
Так як у нас в спільності з’явилось багато запитань, а як вже все таки працює База Даних (Data Base). Вирішив написани невеличку величку статтю, котра зможе надати відповіді на основні запитання, а саме:
- Чому деякі люди назвають SQL (ес к’ю ель), а деякі SEQUEL (сіквел)
- Що таке оптимізатор (Query Optimization Engine)
- Яка послідовність виконання запиту
Це статття не дасть вам надалі сперечатись з Адміністраторами DB, але ви зможете розуміти як жеш цей магічний тубус працює, погнали…
SQL/SEQUEL
Завжди цікавило це питання, чому деякі дядьки кажуть “сіквел”, а деяка молодежь “ес к’ю ель”, а от і відповідь, достатньо подивитись у вікіпедії коли був створений SQL, але краще дивитись в англ версії
History
SQL спочатку був розроблений в IBM Дональдом Д. Чемберліном та Реймондом Ф. Бойсом після вивчення реляційної моделі від Едгара Ф. Кодда[12] на початку 1970-х років.[13] Ця версія спочатку називалася SEQUEL (Structured English QUEry Language) і була призначена для маніпулювання та витягування даних, збережених в першій квазіреляційній системі управління базами даних IBM, System R, яку група в IBM San Jose Research Laboratory розробляла протягом 1970-х років.[13]
Перший спроба Чемберліна та Бойса створити мову для реляційної бази даних була SQUARE (Specifying Queries in A Relational Environment), але її було важко використовувати через нотацію з верхнім і нижнім індексами. Після переходу до San Jose Research Laboratory в 1973 році вони почали працювати над продовженням SQUARE.[12] Початкова назва SEQUEL, яку часто розглядають як гумористичну гру з QUEL, мови запитів Ingres,[14] потім була змінена на SQL (вилучивши голосні), оскільки “SEQUEL” була торговою маркою компанії Hawker Siddeley Dynamics Engineering Limited із Великої Британії.[15] Позначка SQL пізніше стала абревіатурою для Structured Query Language.
Тобто, хлопці з IBM зробили таке скоречення котре вже було зареєстроване як торгова марка у іншій компанії, тому прийшлось зробити зі скорочення, ще скоречення 🤡.
Але за цей час вже були опубліковані книги, статті для роботи з БД де писалось “SEQUEL” – сіквел, тому люди, котрі трошки постарше називають SQL як “сіквел”. Я звик казати SQL, але кожен з нас може називати як йому подобається, головне щоб було зрозуміло про що йдеться мова.
Тепер перейдемо, трошки, до практичної частини.
Послідовність виконання запиту SQL
Перші знайомства з DB це завжди дуже дивні відчуття, ніби хочеться і спати і тацювати водночас.
Будемо розглядати на прикладі отакої таблички
Отака вона в DB:
(
sale_id INT PRIMARY KEY
, shop_id INT
, goods_name VARCHAR(100)
, quantity INT
, sale_date DATE
, total_price INT
);
Проста таблиця, в котрій зберігаються дані про продажі товарів в розрізі магазинів, а ось так виглядають дані в Excel (куди ж без нього):
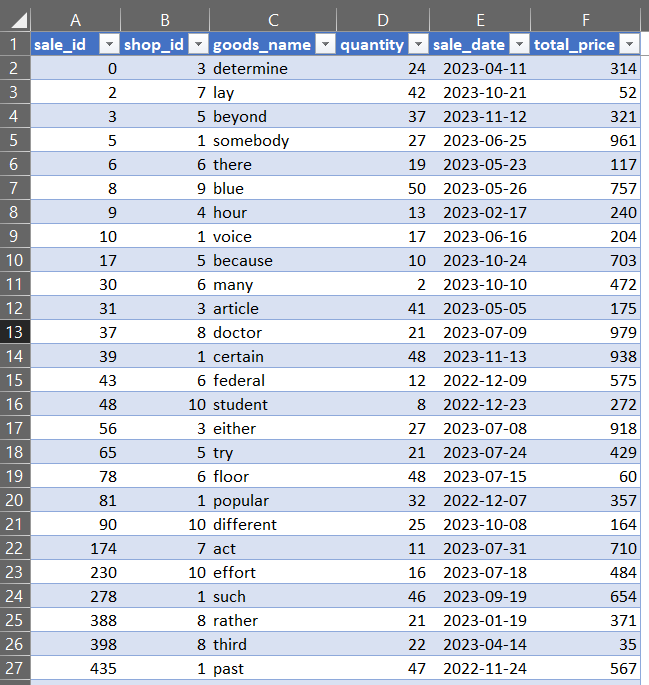
Коли в нас є розуміння з чим ми будемо працювати, давайте спробуємо зробити запит до цієї таблиці:
FROM sales_tbl
WHERE shop_id = 10;
Таким запитом ми отримаємо всі строку по магазину №10, а шо в цей час робить БД?! )
- Розпізнавання SQL-запиту:
- База даних розпізнає, що це SQL-запит SELECT, який вибирає всі стовпці (*) з таблиці
sales_tbl, де значенняshop_idдорівнює 10. Тобто у самої БД є умовний “компілятор”, котрий дивиться, не написали чи ми якоїсь фігні (перевірка синтаксису), якщо шось не так, нам може відобразитись помилка.
- База даних розпізнає, що це SQL-запит SELECT, який вибирає всі стовпці (*) з таблиці
- Оптимізація запиту (Query Optimization):
- Оптимізатор запиту аналізує запит та розробляє стратегію виконання. У кожній БД є своя технологія алгоритмів як вони мають виконувати той чи інший запит. Якщо дуже поверхнесно, оптимізатор дивиться на дві речі (взагалі їх набагато більше):
- Журнал статистики – це умовна таблиця в БД, котра зберігає інформацію про дії з об’єктами БД, тобто якщо виконувати один і той самий запит декілька разів, з кожним разом цей запит буде виконуватись швидше і швидше, поки не дійде до максимально можливого варіанту.
- Індекси – уявіть шо це позначки/знаки для оптимізатора БД, наприклад коли ви знаходитесь в магазині і телефонуєте мамі/дружині “а де знаходиться червоне шардоне котре ти п’єш”, то мама/дружина тобі скаже точне місце куди йти і де його взяти. В цьому випадку без будь-яких перешкод прямуєте до конкретної точки не звертаючи увагу на інші товари і берете те що вам або дружині/мамі потрібно, так і тут індекс допомогає БД знайти швидко це “вино”.
- Оптимізатор запиту аналізує запит та розробляє стратегію виконання. У кожній БД є своя технологія алгоритмів як вони мають виконувати той чи інший запит. Якщо дуже поверхнесно, оптимізатор дивиться на дві речі (взагалі їх набагато більше):
- Виконання запиту (Query Execution):
- Система БД, а саме інтерпретор починає виконувати фактичний запит.
- Пошук в базі даних (Table Scan або Index Scan):
- Під час виконання запиту, саме в цей час оптимізатор обирає як він буде шукати рядки, котрі потрібно вам повернути, це може бути два основних варіанти:
- Full Scan – це коли таблиця перевіряється, тобто якщо на наш приклад перевести, ви не змогли зателефонувати до мами/дружини і ви обшукуєте весь магазин в пошуках цього клятого вина.
- Index Scan – тут випадок коли ви всетаки дозвонились до мами/дружини…
- Під час виконання запиту, саме в цей час оптимізатор обирає як він буде шукати рядки, котрі потрібно вам повернути, це може бути два основних варіанти:
- Вибірка рядків:
- Коли інтерпретатор вирішив, яким чином він буде шукати для вас ці рядки, система вибирає рядки з таблиці, які відповідають умові
shop_id = 10.
- Коли інтерпретатор вирішив, яким чином він буде шукати для вас ці рядки, система вибирає рядки з таблиці, які відповідають умові
- Повернення результатів (Fetching):
- Після всіх етапів вам повертаються дані, котрі відповідють вашому запиту.
А здавалось, шо все так просто, але є нюанси … Так як, такі запити дуже рідко використовується для аналітиків/DE/DA то додамо ще агрегацію (Group by), відбір на рівні агрегації (Having), агреговану функцію (SUM) і шоб було остаточно весело (LIMIT). Оце зараз буде рвань…Погнали:
Дістанемо інформацію про магазини, котрі за весь час продали меньше ніж на 1000 і при товарах у котрих ціна була меньша 500 + відобразимо ТОП 3 найгірших.
SELECT shop_id,Sum(quantity * total_price) total_sales
FROM sales_tbl
WHERE total_price < 500
GROUP BY shop_id
HAVING Sum(quantity * total_price) > 20000
ORDER BY 2
LIMIT 3
В цілому запит виглядає не страшно, спробуємо розкласти в якій послідовності виконується запит
Від попереднього приклади виконується послідовність від 1-4 пункту включно, а далі:
- FROM sales_tbl: Запит починається з вказання таблиці, з якої потрібно вибрати дані. У цьому випадку таблиця називається
sales_tbl.
Тут уявіть, що БД собі уявила всю таблицю… - WHERE total_price < 500: Здійснюється фільтрація даних за умовою. Вибираються лише рядки, де значення поля
total_priceменше 500.
Тут, вже БД тримає таблицю, в котрій значення відповідні - GROUP BY shop_id: Далі дані групуються за полем
shop_id. Це означає, що будуть враховуватися тільки унікальні значенняshop_id, і вони будуть розглядатися як окремі групи. - SELECT shop_id, SUM(quantity * total_price) AS total_sales: Вибираються два поля:
shop_idта сума значень, отриманих шляхом перемноження полівquantityіtotal_priceдля кожної групи. Це значення позначається якtotal_sales.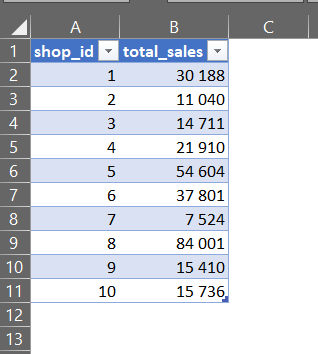
- HAVING SUM(quantity * total_price) > 20000: Після групування використовується
HAVINGдля фільтрації груп. У цьому випадку вибираються лише ті групи, де сумаquantity * total_priceбільше 20000.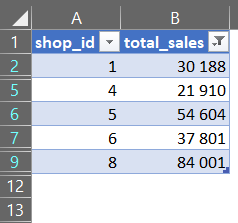
- ORDER BY 2: Результати сортуються за другим вибраним полем, тобто за
total_sales. Це важливо, оскільки ім’яtotal_salesбуло визначено в SELECT як друге поле.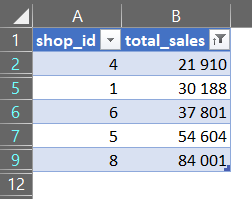
- LIMIT 3: Наостанок, вибираються тільки перші три рядки результату, обмежуючи кількість виведених записів.
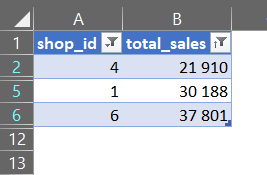
Вам має бути зрозуміло, шо вся ця схема описана поверхносно і схематично, виключно для загального розуміння. В реаліях авжеш потрібно використовувати EXPLAIN – це один з методів для виводу плану виконання запиту і та людина котра його розуміє, зможе писати швидкі запити!
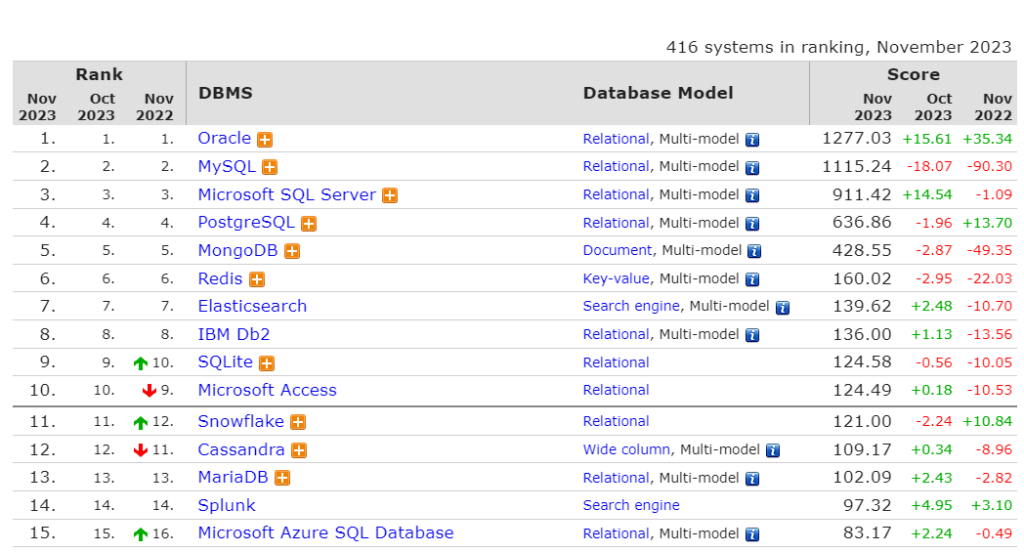
І ось на додачу, сайт в котрому аналізуються БД, та робляться ранги які БД швидші або частіше використовуються https://db-engines.com/en/ranking
Дякую за вашу увагу!
АВТОР СТАТІ: Чернін Олександр (Data Engineer)
Долучайтесь до нашої спільноти Telegram
* Data Life UA
* Data Analysis UA
* DATA ENGINEERING UA
Долучайтесь до нашої спільноти FaceBook
* Data-Life-UA


