from https://www.getdbt.com/product/what-is-dbt
Рано чи пізно аналітик стикається з проблемою організації даних. Їх стає дедалі більше, структура перестає бути прозорою, а одні й ті самі SQL-запити доводиться переписувати по кілька разів. Вирішити цю проблему можна за допомогою dbt – інструменту, який відкриває новий підхід до трансформації та моделювання даних. Під катом – переклад чудової статті Девіда Кревітта про те, що таке dbt, і як цей інструмент допомагає аналітикам полегшити свою роботу.
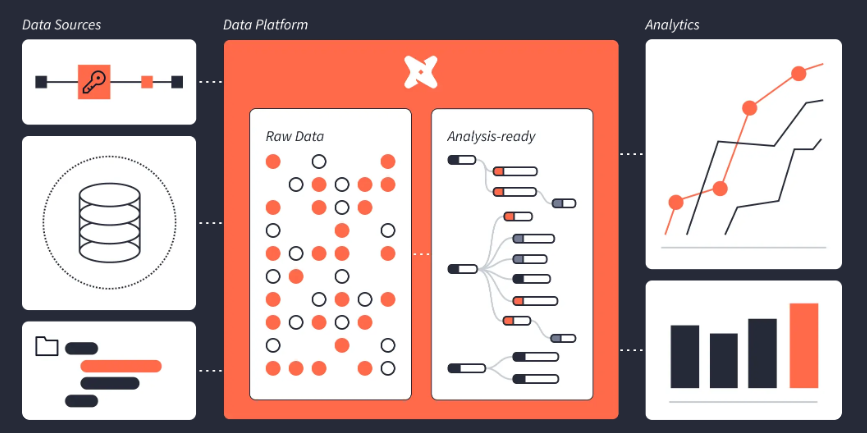
dbt (data build tool) – це фреймворк з відкритим вихідним кодом для виконання, тестування та документування SQL-запитів, який дає змогу привнести елемент програмної інженерії в процес аналізу даних.
Це прекрасний зразок у наборі “ледачих” інструментів, який допомагає ніколи не повторюватися під час аналізу даних.
Заміна збереженого запиту
Кожен SQL-запит заслуговує на гарний “дім”. У dbt SQL-запити структуровані та розкладені по папках проєкту, тому всі члени команди завжди знають, де їх знайти:
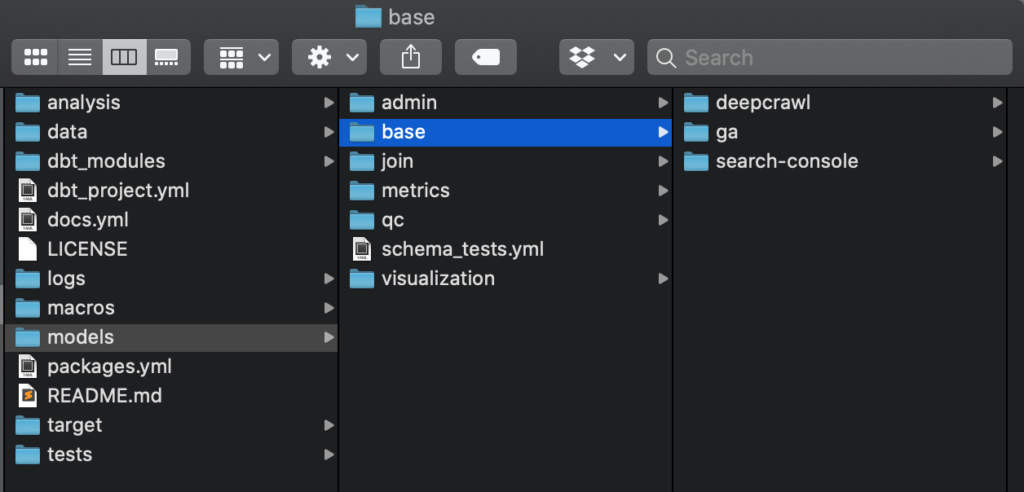
Щоразу, коли потрібно запустити запити, ви використовуєте команду dbt run.
Ця команда бере колекцію SQL моделей у проєкті dbt і оновлює їх у сховищі даних.
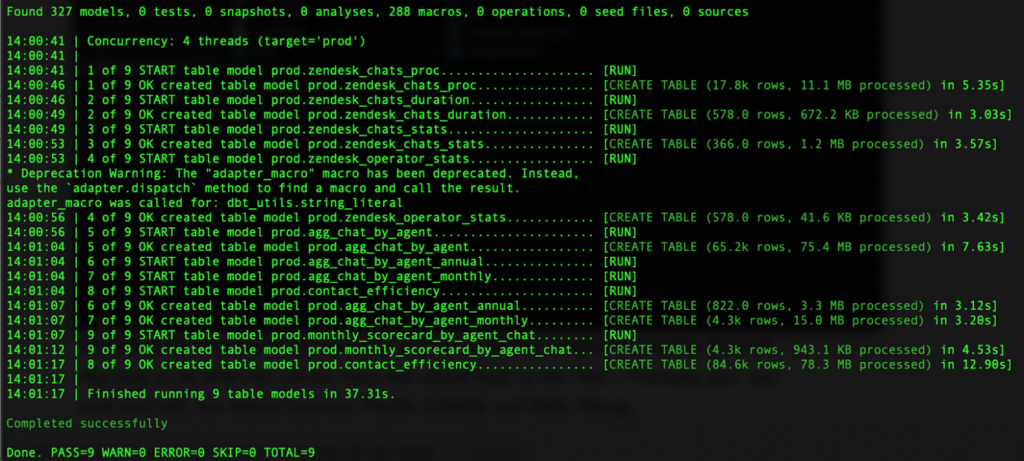
Просто, але ефективно.
Це означає, що більше не потрібно зберігати фрагменти SQL-запитів на робочому столі або деінде, як скриню зі скарбами.
Розосередження і дезорганізація роботи – ось що вбиває проекти аналізу даних. Через це вам складно пригадати, як вдалося прийти до рішення вперше, і доводиться розв’язувати задачу повторно.
dbt дає вашій аналітичній роботі постійний дім і формальну структуру – дисципліну, якщо хочете.
ref(‘ ‘) змінить ваше життя
dbt дає змогу посилатися на інші запити в SQL-запитах, викликаючи їх через {{ ref(‘model name’) }}.
Це допомагає скоротити кількість запитів:

Таким чином, кожен запит виконує окреме завдання. Ми будуємо структури проекту dbt як листковий пиріг, що складається з безлічі взаємозалежних шарів, кожен з яких виконує свою роботу:
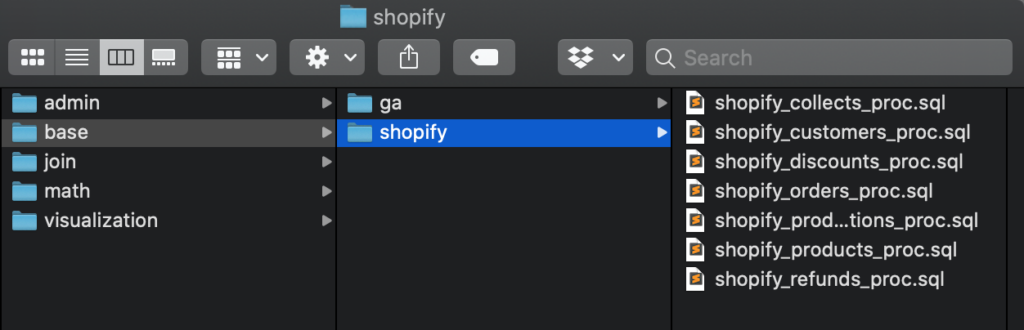
- /admin моделі зберігають налаштування нашого конвеєра даних
- /base моделі для дедуплікації та очищення сирих даних
- /join моделі для об’єднання декількох/базових таблиць
- /math моделі рахують метрики (відтік, утримання) і використовуються в будь-якій складній математиці (прогнозування тощо)
- /visualization моделі уточнюють імена стовпців + отримують дані у форматі, готовому до презентації.
Це спрощує відповіді на запитання про те, як розраховуються метрики.
“Як ми очищаємо дані Google Analytics?”
Загляньте в папку base -> google-analytics.
“Як ми розраховуємо коефіцієнт утримання когорт?”
Папка Math -> cohort-analysis.
Це спрощує навігацію по SQL-запитах. dbt – протиотрута від Monster Queries™, які може зрозуміти і пояснити тільки їхній автор.
SQL який пише себе сам
dbt виводить написання SQL-запитів на новий рівень двома способами: макроси + шаблони JINJA.
Макроси
Створення SQL-запитів зазвичай передбачає багато рутини.
Наприклад, коли потрібно повторити оператор CASE 15 разів для різних умов:
CASE WHEN x = y THEN z
WHEN 2x = 2y THEN 2z
Бла-бла-бла… Це може призвести до синдрому зап’ястного каналу.
Ще один класичний випадок – об’єднання двох таблиць, за якого вам традиційно доводилося повторювати поля кожної таблиці:
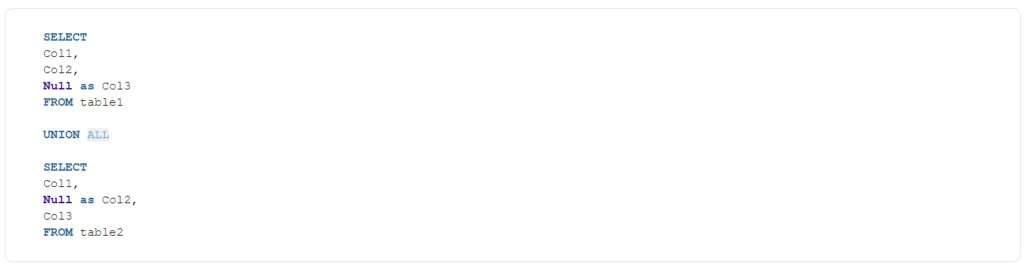
Завдяки dbt фрагменти SQL можна повторювати за допомогою макросів.
Команда dbt навіть пропонує зручний список ключових макросів у модулі dbt_utils, щоб полегшити рутинну роботу аналітиків.
Кілька макросів, які команда CIFL використовує щодня:
Шаблони JINJA
Програмування дає нам ключові механізми, що дають змогу не повторюватися: цикли FOR, оператори IF-THEN тощо.
dbt значно спрощує вбудовування цієї програмної логіки у ваші SQL-запити, дозволяючи писати запити в нотації JINJA.
Це означає, що замість жорсткого кодування SQL-запитів ви можете створювати запити, які пишуть себе самі.
Наприклад, часто під час створення конвеєра обробки даних ми зберігаємо список цілей Google Analytics для клієнтів агентства:
- Клієнт 1 використовує цілі №2 і №9.
- Клієнт 2 використовує цілі №4 і №11.
Завдання полягає в тому, щоб створити один стовпець “Досягнуті цілі” для кожного клієнта в рамках одного запиту.
До dbt ми писали ці запити вручну:

За допомогою dbt ми генеруємо запит динамічно, використовуючи шаблон JINJA:

Таким чином, замість того, щоб вручну оновлювати запит щоразу під час зміни числа переходів до мети клієнта, ми просто записуємо нове значення в таблицю, і запит пишеться сам. Справжня знахідка для “ледачого” аналітика.
dbt + Git
З dbt + Git ви можете аналізувати дані як команда розробників програмного забезпечення. Це означає перевірку коду за допомогою розділу “Pull Requests” і відстеження помилок за допомогою “Issues”. Більше не потрібно редагувати SQL-запити через довгі ланцюжки в Slack/Notion/email.
Це має кілька корисних ефектів:
- Люди серйозніше ставляться до SQL-запитів і дають їм простір і час, необхідний для розробки. Поспіх і перерви – два вороги хорошої роботи з даними.
- Запити пишуться один раз, а потім стають доступними для використання іншими членами команди. При правильному використанні це означає, що ви ніколи не будете писати один і той самий запит двічі.
- Ви пишете SQL більш високої якості, тому що він буде повторно використовуватися іншими людьми.
Запуск SQL-запитів за розкладом
“Коли востаннє оновлювалися ці дані?” – це питання аналітики чують постійно.
З dbt відповідь ніколи не викликає сумнівів.
Fishtown Analytics (команда, що стоїть за dbt) пропонує dbt Cloud, hosted платформу для запуску проєктів dbt за розкладом.
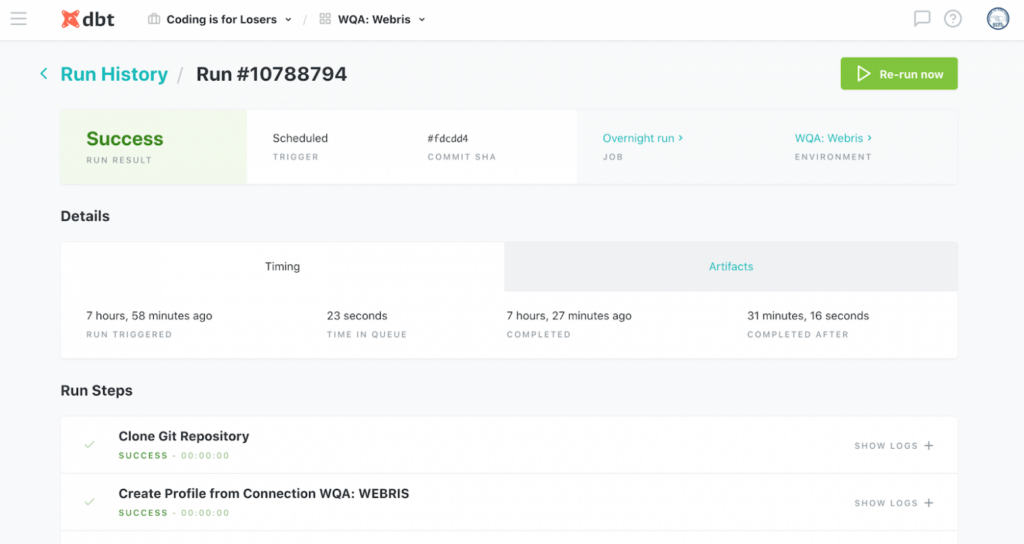
dbt Cloud являє собою простий інтерфейс для перегляду статусу виконання різних моделей, результатів тестування і програмно створеної документації.
Реєстрація для першого користувача безкоштовна, для кожного наступного – $50 на місяць.
“Ледаче” документування даних
“Як розраховувалася ця метрика?”
“З якої таблиці із сирими даними взято це поле?”
На ці запитання ніколи не потрібно відповідати більше одного разу – ось чому існує документація. Але в документування є дві ключові проблеми:
Актуальність
Якщо вам доводиться оновлювати документацію вручну, вона ніколи не залишається актуальною.
Той, хто скаже вам, що його документація, написана вручну, на 100% свіжа, ймовірно, також готовий продати вам острів на Мальдівах.
Розташування
Документація зазвичай зберігається не там, де ви використовуєте свої дані – неможливо написати документацію без документа, але ми, як правило, не аналізуємо дані в документах.
Документація потрібна нам там, де ми використовуємо дані: наприклад, у Google BigQuery або Google Data Studio.
dbt вирішує обидві ці проблеми:
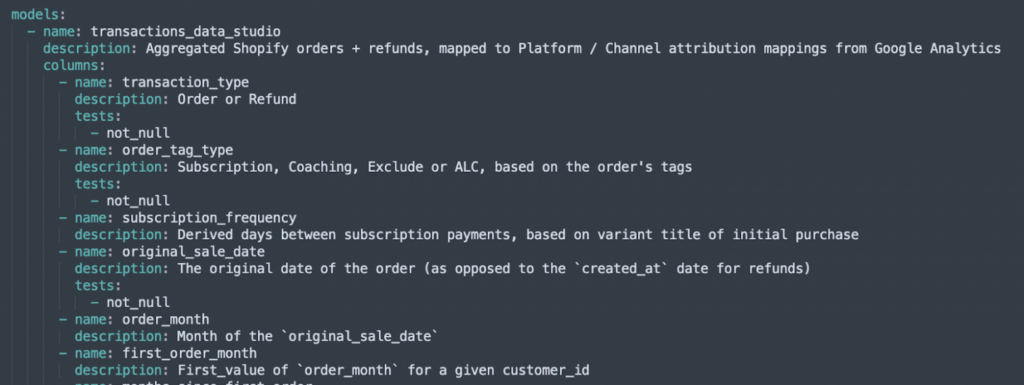
- Команда `dbt docs` програмно генерує візуальний граф залежностей із вашого набору моделей, що дає змогу переглядати залежності SQL моделі на одній сторінці.
- dbt дає змогу додавати описи на рівні таблиці + стовпця з одного файлу .yml у вашому проєкті.
Ці описи передаються як безпосередньо в консоль BigQuery:
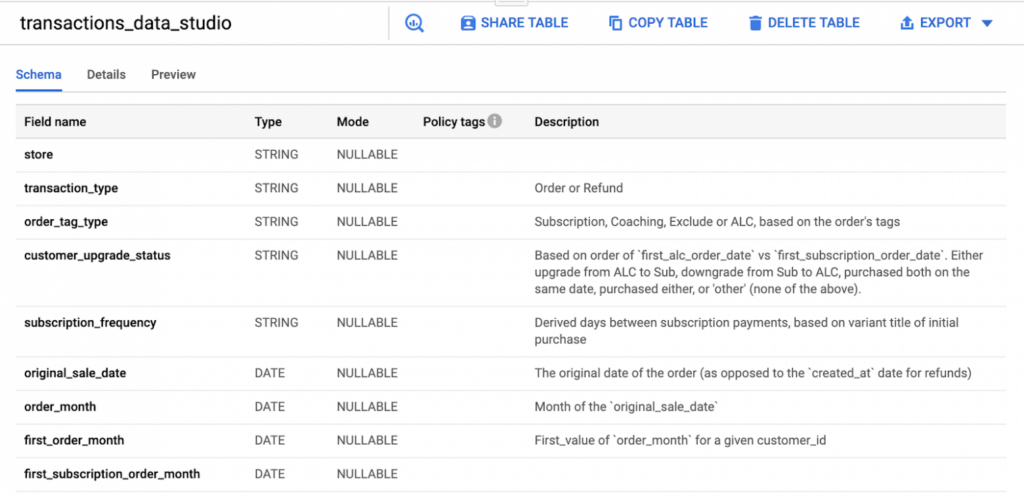
Так і в Data Studio:
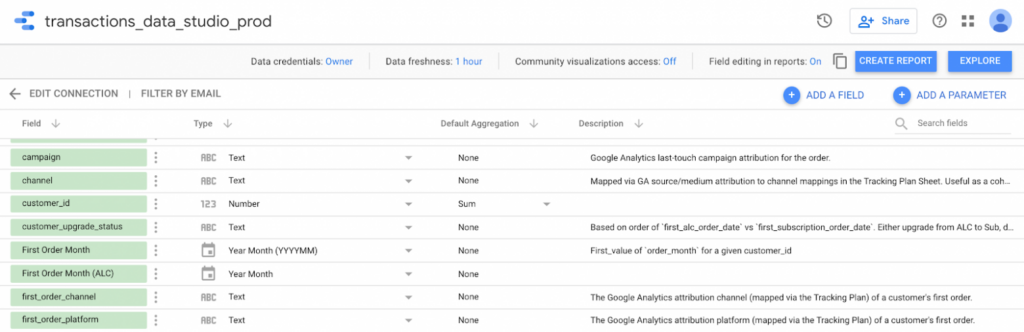
Інші сховища даних (Snowflake тощо) або інструменти візуалізації даних (Looker тощо) отримують описи цих таблиць і стовпців аналогічним чином. Тобто ви можете написати визначення полів один раз і запускати їх, де завгодно.
Як давно ви проходили тестування?
Коли робота аналітика виконана бездоганно, вона невидима для людей, яким допомагає ухвалювати рішення. А тестування допомагає роботі аналітика залишатися непомітною, даючи змогу уникнути проблем з якістю даних, які можуть підірвати довіру до неї.
dbt чудово справляється з цим завданням завдяки автоматизованій схемі та тестуванню даних.
Якщо стовпець ніколи не повинен бути нульовим, але якимось чином був обнулений, тести dbt відзначать це за вас. Якщо ваш JOIN занадто щедрий і призводить до дублювання рядків, тести dbt відзначать це за вас.
У принципі, ви можете написати будь-який SQL-запит як тест, і dbt видасть вам попередження або помилку.
Перехід на інше сховище даних
Будь-яке сховище даних – BigQuery, Snowflake або звичайна PostgreSQL – має свій власний, дещо відмінний синтаксис SQL. Якщо ви переходите з BigQuery на Snowflake або з Redshift на BigQuery, вам доведеться переписувати запити SQL, щоб врахувати ці нюанси.
Але dbt подбав про цю проблему! Він містить адаптери для всіх поширених платформ зберігання даних. Ви можете переносити свої моделі dbt для роботи в іншому сховищі даних з мінімальними модифікаціями. А оскільки dbt має відкритий вихідний код, ви можете додавати свої власні адаптери (як це зробили, наприклад, для MS SQL).
Нам у CIFL це суттєво полегшило життя, оскільки ми можемо працювати зі сховищами даних, яким надають перевагу наші клієнти, без серйозних змін у робочих процесах.
Як почати роботу з dbt
Якщо ви готові зайнятися впровадженням dbt у своїй команді, у цьому можуть допомогти:
- Безкоштовний курс “Початок роботи з BigQuery SQL“, який включає введення в моделювання даних за допомогою dbt.
- Нещодавно запущений курс “Побудуйте свою агенцію даних” для глибшого занурення в процес аналізу даних на основі dbt.
🚀Долучайтесь до нашої спільноти Telegram:
🚀Долучайтесь до нашої спільноти FaceBook:
🚀Долучайтесь до нашої спільноти Twiter X:


