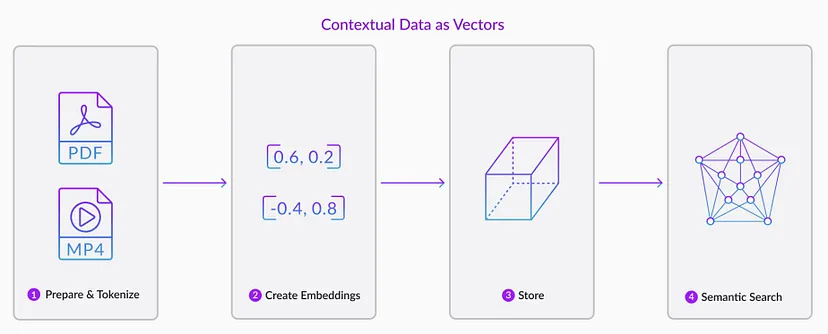
Як працюють векторні бази даних?
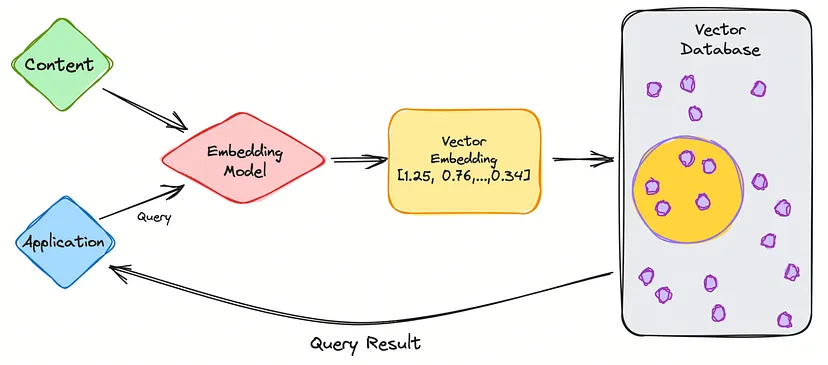
Зображення: KDnuggets
Користувацький запит:
- Ви вводите запитання або запит до програми ChatGPT.
Створення векторних вкладень:
- Додаток перетворює ваш ввід в компактну числову форму, яку називають векторним вкладенням.
- Це вкладення захоплює суть вашого запиту в математичному відображенні.
Порівняння з базою даних:
- Векторне вкладення порівнюється з іншими вкладеннями, збереженими в базі даних.
- Міри схожості допомагають виявити найближчі вкладення за змістом.
Формування відповіді:
- База даних генерує відповідь, складену з вкладень, що найбільше відповідають змісту вашого запиту.
Відповідь користувача:
- Відповідь, що містить відповідну інформацію, пов’язану з визначеними вкладеннями, надсилається вам.
Післязапити:
- Коли ви робите наступні запити, модель вкладень генерує нові вкладення.
- Ці нові вкладення використовуються для пошуку схожих вкладень у базі даних, пов’язуючись з вихідним вмістом.
Як векторні бази даних визначають, які вектори схожі?
Векторна база даних визначає схожість між векторами за допомогою різних математичних технік, однією з найпоширеніших методів є косинусна схожість.
Коли ви шукаєте “Найкращий крикетний гравець у світі” у Google і він показує список найкращих гравців, існує кілька кроків, одним з головних з яких є косинусна схожість.
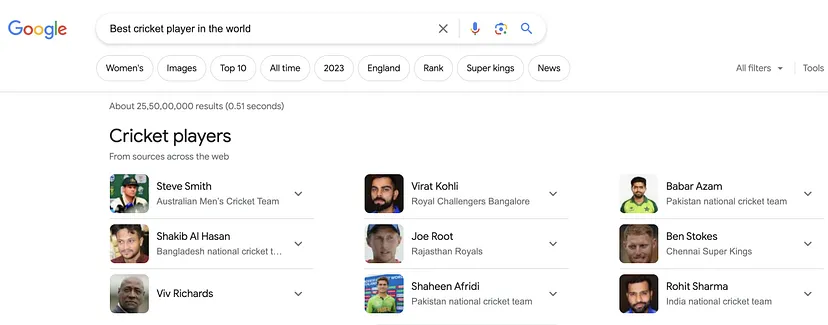
Векторне представлення пошукового запиту порівнюється з векторними представленнями всіх профілів гравців у базі даних за допомогою косинусної схожості. Чим більше схожі вектори, тим вищий показник косинусної схожості.
Примітка: Це лише для прикладу. Важливо зазначити, що пошукові системи, такі як Google, використовують складні алгоритми, які виходять за межі простої схожості векторів. Вони враховують різні фактори, такі як місце розташування користувача, історія пошуку, авторитет джерел і багато інших, щоб забезпечити найбільш відповідні та персоналізовані результати пошуку.
Можливості векторних баз даних
Значення векторних баз даних полягає у їх можливостях та застосуваннях:
-Ефективний пошук схожості:
Векторні бази даних відмінно справляються з виконанням пошуку схожості, де можна отримати вектори, які найбільше схожі з заданим запитом. Це важливо у різних застосунках, таких як системи рекомендацій (пошук схожих товарів або контенту), пошук зображень і відео, розпізнавання обличчя та інформаційний пошук.
-Високорозмірні дані:
Традиційні реляційні бази даних мають проблеми з високорозмірними даними через “прокляття розмірності”, коли відстані між точками даних стають менш значущими при збільшенні кількості розмірностей. Векторні бази даних призначені для більш ефективної роботи з високорозмірними даними, що робить їх підходящими для застосувань у обробці природної мови, комп’ютерного зору та геноміці.
-Машинне навчання та штучний інтелект:
Часто векторні бази даних використовуються для зберігання вкладень, створених моделями машинного навчання. Ці вкладення захоплюють основні ознаки даних і можуть бути використані для різних завдань, таких як кластеризація, класифікація та виявлення аномалій.
-Реальночасові застосунки:
Багато векторних баз даних оптимізовані для запитів у реальному часі або майже в реальному часі, що робить їх підходящими для застосувань, які вимагають швидких відповідей, таких як системи рекомендацій в електронній комерції, виявлення шахрайства та моніторинг даних датчиків Інтернету речей.
-Персоналізація та профілювання користувачів:
Векторні бази даних дозволяють персоналізований досвід, дозволяючи системам розуміти та передбачати вподобання користувачів. Це важливо в платформах, таких як стрімінгові сервіси, соціальні мережі та онлайн-магазини.
-Просторові та географічні дані:
Векторні бази даних можуть ефективно обробляти географічні дані, такі як точки, лінії та полігони. Це важливо в застосунках, таких як геоінформаційні системи (ГІС), сервіси на основі місцезнаходження та навігаційні додатки.
-Охорона здоров’я та науки про життя:
У геноміці та молекулярній біології векторні бази даних використовуються для зберігання та аналізу генетичних послідовностей, структур білків та інших молекулярних даних. Це допомагає у відкритті ліків, діагностиці захворювань та персоналізованій медицині.
-Фузія та інтеграція даних:
Векторні бази даних можуть інтегрувати дані з різних джерел та типів, що дозволяє проводити більш всебічний аналіз та отримувати інсайти. Це цінно в сценаріях, де дані походять з різних модальностей, наприклад, комбінуючи текстові, зображення та числові дані.
-Багатомовний пошук:
Векторні бази даних можна використовувати для створення потужних багатомовних пошукових систем, представляючи текстові документи як вектори в спільному просторі, що дозволяє здійснювати пошук за схожістю між мовами.
-Дані графіків:
Векторні бази даних можуть ефективно представляти та обробляти графові дані, що є важливим в аналізі соціальних мереж, системах рекомендацій та виявленні шахрайства.
Вирішальна роль векторних баз даних у сучасному ландшафті даних
Векторні бази даних зазнають великого попиту через їх вирішальну роль у вирішенні викликів, які виникають внаслідок вибуху високо-вимірних даних у сучасних застосунках.
З поширенням технологій штучного інтелекту, машинного навчання та аналізу даних, пріоритетною стала необхідність ефективно зберігати, шукати та аналізувати складні представлення даних. Векторні бази даних дозволяють підприємствам використовувати потужність пошуку схожості, персоналізованих рекомендацій та відновлення вмісту, що сприяє покращенню користувацьких вражень та прийняття кращих рішень.
Застосування векторних баз даних охоплює широкий спектр галузей, від електронної комерції та платформ контенту до охорони здоров’я та автономних транспортних засобів. Попит на векторні бази даних виникає з їх здатності обробляти різноманітні типи даних і надавати точні результати в реальному часі. З ростом обсягу та складності даних, масштабованість, швидкість та точність, які пропонують векторні бази даних, роблять їх критичним інструментом для отримання значущих інсайтів та відкриття нових можливостей у різних галузях.
SingleStore як векторна база даних:
Використовуйте потужні можливості векторної бази даних SingleStoreDB, призначеної для безпроблемного обслуговування застосунків, що працюють на основі штучного інтелекту, чат-ботів, систем розпізнавання зображень та іншого. З SingleStoreDB в вашому розпорядженні, необхідність у веденні окремої векторної бази даних для ваших завдань, що вимагають інтенсивного використання векторів, стає зайвою.
Відхиляючись від традиційних підходів до векторних баз даних, SingleStoreDB використовує новаторський підхід, розміщуючи векторні дані в межах реляційних таблиць поряд із різноманітними типами даних. Це новаторське поєднання дозволяє вам легко отримувати доступ до всієї метаданих та додаткових атрибутів, що стосуються вашої векторної інформації, причому ви використовуєте всю потужність запитів мовою SQL.
SingleStoreDB була створена з урахуванням масштабованої структури, що гарантує непохитну підтримку ваших зростаючих потреб у данних. Попрощайтеся з обмеженнями і вітаєте рішення, що розвивається разом з вашими потребами у данних.
Приклад зіставлення облич з використанням SQL у SingleStore
Ми завантажили 16 784 377 рядків у цю таблицю.
create table people(
id bigint not null primary key,
filename varchar(255),
vector blob
);Кожен рядок представляє одне зображення знаменитості і містить унікальний номер ідентифікатора, ім’я файлу, де зберігається зображення, та вектор з 128-ма елементами з плаваючою комою, що представляє сенс обличчя. Цей вектор був отриманий за допомогою facenet, попередньо навченої нейронної мережі для створення векторних вкладень зображення обличчя.
Не хвилюйтеся, вам не потрібно розуміти штучний інтелект, щоб використовувати такий підхід – вам просто потрібно використовувати готову навчену нейронну мережу іншої людини або будь-який інструмент, який може надавати вам вектори-конспекти для об’єкта.
Тепер ми запитуємо цю таблицю за допомогою:
select vector
into @v
from people
where filename = "Emma_Thompson/Emma_Thompson_0001.jpg";
select filename, dot_product(vector, @v) as score
from people where score > 0.1
order by score desc
limit 5;Перший запит отримує вектор запиту @v для зображення Emma_Thompson_0001.jpg. Другий запит знаходить п’ять найближчих відповідників:
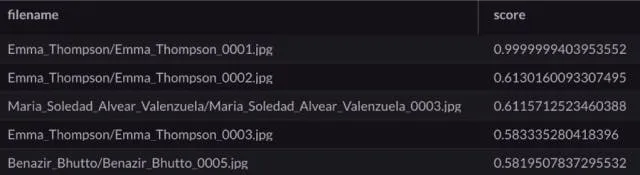
Emma_Thompson_0001.jpg – ідеально підходить для самого себе, тому рівень близькості майже 1. Але цікаво, що наступний найближчий варіант – Emma_Thompson_0002.jpg. Ось запитове зображення та найближчий варіант:

Більше того, швидкість пошуку, яку ми отримали, була справді неймовірною. Другий запит зайняв лише 0,005 секунд на машині з 16 vcpu. І обробив всі 16 мільйонів векторів. Це швидкість понад 3,3 мільярди збігів векторів за секунду.
Дізнайтеся більше про цей експеримент у вихідній статті. Порівняння зображень в SQL за допомогою SingleStoreDB
Тепер настав час самостійно спробувати SingleStore.
Зареєструйтеся у SingleStore та отримайте $600 безкоштовного використання.
Значення векторних баз даних полягає в їхній здатності опрацьовувати складні, високорозмірні дані, пропонуючи ефективні механізми запитування та вибірки. З ростом складності та обсягу даних векторні бази даних стають все більш важливими в різноманітних застосуваннях у різних галузях промисловості.
Примітка та відмова від відповідальності: Я скористався допомогою ChatGPT у написанні деяких частин цієї статті.
Стаття оригінально опублікована на dev.to.
ОРИГІНАЛ СТАТТІ:Vector Databases: A Beginner’s Guide!
АВТОР СТАТІ:Pavan Belagatti
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:


