При проектуванні сховища даних ми часто стикаємося з ситуацією, коли у вихідній системі є поля з індикаторами “так/ні”. Завдяки бізнес-аналізу ми знаємо, що таку інформацію необхідно зберігати в таблиці фактів. Однак, якщо зберігати всі ці поля індикаторів у таблиці фактів, нам не тільки потрібно побудувати багато таблиць невеликої розмірності, але й обсяг інформації, що зберігається в таблиці фактів, також значно збільшується, що призводить до можливих проблем з продуктивністю та управлінням.
Вимір сміття – це спосіб вирішити цю проблему. У небажаному вимірі ми об’єднуємо ці поля індикаторів в один вимір. Таким чином, нам потрібно буде побудувати лише одномірну таблицю, а кількість полів у таблиці фактів, а також розмір таблиці фактів можна буде зменшити. Вміст таблиці розмірності “сміття” – це комбінація всіх можливих значень окремих полів індикатора.
Розглянемо приклад. Припустимо, що у нас є наступна таблиця фактів:

У цьому прикладі TXN_CODE, COUPON_IND і PREPAY_IND є полями індикатора. У цьому існуючому форматі кожне з них є виміром. Використовуючи принцип вимірності сміття, ми можемо об’єднати їх в один вимір сміття, в результаті чого отримаємо наступну таблицю фактів:

Зверніть увагу, що тепер кількість вимірів у таблиці фактів зменшилася з 7 до 5.
Вміст таблиці розмірностей сміття буде виглядати наступним чином:
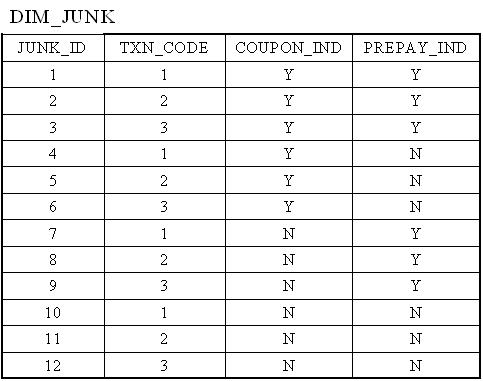
У цьому випадку ми маємо 3 можливих значення для поля TXN_CODE, 2 можливих значення для поля COUPON_IND і 2 можливих значення для поля PREPAY_IND. Це дає нам загалом 3 x 2 x 2 = 12 рядків для таблиці розмірності сміття.
Використовуючи розмірність сміття для заміни 3 полів індикаторів, ми зменшили кількість вимірів на 2, а також зменшили кількість полів у таблиці фактів на 2. Це призведе до створення середовища зберігання даних, яке забезпечить кращу продуктивність, а також буде простішим в управлінні.


