Вихід добре змодельованої схеми!
Автор
Shyam Rao, старший спеціаліст-архітектор рішень@ Databricks
Вступ
Схема “зірка” – це широко використовуваний дизайн бази даних у сховищах даних, де транзакційні дані витягуються, трансформуються і завантажуються в схеми, що складаються з центральної таблиці фактів, оточеної узгодженими таблицями розмірностей.
Читайте далі, щоб дізнатися, як оптимально моделювати ваші представлення та факти за допомогою Databricks SQL. DBSQL – це потужна функція платформи Databricks Data Intelligence, яка дозволяє аналітикам даних, інженерам даних і фахівцям з бізнес-аналітики отримувати і візуалізувати дані у високомасштабованому і продуктивному середовищі.
В якості приємного бонусу ми використаємо асистента штучного інтелекту Databricks AI в кінці, щоб створити цілу модель даних з цими кращими практиками і переглянути модель в Unity Catalog. Оскільки штучний інтелект вбудований в Databricks через AI/BI, Genie та багатьох інших можливостей платформи, ефективне моделювання даних стає ще більш важливим, щоб дозволити ШІ розуміти контекст даних.
Чим краще ви моделюєте свої дані заздалегідь, тим легше ви зможете використовувати штучний інтелект на їх основі.
Таблиці представлень (Dimension Tables)
В архітектурі зіркоподібної схеми представлення надають контекст про бізнес-суб’єкти або події, що аналізуються.
Характеристики представлень таблиць
- Описові атрибути: Містить описові дані.
- Ієрархічна структура: Може включати ієрархії для деталізації.
- Унікальний ідентифікатор: Зазвичай сурогатний ключ (Surrogate key).
- Денормалізований дизайн: Сплющений для підвищення продуктивності.
- Статичні або повільно змінні атрибути: Розміри типу SCD1 та SCD2.
Моделювання таблиць представлень в Databricks SQL
Сурогатний ключ:
- Використовуйте стовпці GENERATED AS IDENTITY або хеш-значення.
- Надавайте перевагу цілочисельним сурогатним ключам над рядками для кращої продуктивності.
Представлення, що повільно змінюється (Slowly Changing Dimension, SCD):
- Delta Live Tables (AWS|Azure|GCP) добре підходить для розробки декларативних ETL для представлень, підтримуючи як SCD1, так і SCD2 типи.
Розширення:
- Використовуйте тип даних MAP для зберігання користувацьких або довільних пар ключ:значення. Наприклад, атрибути, визначені користувачем: {«birthPlace» : «Northbridge, Massachusetts, US»}
Приклад визначення розмірної таблиці:
CREATE TABLE g_patient_d (
patient_sk BIGINT GENERATED ALWAYS AS IDENTITY COMMENT 'Primary Key (ID)',
last_name STRING NOT NULL COMMENT 'Last name of the person',
gender STRUCT<cd:STRING, desc:STRING> COMMENT 'Patient gender',
birth_date TIMESTAMP COMMENT 'Birth date and time',
ethnicity STRUCT<cd:STRING, desc:STRING> COMMENT 'Code for ethnicity',
-- using array when it can map easily to source
languages_spoken ARRAY<STRUCT<cd:STRING, desc:STRING>> COMMENT 'Ordered list of known languages (first = preferred)',
patient_contact ARRAY<STRUCT<contact_info_type:STRING COMMENT 'Contact type (Phone/Email/Fax)', contact_info:STRING COMMENT 'Contact information (email address, phone number)', preferred_flag:BOOLEAN COMMENT 'preferred contact (Y/N)'>> COMMENT 'Contact information',
patient_mrn STRING COMMENT 'Patient medical record number',
other_identifiers MAP<STRING, STRING> COMMENT 'Identifier type (passport number, license number except mrn, ssn) and value',
uda MAP<STRING, STRING> COMMENT 'User Defined Attributes',
source_ref STRING COMMENT 'Unique reference to the source record',
effective_start_date TIMESTAMP COMMENT 'SCD2 effective start date for version',
effective_end_date TIMESTAMP COMMENT 'SCD2 effective start date for version',
g_process_id STRING COMMENT 'Process ID for record inserted',
CONSTRAINT g_patient_d_pk PRIMARY KEY(patient_sk)
)
COMMENT 'Patient dimension'
CLUSTER BY (last_name, gender.cd, birth_date, patient_mrn)
-- Optional helpful table properites
TBLPROPERTIES (delta.deletedFileRetentionDuration = 'interval 30 days',
'delta.columnMapping.mode' = 'name', -- Allows you to drop/move/rename columns by name
'delta.dataSkippingStatsColumns' = 'patient_sk,last_name,gender', -- Allows you to control the exact columns in which stats are calculated
'delta.enableChangeDataFeed' = false, -- Alows you to enable change data feed on the table
)
;Властивості та оптимізація таблиць:
- Використовуйте керовані таблиці Delta Lake, щоб скористатися новими функціями, кращими методами зберігання та посиленим контролем доступу.
- Використовуйте Liquid Clustering (AWS|Azure|GCP) на основі атрибутів, що часто фільтруються (до 4 ключів кластеризації)*.
- Використовуйте предиктивну оптимізацію (AWS, Azure), щоб максимізувати продуктивність і мінімізувати витрати.
- Визначте обмеження PRIMARY KEY для сурогатного ключа.
- Переконайтеся, що збирається статистика на рівні стовпців (AWS|GCP|Azure), щоб уможливити пропуск даних. Примітка: Типи даних ARRAY і MAP не мають статистики на рівні стовпців. Не використовуйте їх для стовпців, які часто фільтруються. Ви можете використовувати властивість таблиці ‘delta.dataSkippingStatsColumns’ (показано вище), щоб вказати конкретні стовпці, для яких потрібно обчислити статистику, щоб уникнути непотрібного збору статистики і підвищити продуктивність.
Документуйте таблиці та стовпці, використовуючи COMMENTs and TAGS, щоб вбудувати управління даними в діяльність з розвитку. Теги можна використовувати для послідовної характеристики певних стовпців (наприклад, тег PII) або таблиць (наприклад, тег gold). Теги також можна використовувати для визначення контролю доступу до даних.(access control)
Типовий запит BI з’єднує таблицю фактів з однією або кількома таблицями представлень. Запит агрегує один або кілька фактів за атрибутами представлень. Представлення можуть бути відфільтровані на основі значень атрибутів, що цікавлять. Для прикладу –
SELECT
d.month,
p.category,
SUM(f.sales_amount) as total_sales
FROM sales_fact f
INNER JOIN dim_date d ON f.date_key = d.date_key
INNER JOIN dim_product p ON f.product_key = p.product_key
WHERE d.year = 2023 AND p.category IN ('Electronics', 'Computers')
GROUP BY d.month, p.category
ORDER BY total_sales DESC;Процес оцінювання полягав би в наступному:
a) фільтрація рядків представлень
b) визначення відповідних ключів представлень
c) запит до таблиці фактів з цими ключами.
Таблиці з фактами
Таблиці фактів зберігають кількісні, числові дані, що представляють бізнес-транзакції або події.
Характеристики таблиць фактів
- Деталізовані дані: Захоплює окремі записи на рівні транзакцій або подій.
- Зовнішні ключі: Таблиці представлень посилань.
- Агреговані показники: Можуть містити попередньо обчислені агреговані показники.
- Великий обсяг даних: Зазвичай зберігає великі набори даних.
Моделювання таблиць фактів в Databricks SQL
Заходи (Measures):
- Використовуйте числові типи даних, уникаючи чисел з плаваючою комою (замість них використовуйте DECIMAL).
Приклад визначення таблиці фактів:
CREATE TABLE g_claim_tf (
-- dimension FKs
patient_sk BIGINT NOT NULL COMMENT 'Foreign key to patient dimension',
...
facility_sk BIGINT NOT NULL COMMENT 'Foreign key to facility dimension',
-- measures
length_of_stay INT COMMENT 'Patient length of stay',
billed_amount DECIMAL(10, 2) COMMENT 'Claim billed amount',
…
claim_source_ref INT NOT NULL COMMENT 'Degenerate key for Claim Id from source',
g_insert_date TIMESTAMP COMMENT 'Date record inserted',
g_process_id STRING COMMENT 'Process ID for record inserted',
CONSTRAINT patient_d_fk FOREIGN KEY (patient_sk) REFERENCES g_patient_d(patient_sk),
CONSTRAINT facility_d_fk FOREIGN KEY (facility_sk) REFERENCES g_facility_d(facility_sk)
)
COMMENT 'Claims Transaction Fact'
CLUSTER BY (patient_sk, ..., facility_sk)
;Властивості та оптимізація таблиць:
- Використовуйте керовані таблиці Delta Lake.
- Використовуйте рідку кластеризацію (Liquid Clustering) (AWS|Azure|GCP) на основі зовнішніх ключів розмірів (для розмірів, що часто фільтруються та об’єднуються). Це допоможе швидко знаходити записи фактів для конкретних ключів розмірностей, які об’єднуються.
- Використовуйте предиктивну оптимізацію (AWS|Azure) для підвищення продуктивності та економічної ефективності.
- Визначте обмеження FOREIGN KEY для стовпців ключа розмірності для оптимізації запиту.
- ANALYZE TABLE ім’я_таблиці COMPUTE STATISTICS FOR COLUMNS <вимірні ключі>, для планування запитів та адаптивного виконання запитів.
- Документуйте таблиці і стовпці за допомогою коментарів і тегів. Це може підвищити ефективність таких функцій, як AI/BI: Інтелектуальна аналітика для реальних даних.
- Розбиття на розділи (або просто рідка кластеризація) може бути корисним лише для дуже великих таблиць (сотні терабайт).
Роздуми про оновлення та версійність:
Таблиці фактів транзакцій, як правило, не оновлюються і не мають версій. Функція подорожі в часі в Delta Lake дозволяє отримати доступ до історичних даних, які можуть бути корисними для аналізу граничних ситуацій в межах налаштованого періоду зберігання дельта-журналу.
Рівень презентації (Presentation Layer)
Views
Схема “зірка” часто створюється в золотому шарі(Golden Layer) архітектури медальйона. Вдосконалюйте свої інформаційні панелі(dashboards) та процеси звітування, створюючи та демонструючи подання поверх таблиць представлень та фактів.
Подання можна використовувати:
- Адаптуйте презентацію: Показуйте лише основні атрибути (наприклад, основну адресу).
- Спростіть представлення атрибутів: Типи ARRAY і STRUCT (а також VARIANT) можуть бути сумісні не з усіма інструментами бізнес-аналітики або не завжди зручні для побудови аналітики на їх основі.
- Створіть рольові представлення: Наприклад, об’єкт відправлення проти об’єкта отримання.
- Використовуйте узгоджені формули: Легко додавайте нові розрахункові показники на основі запиту користувача.
Приклад визначення розмірного подання:
CREATE VIEW g_patient_d_v (
patient_sk, last_name,
gender_code COMMENT 'Code for the patients gender', gender_desc COMMENT 'Patient gender',
date_of_birth COMMENT 'Date of birth',
spoken_language1 COMMENT 'Preferred language', spoken_language2 COMMENT 'Other spoken language',
preferred_contact_type, preferred_contact, patient_mrn, birth_place COMMENT 'Place of birth',
source_ref, effective_start_date, effective_end_date
)
AS
SELECT
patient_sk,
last_name,
gender.cd AS gender_code,
gender.desc AS gender_desc,
cast(birth_date AS DATE) AS date_of_birth,
try_element_at(languages_spoken, 1) AS spoken_language1,
try_element_at(languages_spoken, 2) AS spoken_language2,
filter(patient_contact, x -> x.preferred_flag)[0].contact_info_type AS preferred_contact_type,
filter(patient_contact, x -> x.preferred_flag)[0].contact_info AS preferred_contact,
patient_mrn,
try_element_at(uda, 'birthplace') AS birth_place,
source_ref,
effective_start_date,
effective_end_date
FROM g_patient_d
;Використання Databricks SQL Warehouse
Ось кілька додаткових порад щодо використання екосистеми навколо вашої моделі даних для побудови високоякісної виробничої системи.
Прискорення ELT
Профайлінг даних (Data profiling):
- Використовуйте Lakehouse Federation (AWS|Azure|GCP) для підключення до різних джерел даних на етапі дослідження.
Поглинання даних (Data ingestion):
- Команда COPY INTO – Використовуйте команду COPY INTO (AWS|Azure|GCP) для пакетного прийому файлів у Delta Lake. Ця команда масштабує файли з однократною семантикою, подібно до потокової передачі таблиць у простому пакетному режимі. Вона має безліч потужних опцій (наприклад, regex-фільтрація файлів для безпеки при отримані, опція перезавантаження та багато іншого!).
- Потокові таблиці – створюйте потокові таблиці за допомогою команди CREATE STREAMING TABLE (AWS|Azure|GCP) для інкрементальної обробки даних. Додатковою перевагою потокових таблиць є те, що їх можна легко налаштувати на пакетне оновлення або оновлення в реальному часі, а також на щось середнє між ними. Це справжній потік даних з файлів черг Kafka/Kinesis/EventHub – і все це на SQL! У потокових таблицях ви можете визначити частоту оновлення у визначенні таблиці ось так:
CREATE STREAMING TABLE firehose_bronze
SCHEDULE CRON '0 0 * * * ? *'
AS SELECT
from_json(raw_data, 'schema_string') data,
* EXCEPT (raw_data)
FROM STREAM firehose_raw;Якість передачі даних (Data quality):
Очікування щодо якості даних – Очікування дозволяють вам визначити конкретні критерії або правила, яким повинні відповідати дані. Ви можете використовувати кілька різних типів очікувань щодо якості даних у таблицях.
1. Обмеження EXPECT для потокових таблиць – Ви можете застосувати обмеження для потокових таблиць, які функціонують так само, як Delta Live Tables Expectations (Очікування для таблиць в реальному часі). Вони набагато динамічніші і пропонують різні дії, якщо дані не відповідають вашим правилам, наприклад, WARN, DROP або FAIL. Ви можете визначити очікування потокової таблиці таким чином:
CREATE OR REFRESH STREAMING TABLE bronze_data (
CONSTRAINT date_parsing (to_date(dt) >= '2000-01-01') ON VIOLATION FAIL UPDATE
)
AS SELECT *
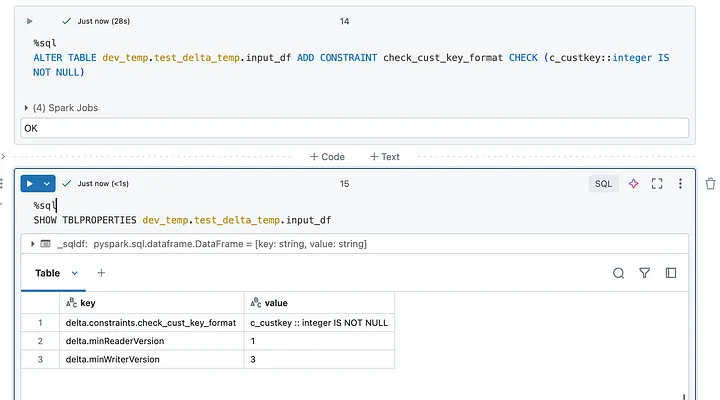
FROM STREAM read_files('s3://my-bucket/my_data');2. CHECK Constraints — це правила, що застосовуються до даних у будь-якій таблиці Delta, а не лише до потокових таблиць, тому вони є більш широкою та загальною таблицею очікуваної якості даних. Ви можете додавати обмеження CHECK (перевірка) до таблиці, щоб забезпечити якість і цілісність даних, наприклад, таким чином:
-- Add Constraint to new table
CREATE TABLE persons(first_name STRING NOT NULL,
last_name STRING NOT NULL,
nickname STRING,
CONSTRAINT persons_pk PRIMARY KEY(first_name, last_name));
-- Add constraint to existing table
ALTER TABLE people10m ADD CONSTRAINT dateWithinRange
CHECK (birthDate > '1900-01-01');Коли ви додаєте обмеження до таблиці, ви можете легко побачити його у властивостях таблиці, як показано нижче:
Перетворення даних:
- Потокові таблиці + матеріалізовані view: Створюйте матеріалізовані view для попереднього обчислення результатів на основі останніх даних у вихідних таблицях. Матеріалізовані view забезпечують простий, декларативний спосіб обробки даних для відповідності, виправлення, агрегування або загального збору даних про зміни (CDC).
- Запити (queries) та конвеєри (pipelines) SQL: Це більш імперативний підхід старої школи, але часто необхідний для більш складних конвеєрів ETL. Запускайте SQL-Notebooks або dbt-Tasks на вашому SQL-DataWareHouse. Ви використовуєте Task-SQL у завданнях потоків для запуску SQL-запитів Databricks у вашому сховищі SQL. Використовуйте такі функції, як тимчасові уявлення, MERGE, функції, змінні SQL, EXECUTE IMMEDIATE, параметри завдання, обмін інформацією між завданнями, умовний запуск завдань і т.д. Діалект SQL Databricks швидко розвивається, тож чекайте на нові функції та блоги про програмування на SQL у найближчому майбутньому!
Оркестрування:
- Використовуйте Databricks Workflows (AWS|Azure|GCP) для впорядкування завдань і робочих місць.
- Ви можете оновлювати матеріалізовані view і потокові таблиці за розкладом, визначеним як частина таблиці DDL.
BI та Dashboarding:
- Використовуйте безсерверний DBSQL(Serverless DBSQL) Warehouse для запитів до схеми “зірка”.
- Скористайтеся перевагами інтелектуального управління робочим навантаженням (лише для безсерверних систем), Photon Engine, адаптивного виконання запитів та предиктивної оптимізації.
Приклад прикладного моделювання, згенерований Асистентом штучного інтелекту Databricks
Давайте візьмемо деякі з цих концепцій і створимо дійсно швидкий приклад моделі даних для візуалізації в Unity Catalog. Щоб створити наш приклад, ми можемо просто попросити асистента штучного інтелекту Databricks згенерувати модель даних, використовуючи деякі з наших найкращих практик, за допомогою наступної підказки:
Write a SQL script to create a new schema called `main.model_tpch` and copy all tables from the `samples.tpch` schema into it. Ensure that the tables are created only if they do not already exist. Ensure to create proper primary and foreign keys based on the column name matches across tables. To avoid creating foreign key relationships to tables before they are created, use the ALTER TABLE ADD CONSTRAINT command after all the table CREATE statements. Remember that each ALTER TABLE ADD CONSTRAINT command must be a separate command for each constraint, even within the same table. Optimize the tables by using `CLUSTER BY` on the primary and foreign keys for each table. After creating the tables, insert data from the source tables into the new tables. == UA == Напишіть SQL-скрипт для створення нової схеми з назвою `main.model_tpch` і скопіюйте до неї всі таблиці зі схеми `samples.tpch`. Переконайтеся, що таблиці створюються лише тоді, коли вони ще не існують. Переконайтеся, що ви створили правильні первинні та зовнішні ключі на основі збігів імен стовпців у таблицях. Щоб уникнути створення зв'язків зовнішніх ключів з таблицями до їх створення, використовуйте команду ALTER TABLE ADD CONSTRAINT після всіх інструкцій CREATE таблиці. Пам'ятайте, що кожна команда ALTER TABLE ADD CONSTRAINT повинна бути окремою командою для кожного обмеження, навіть у межах однієї таблиці. Оптимізуйте таблиці, використовуючи `CLUSTER BY` на первинних і зовнішніх ключах для кожної таблиці. Після створення таблиць вставте дані з вихідних таблиць у нові таблиці.
Він витягне зразки даних, які постачаються з усіма розгортаннями Databricks, і використає їх для створення добре змодельованої версії в Unity Catalog з усіма обмеженнями і кластерними ключами, визначеними для вас. Потім помічник ШІ надасть нам наступні результати, які ми зможемо запустити і візуалізувати у Unity Catalog:
-- Step 1: Create the new schema
--DROP SCHEMA IF EXISTS main.model_tpch CASCADE;
CREATE SCHEMA IF NOT EXISTS main.model_tpch;
-- Step 2: Generate DDL statements with primary keys and CLUSTER BY
-- Customer table
CREATE TABLE IF NOT EXISTS main.model_tpch.customer (
c_custkey INT PRIMARY KEY,
c_name STRING,
c_address STRING,
c_nationkey INT,
c_phone STRING,
c_acctbal DECIMAL(18, 2),
c_mktsegment STRING,
c_comment STRING
)
CLUSTER BY (c_custkey);
-- Orders table
CREATE TABLE IF NOT EXISTS main.model_tpch.orders (
o_orderkey INT PRIMARY KEY,
o_custkey INT,
o_orderstatus STRING,
o_totalprice DECIMAL(18, 2),
o_orderdate DATE,
o_orderpriority STRING,
o_clerk STRING,
o_shippriority INT,
o_comment STRING
)
CLUSTER BY (o_orderkey, o_custkey);
-- Lineitem table
CREATE TABLE IF NOT EXISTS main.model_tpch.lineitem (
l_orderkey INT,
l_partkey INT,
l_suppkey INT,
l_linenumber INT,
l_quantity DECIMAL(18, 2),
l_extendedprice DECIMAL(18, 2),
l_discount DECIMAL(18, 2),
l_tax DECIMAL(18, 2),
l_returnflag STRING,
l_linestatus STRING,
l_shipdate DATE,
l_commitdate DATE,
l_receiptdate DATE,
l_shipinstruct STRING,
l_shipmode STRING,
l_comment STRING,
PRIMARY KEY (l_orderkey, l_linenumber)
)
CLUSTER BY (l_orderkey, l_linenumber);
-- Part table
CREATE TABLE IF NOT EXISTS main.model_tpch.part (
p_partkey INT PRIMARY KEY,
p_name STRING,
p_mfgr STRING,
p_brand STRING,
p_type STRING,
p_size INT,
p_container STRING,
p_retailprice DECIMAL(18, 2),
p_comment STRING
)
CLUSTER BY (p_partkey);
-- Partsupp table
CREATE TABLE IF NOT EXISTS main.model_tpch.partsupp (
ps_partkey INT,
ps_suppkey INT,
ps_availqty INT,
ps_supplycost DECIMAL(18, 2),
ps_comment STRING,
PRIMARY KEY (ps_partkey, ps_suppkey)
)
CLUSTER BY (ps_partkey, ps_suppkey);
-- Supplier table
CREATE TABLE IF NOT EXISTS main.model_tpch.supplier (
s_suppkey INT PRIMARY KEY,
s_name STRING,
s_address STRING,
s_nationkey INT,
s_phone STRING,
s_acctbal DECIMAL(18, 2),
s_comment STRING
)
CLUSTER BY (s_suppkey);
-- Nation table
CREATE TABLE IF NOT EXISTS main.model_tpch.nation (
n_nationkey INT PRIMARY KEY,
n_name STRING,
n_regionkey INT,
n_comment STRING
)
CLUSTER BY (n_nationkey);
-- Region table
CREATE TABLE IF NOT EXISTS main.model_tpch.region (
r_regionkey INT PRIMARY KEY,
r_name STRING,
r_comment STRING
)
CLUSTER BY (r_regionkey);
-- Step 3: Add foreign key constraints
ALTER TABLE main.model_tpch.customer
ADD CONSTRAINT fk_customer_nation FOREIGN KEY (c_nationkey) REFERENCES main.model_tpch.nation(n_nationkey);
ALTER TABLE main.model_tpch.orders
ADD CONSTRAINT fk_orders_customer FOREIGN KEY (o_custkey) REFERENCES main.model_tpch.customer(c_custkey);
ALTER TABLE main.model_tpch.lineitem
ADD CONSTRAINT fk_lineitem_orders FOREIGN KEY (l_orderkey) REFERENCES main.model_tpch.orders(o_orderkey);
ALTER TABLE main.model_tpch.lineitem
ADD CONSTRAINT fk_lineitem_part FOREIGN KEY (l_partkey) REFERENCES main.model_tpch.part(p_partkey);
ALTER TABLE main.model_tpch.lineitem
ADD CONSTRAINT fk_lineitem_supplier FOREIGN KEY (l_suppkey) REFERENCES main.model_tpch.supplier(s_suppkey);
ALTER TABLE main.model_tpch.partsupp
ADD CONSTRAINT fk_partsupp_part FOREIGN KEY (ps_partkey) REFERENCES main.model_tpch.part(p_partkey);
ALTER TABLE main.model_tpch.partsupp
ADD CONSTRAINT fk_partsupp_supplier FOREIGN KEY (ps_suppkey) REFERENCES main.model_tpch.supplier(s_suppkey);
ALTER TABLE main.model_tpch.supplier
ADD CONSTRAINT fk_supplier_nation FOREIGN KEY (s_nationkey) REFERENCES main.model_tpch.nation(n_nationkey);
ALTER TABLE main.model_tpch.nation
ADD CONSTRAINT fk_nation_region FOREIGN KEY (n_regionkey) REFERENCES main.model_tpch.region(r_regionkey);
-- Step 4: Insert data from source tables into the new tables
INSERT INTO main.model_tpch.customer
SELECT * FROM samples.tpch.customer;
INSERT INTO main.model_tpch.orders
SELECT * FROM samples.tpch.orders;
INSERT INTO main.model_tpch.lineitem
SELECT * FROM samples.tpch.lineitem;
INSERT INTO main.model_tpch.part
SELECT * FROM samples.tpch.part;
INSERT INTO main.model_tpch.partsupp
SELECT * FROM samples.tpch.partsupp;
INSERT INTO main.model_tpch.supplier
SELECT * FROM samples.tpch.supplier;
INSERT INTO main.model_tpch.nation
SELECT * FROM samples.tpch.nation;
INSERT INTO main.model_tpch.region
SELECT * FROM samples.tpch.region;Тепер давайте подивимося на діаграму «Сутність-взаємозв’язок» для нашої моделі! Для цього клацніть на нашій новій схемі, виберіть таблицю і натисніть кнопку «Переглянути зв’язки»:
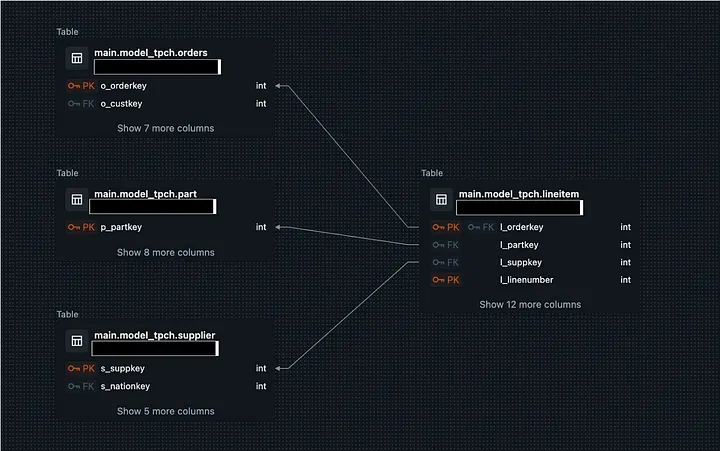
Висновок
Дотримуючись цих вказівок, ви зможете ефективно моделювати та оптимізувати вашу Star Schema в Databricks SQL, використовуючи розширені можливості та найкращі практики для забезпечення високої продуктивності та масштабованості. Такий підхід дозволяє створити надійне сховище даних, яке підтримує ефективні запити та аналітику, тож почніть!
ОРИГІНАЛ СТАТТІ:Star Schema Data Modeling Best Practices on Databricks SQL
АВТОР СТАТІ:Databricks SQL SME
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X: