(Створено за допомогою Dall-E3)
Великі мовні моделі (LLMs Large Language Model) швидко стають наріжним каменем сучасного ШІ. Проте не існує усталених найкращих практик, і часто першопрохідці залишаються без чіткої дорожньої карти, змушені вигадувати велосипед або застрягають на місці.
Протягом останніх двох років я допомагав організаціям залучати магістрів права для створення інноваційних додатків. Завдяки цьому досвіду я розробив перевірений у боях метод створення інноваційних рішень (заснований на ідеях спільноти LLM.org.il), яким я поділюся в цій статті.
Цей посібник надає чітку дорожнe карту для навігації в складному ландшафті розробки на рівні LLM. Ви дізнаєтеся, як перейти від ідеї до експериментів, оцінки та створення продукту, розкриваючи свій потенціал для створення революційних додатків.
Чому стандартизований процес є важливим
Простір LLM настільки динамічний, що іноді ми чуємо про нові революційні інновації день за днем. Це дуже захоплююче, але й дуже хаотично – ви можете загубитися в цьому процесі, не знаючи, що робити або як втілити свою нову ідею в життя.
Коротше кажучи, якщо ви інноватор у галузі штучного інтелекту (менеджер або практик), який хоче ефективно створювати додатки на рівні LLM, то цей курс для вас.
Впровадження стандартизованого процесу допомагає розпочати нові проекти та пропонує кілька ключових переваг:
- Стандартизація процесу – Стандартизований процес допомагає узгодити дії членів команди та забезпечує безперешкодний процес адаптації нових членів (особливо в умовах хаосу).
- Визначає чіткі етапи – простий спосіб відстежувати свою роботу, вимірювати її та переконуватися, що ви на правильному шляху
- Визначте точки прийняття рішень – розробка на рівні LLM сповнена невідомих і “невеликих експериментів” [див. нижче]. Чіткі точки прийняття рішень дозволяють легко зменшити ризик і завжди залишатися економними в процесі розробки.
Основні навички інженера з дипломом магістра
На відміну від будь-якої іншої усталеної ролі в дослідженні та розробці програмного забезпечення, розробка на рівні LLM абсолютно вимагає нової ролі: інженера LLM або інженера зі штучного інтелекту (ШІ).
LLM-інженер – це унікальна гібридна істота, яка поєднує в собі навички різних (усталених) ролей:
- Навички програмної інженерії – як і в більшості SWE (Software Engineer), більша частина роботи полягає у складанні деталей Lego та склеюванні їх докупи.
- Дослідницькі навички (Research skills) – правильне розуміння експериментальної природи, притаманної LLM, є дуже важливим. Хоча створення “крутих демонстраційних додатків” є досить доступним, відстань між “крутою демонстрацією” і практичним рішенням вимагає експериментів і спритності.
- Глибоке розуміння бізнесу/продукту – через крихкість моделей важливо розуміти бізнес-цілі та процедури, а не дотримуватися визначеної нами архітектури. Здатність моделювати ручні процеси є золотою навичкою для інженерів LLM.
На момент написання цієї статті інженерна програма LLM все ще є зовсім новою, і найм на роботу може бути дуже складним завданням. Краще шукати кандидатів з досвідом роботи в бекенд/інженерії даних або науці про дані.
Інженери-програмісти можуть розраховувати на більш плавний перехід, оскільки процес експериментування є більш “інженерним”, а не “науковим” (порівняно з традиційною роботою в галузі науки про дані). Тим не менш, я бачив, як багато Data Scientists також здійснюють цей перехід. Якщо ви згодні з тим, що вам доведеться опанувати нові м’які навички (soft skills), ви на правильному шляху!
Ключові елементи розвитку LLM на національному рівні
На відміну від класичних бекенд-додатків (таких як CRUD), тут немає покрокових рецептів. Як і все інше в “штучному інтелекті”, LLM-додатки вимагають дослідницького та експериментального мислення.
Щоб приручити звіра, ви повинні розділити і перемогти, розбивши свою роботу на менші експерименти, спробувавши деякі з них і вибравши найперспективніший.
Неможливо переоцінити важливість дослідницького мислення. Це означає, що ви можете витратити час на вивчення вектору дослідження і виявити, що це “неможливо”, “недостатньо добре” або “не варто”. Це абсолютно нормально – це означає, що ви на правильному шляху.

Прийняття експерименту: Серце процесу
Іноді ваш “експеримент” зазнає невдачі, тоді ви трохи змінюєте напрямок своєї роботи, і цей інший експеримент вдається набагато краще.
Саме тому, перед тим як розробляти наше кінцеве рішення, ми повинні почати з простого і захистити себе від можливих ризиків.
- Визначте “бюджет” або часові рамки. Давайте подивимося, що ми зможемо зробити за Х тижнів, а потім вирішимо, як і чи варто продовжувати. Зазвичай, 2-4 тижнів достатньо, щоб зрозуміти базовий PoC. Якщо він виглядає багатообіцяючим – продовжуйте інвестувати ресурси для його покращення.
- Експериментуйте – незалежно від того, який підхід ви обираєте для етапу експериментів – висхідний чи низхідний, ваша мета полягає в тому, щоб максимізувати частоту повторення результатів. До кінця першої ітерації експерименту у вас має бути певна точка дотику (з якою зацікавлені сторони можуть погратися) і базовий рівень, якого ви досягли.
- Ретроспектива – до кінця етапу дослідження ми можемо зрозуміти доцільність, обмеження та вартість створення такого додатку. Це допомагає нам вирішити, чи варто запускати його у виробництво і як розробити кінцевий продукт та його користувацький інтерфейс.
- Продукціонізація – розробіть готову до виробництва версію вашого проекту та інтегруйте її з рештою вашого рішення, дотримуючись стандартних практик SWE та впроваджуючи механізм зворотного зв’язку та збору даних.
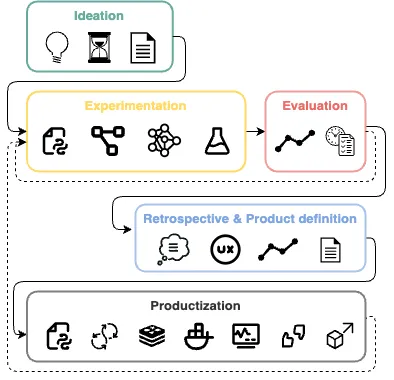
Щоб добре реалізувати процес, орієнтований на експеримент, ми повинні прийняти обґрунтоване рішення щодо підходу та побудови цих експериментів:
Початок з мінімуму: підхід «знизу вгору»
Хоча багато ранніх користувачів швидко переходять до “передових” багатоланцюгових агентних систем з повноцінною реалізацією Langchain або чогось подібного, я виявив, що підхід «знизу вгору» часто дає кращі результати.
Почніть економно, дуже економно, використовуючи філософію “один запит керує всіма“. Хоча ця стратегія може здатися нетрадиційною і, швидше за все, спочатку дасть погані результати, вона встановлює базову лінію для вашої системи.
Відтоді постійно повторюйте і вдосконалюйте свої підказки, використовуючи методи швидкого інжинірингу для оптимізації результатів. Коли ви виявите слабкі місця у вашому ощадливому рішенні, розділіть процес, додавши гілки для усунення цих недоліків.
Розробляючи кожен “листок” мого графіка робочого процесу LLM, або архітектури LLM, я використовую Магічний трикутник³, щоб визначити, де і коли обрізати гілки, розділити їх або потовщити коріння (використовуючи методи оперативного інжинірингу) і вичавити з лимона більше користі.
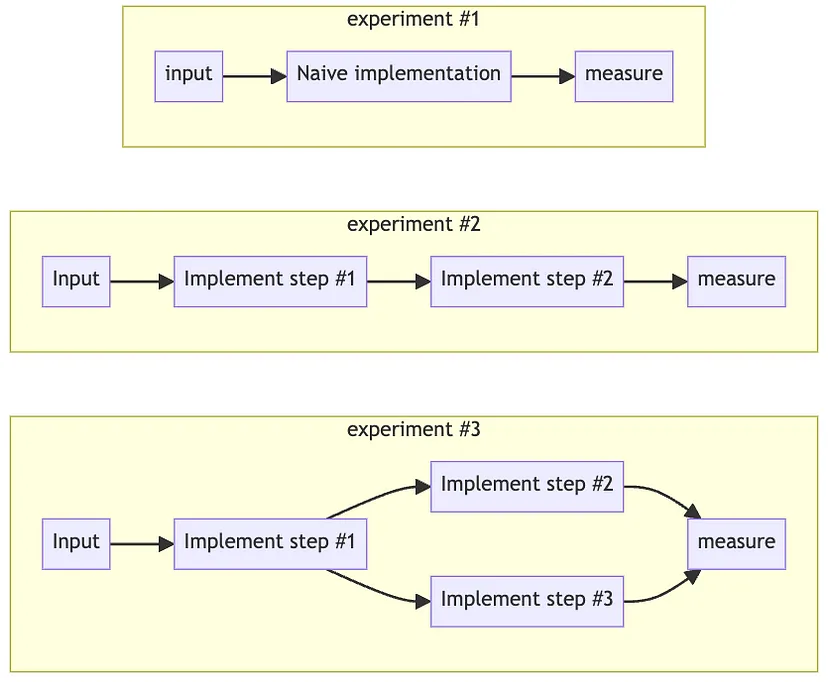
Наприклад, щоб реалізувати “Запити на рідній мові SQL” за допомогою висхідного підходу, ми почнемо з того, що наївно надішлемо схеми до LLM і попросимо її згенерувати запит.
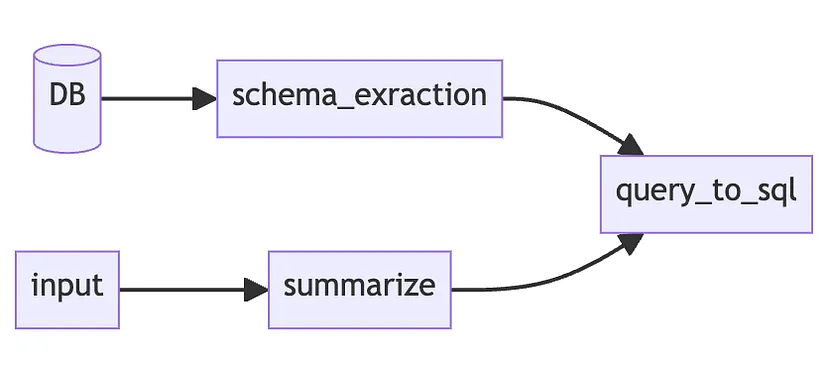
Зазвичай це не суперечить підходу “зверху-вниз”, а слугує ще одним кроком перед ним. Це дозволяє нам показати швидкі перемоги та залучити більше інвестицій у проект.
Загальна картина наперед: Стратегія зверху-вниз
“Ми знаємо, що робочий процес LLM непростий, і щоб досягти нашої мети, нам, ймовірно, доведеться розробити певний робочий процес або архітектуру, притаманну для LLM”.
Підхід “зверху-вниз” визнає це і починає з проектування архітектури LLM з першого дня і впровадження різних етапів/ланцюжків з самого початку.
Таким чином, ви можете протестувати свою архітектуру робочого процесу в цілому і вичавити весь лимон, замість того, щоб вдосконалювати кожен листок окремо.
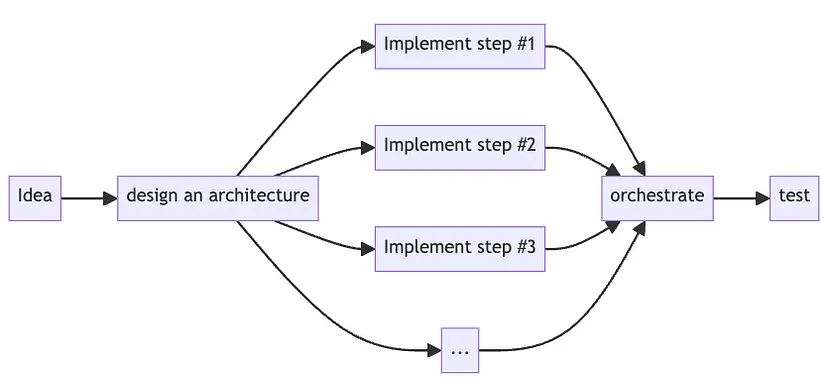
Наприклад, щоб реалізувати “Запити на рідній мові SQL” за допомогою низхідного підходу, ми почнемо проектувати архітектуру ще до того, як почнемо писати код, а потім перейдемо до повної реалізації:
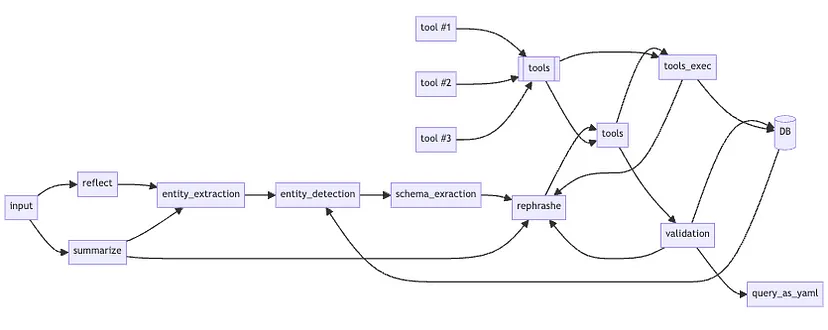
Пошук правильного балансу
Коли ви почнете експериментувати з LLM, ви, ймовірно, почнете з однієї з крайнощів (надмірно складного низхідного або надпростого одномоментного). Насправді, немає жодного правильного варіанту.
В ідеалі – ви визначите хороший SoP¹ і змоделюєте експерта, перш ніж кодувати і експериментувати з моделлю. В реальності моделювання дуже складне; іноді у вас може не бути доступу до такого експерта.
Я вважаю, що з першого пострілу важко влучити в хорошу архітектуру/SoP¹, тому варто поекспериментувати злегка, перш ніж братися за важку зброю. Однак це не означає, що все повинно бути надто аскетичним. Якщо у вас вже є попереднє розуміння того, що щось МАЄ бути розбите на менші частини – зробіть це.
У будь-якому випадку, ви повинні використовувати парадигму “магічного трикутника” і правильно моделювати ручний процес під час розробки рішення.
Оптимізація вашого рішення: Вичавлювання лимона
На етапі експериментів ми безперервно вичавлюємо лимон і додаємо більше “шарів складності”:
- Техніки розробки запитів (prompt engineering) — як-от Few Shots (декілька прикладів), призначення ролей (Role assignment) або навіть динамічний Few-Shot (Dynamic few-shot).
- Розширення контекстного вікна від простої інформації про змінні до складних потоків RAG може допомогти покращити результати.
- Експериментуйте з різними моделями – різні моделі по-різному справляються з різними завданнями. Крім того, великі LLM часто не дуже рентабельні, тому варто спробувати моделі, які більше орієнтовані на конкретні завдання.
- Оптимізація запиту (Prompt dieting) — Я дізнався, що скорочення SOP¹ (зокрема, самого запиту та очікуваного результату) часто покращує затримку. Зменшивши розмір запиту та кількість кроків, які модель повинна виконати, ми можемо зменшити як вхідні, так і вихідні дані, які модель генерує. Це може вас здивувати, але іноді оптимізація запиту навіть покращує якість!¹SOP — стандартна операційна процедура.
Майте на увазі, що дієта також може спричинити погіршення якості, тому важливо провести тест на здоровий глузд перед її початком. - Поділ процесу на менші кроки також може бути дуже корисним і зробити оптимізацію підпроцесу вашого SOP¹ простішою і здійсненною.
Пам’ятайте, що це може збільшити складність рішення або погіршити продуктивність (наприклад, збільшити кількість оброблюваних токенів). Щоб уникнути цього, намагайтеся використовувати стислі підказки та менші моделі.
Як правило, доцільно розділяти, коли кардинальна зміна системної підказки дає набагато кращі результати для цієї частини потоку SOP¹.

Анатомія LLM-експерименту
Особисто я вважаю за краще починати lean з простого Jupyter Notebook з використанням Python, Pydantic та Jinja2:
- Використовуйте Pydantic, щоб визначити схему моїх виходів з моделі.
- Напишіть шаблон підказки (prompt template) за допомогою Jinja2.
- Визначити структурований вихідний формат (у YAML²). Це забезпечить, щоб модель слідувала “крокам мислення” і керувалася моїм СОП.
- Перевірте цей вивід за допомогою валідації Pydantic; якщо потрібно – повторіть спробу.
- Стабілізуйте свою роботу – структуруйте код на функціональні блоки за допомогою файлів і пакетів Python.
У більш широкому масштабі ви можете використовувати різні інструменти, такі як openai-streaming, щоб легко використовувати потокове передавання (та інструменти), LiteLLM, щоб мати стандартизований LLM SDK для різних провайдерів, або vLLM для обслуговування LLM з відкритим вихідним кодом.
Забезпечення якості за допомогою тестів та оцінок осудності
Тест на здоровий глузд оцінює якість вашого проекту і гарантує, що ви не погіршуєте певний базовий рівень успішності, який ви визначили.
Подумайте про своє рішення/підказки як про коротку ковдру – якщо ви розтягнете її занадто сильно, вона може раптом не покривати деякі випадки використання, які раніше покривала.
Для цього визначте набір кейсів, які ви вже успішно охопили, і переконайтеся, що ви продовжуєте це робити (або, принаймні, це того варте). У цьому може допомогти уявлення про це як про тест, керований таблицею.
Оцінити успіх “генеративного” рішення (наприклад, написання тексту) набагато складніше, ніж використовувати LLM для інших завдань (таких як категоризація, вилучення сутностей тощо). Для таких завдань вам може знадобитися більш розумна модель (наприклад, GPT4, Claude Opus або LLAMA3-70B), яка буде виступати в ролі “судді”.
Також може бути гарною ідеєю спробувати зробити так, щоб вихідні дані містили “детерміновані частини” перед “генеративними”, оскільки такі види даних легше перевіряти:
cities:
- New York
- Tel Aviv
vibes:
- vibrant
- energetic
- youthful
target_audience:
age_min: 18
age_max: 30
gender: both
attributes:
- adventurous
- outgoing
- culturally curious
# ignore the above, only show the user the `text` attr.
text: Both New York and Tel Aviv buzz with energy, offering endless activities, nightlife, and cultural experiences perfect for young, adventurous tourists.Є кілька передових, 🤩🤩🤩 перспективних рішень, які варто дослідити. Я знайшов їх особливо актуальними при оцінці рішень на основі RAG: погляньте на DeepChecks, Ragas або ArizeAI.
Прийняття обґрунтованих рішень: Важливість ретроспективи
Після кожного значного/часового експерименту або етапу ми повинні зупинитися і прийняти обґрунтоване рішення про те, як і чи варто продовжувати цей підхід.
На цьому етапі ваш експеримент матиме чіткий базовий показник успішності, і ви матимете уявлення про те, що потрібно вдосконалити.
Це також хороший момент, щоб почати обговорювати наслідки цього рішення для створення продукту і почати з “роботи над продуктом”:
- Як це буде виглядати в продукті?
- Які існують обмеження/виклики? Як би ви їх пом’якшили?
- Яка ваша поточна затримка? Чи достатньо вона хороша?
- Яким має бути UX? Які UI хаки можна використовувати? Чи може допомогти стрімінг?
- Яка орієнтовна сума витрат на токени? Чи можемо ми використовувати менші моделі, щоб зменшити витрати?
- Які пріоритети? Чи є якийсь із викликів шоу-стопером?
Припустимо, що досягнутий нами базовий рівень є “достатньо хорошим”, і ми вважаємо, що можемо пом’якшити проблеми, які ми підняли. У такому випадку ми продовжимо інвестувати в проект і вдосконалювати його, гарантуючи, що він ніколи не погіршиться, і використовуватимемо тести на здоровий глузд.

Від експерименту до продукту: Втілення вашого рішення в життя
І останнє, але не менш важливе: ми повинні продукувати нашу роботу. Як і будь-яке інше рішення виробничого рівня, ми повинні впроваджувати концепції виробничої інженерії, такі як логування, моніторинг, управління залежностями, контейнеризація, кешування тощо.
Це величезний світ, але, на щастя, ми можемо запозичити багато механізмів з класичної виробничої інженерії і навіть прийняти багато з існуючих інструментів.
З огляду на це, важливо бути особливо уважними до нюансів, пов’язаних з LLM-додатками:
- Цикл зворотного зв’язку – як ми вимірюємо успіх? Це просто механізм “великого пальця вгору/вниз” чи щось більш складне, що враховує прийняття нашого рішення?
Важливо також збирати ці дані; згодом вони допоможуть нам переглянути “базову лінію” нашого здорового глузду або доопрацювати наші результати за допомогою динамічних знімків чи точного налаштування моделі. - Кешування – На відміну від традиційного SWE, кешування може бути дуже складним, коли ми залучаємо до нашого рішення генеративний аспект. Щоб пом’якшити цю проблему, вивчіть можливість кешування схожих результатів (наприклад, за допомогою RAG) та/або зменшення генеративного виводу (за допомогою суворої схеми виводу).
- Відстеження витрат – Багато компаній вважають дуже спокусливим почати з “сильної моделі” (наприклад, GPT-4 або Opus), однак у процесі виробництва витрати можуть швидко зрости. Уникайте несподіванок на кінцевому рахунку, а також обов’язково вимірюйте вхідні/вихідні токени і відстежуйте вплив вашого робочого процесу (без цих практик – удачі вам у подальшому профілюванні).
- Налагоджуваність і відстеження – переконайтеся, що ви налаштували правильні інструменти для відстеження “помилкового” введення і відстеження його протягом усього процесу. Зазвичай це передбачає збереження введених користувачем даних для подальшого дослідження та налаштування системи відстеження. Пам’ятайте: “На відміну від традиційного програмного забезпечення, ШІ виходить з ладу безшумно!”
Заключне слово: Ваша роль у просуванні технологій, притаманних програмі LLM
Це може бути кінцем статті, але, звичайно, не кінцем нашої роботи. Розробка для LLM – це ітеративний процес, який охоплює більше варіантів використання, викликів та функцій і постійно вдосконалює наш продукт для LLM.
Продовжуючи свій шлях у розробці ШІ, залишайтеся гнучкими, безстрашно експериментуйте і не забувайте про кінцевого користувача. Діліться своїм досвідом та ідеями зі спільнотою, і разом ми зможемо розширити межі можливого за допомогою програм для LLM. Продовжуйте досліджувати, вчитися і створювати – можливості безмежні.
Сподіваюся, цей посібник став цінним помічником у вашій подорожі по розробці додатків для LLM! Я хотів би почути вашу історію – поділіться своїми перемогами та викликами в коментарях нижче. 💬
Якщо ви вважаєте цю статтю корисною, будь ласка, дайте їй кілька оплесків 👏 в Medium та поділіться нею зі своїми колегами-ентузіастами ШІ. Ваша підтримка дуже важлива для мене! 🌍
Давайте продовжимо розмову – не соромтеся звертатися за допомогою email або приєднуйтесь до LinkedIn 🤝
Особлива подяка Йонатану В. Левіну, Галу Перецу, Філіпу Таннору, Орі Коену, Надаву, Бену Губерману, Кармел Барнів, Омрі Аллуш та Лірону Іжакі Аллерханду за ідеї, відгуки та редакторські зауваження.
¹SoP – Стандартна операційна процедура, концепція, запозичена з The Magic Triangle³.
²YAML – я виявив, що використання YAML для структурування вихідних даних набагато краще працює з LLM. Чому? Моя теорія полягає в тому, що він зменшує кількість нерелевантних лексем і поводиться дуже схоже на рідну мову. Ця стаття заглиблюється в цю тему.
³The Magic Triangle – план для розробки на рідній мові LLM; залишайтеся з нами і слідкуйте за мною, щоб прочитати план, коли він буде опублікований.
ОРИГІНАЛ СТАТТІ:Building LLM Apps: A Clear Step-By-Step Guide
АВТОР СТАТІ:Almog Baku
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X:
